java尚硅谷笔记
Java 基础 第 1 阶段:基本语法——尚硅谷学习笔记(含面试题) 2023 年
第 1 章 Java 语言概述
1.1 Java 基础阶段的学习内容
1.1.1 第 1 阶段:Java 基本语法
Java 概述、关键字、标识符、变量、运算符、流程控制(条件判断、选择结构、循环结构)、IDEA、数组。
1.1.2 第 2 阶段:Java 面向对象编程
- 类及类的内部成员。
- 面向对象的三大特征 :封装、继承、多态。
- 其它关键字的使用。
1.1.3 第 3 阶段:Java 语言的高级应用
异常处理、多线程、IO 流、集合框架、反射、网络编程、新特性、其它常用的 API 等。
书籍推荐:《Java 核心技术》、《Effective Java》、《Java 编程思想》。
1.2 软件开发相关内容
1.2.1 计算机的构成
硬件 + 软件。
1.2.2 软件
软件,即一系列按照特定顺序组织的计算机数据和指令的集合。有系统软件和应用软件之分。
- 系统软件,即操作系统,Windows、Mac OS 、Linux、Android、ios。
- 应用软件,即 OS 之上的应用程序。
1.2.3 人机交互方式
- 图形化界面(Graphical User Interface,GUI)。
- 命令行交互方式(Command Line Interface,CLI)。
熟悉常用的 DOS(Disk Operating System,磁盘操作系统)命令:
- 进入和回退
- 盘符名称:
盘符切换。E:回车,表示切换到 E 盘。 - dir
列出当前目录下的文件以及文件夹。 - cd 目录
进入指定目录。 - cd …
回退到上一级目录。 - cd \ 或 cd /
回退到盘符目录。
- 盘符名称:
- 增、删
- md 文件目录名
创建指定的文件目录。 - rd 文件目录名
删除指定的文件目录(如文件目录内有数据,删除失败)。
- md 文件目录名
- 其它
- cls
清屏。 - exit
退出命令提示符窗口。 - ↑ ↓
调阅历史操作命令。
- cls
1.2.4 计算机编程语言
- 语言的分代:
- 第 1 代:机器语言
- 第 2 代:汇编语言
- 第 3 代:高级语言
- 面向过程的语言:C
- 面向对象的语言:C++、Java、C#、Python、Go、JavaScript
没有“最好”的语言,只有在特定场景下相对来说,最适合的语言而已。
1.3 Java 概述
1.3.1 Java 发展史
- 几个重要的版本:1996 年,发布 JDK1.0
- 里程碑式的版本:JDK5.0、JDK8.0(2014 年发布)
- JDK11(LTS)、JDK17(LTS)long term support
1.3.2 Java 之父
詹姆斯·高斯林
1.3.3 Java 具体的平台划分
- J2SE ——> JavaSE(Java Standard Edition)标准版
- J2EE ——> JavaEE(Java Enterprise Edition)企业版
- J2ME ——> JavaME(Java Micro Edition)小型版
Java 目前主要的应用场景:JavaEE 后端开发、Android 客户端的开发、大数据开发。
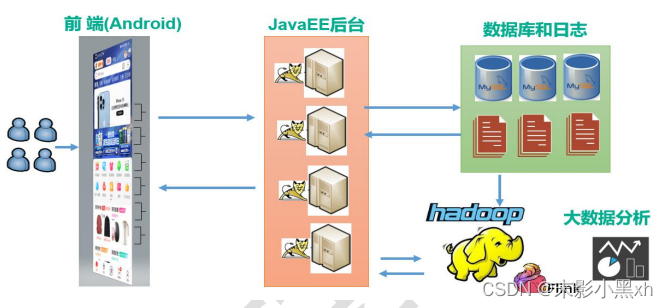
1.4. Java 环境的搭建
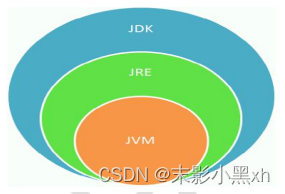
1.4.1 JDK、JRE、JVM 的基本概念
- JDK(Java Development Kit):是 Java 程序开发工具包,包含 JRE 和开发人员使用的工具。
- JRE(Java Runtime Environment) :是 Java 程序的运行时环境,包含 JVM 和运行时所需要的核心类库。
- Java 虚拟机(Java Virtual Machine 简称 JVM)是运行所有 Java 程序的抽象计算机,是 Java 语言的运行环境,它是 Java 最具吸引力的特性之一。
1.4.2 JDK、JRE、JVM 三者之间的关系
-
JDK = JRE + 开发工具集(例如 Javac 编译工具等)。
-
JRE = JVM + Java SE 标准类库。
1.4.3 安装 JDK
- JDK 的下载:Oracle 官网(https://www.oracle.com)
- JDK 的安装:
安装 jdk11 和 jdk17。 - 环境变量的配置:
配置 JAVA_HOME + path。
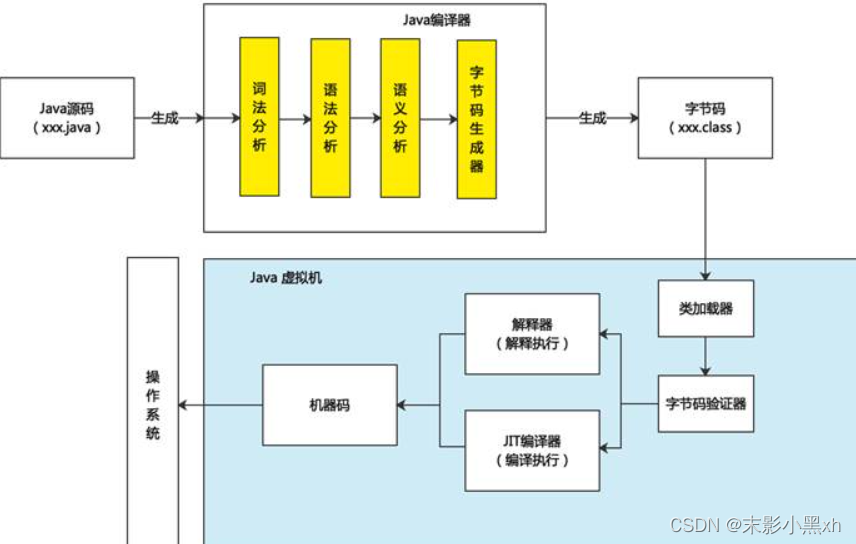
1.5. HelloWorld
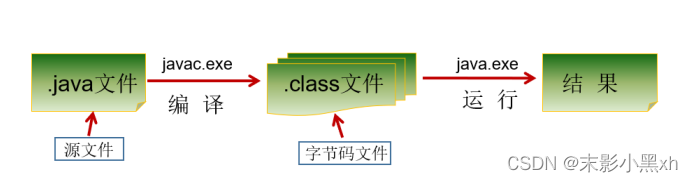
1.5.1 开发步骤
Java 程序开发三步骤:编写、编译、运行。
- 将 Java 代码编写到扩展名为 .java 的源文件中。
- 通过 javac.exe 命令对该 java 文件进行编译,生成一个或多个字节码文件。格式:javac 源文件名.java
- 通过 java.exe 命令对生成的 class 文件进行运行。格式: java 字节码文件名
1.5.2 开发说明
-
格式:
1
2
3
4
5
6
7类
{
方法
{
语句;
}
} -
代码:
1
HelloWorld.java
1
2
3
4
5
6
7class HelloWorld
{
public static void main(String[] args)
{
System.out.println("Hello World!");
}
} -
说明:
① class:关键字,表示“类”,后面跟着类名。
② main() 方法的格式是固定的。表示程序的入口。
③ Java 程序,是严格区分大小写的。
④ 从控制台输出数据的操作:
System.out.println() : 输出数据之后,会换行。
System.out.print() : 输出数据之后,不会换行。
⑤ 每一行执行语句必须以;结束。
⑥ 编译以后,会生成 1 个或多个字节码文件。每一个字节码文件对应一个 Java 类,并且字节码文件名与类名相同。
⑦ 我们是针对于字节码文件对应的 Java 类进行解释运行的。
⑧ 一个源文件中可以声明多个类,但是最多只能有一个类使用 public 进行声明,且要求声明为 public 的类的类名与源文件名相同。
1.6 注释
源文件中用于解释、说明程序的文字就是注释。
1.6.1 Java 中的注释的种类
单行注释、多行注释、文档注释(Java 特有)。
1.6.2 单行注释
1 | // 这是单行注释。 |
1.6.3 多行注释
1 | /* |
1.6.4 文档注释
1 | /** |
文档注释内容可以被 JDK 提供的工具 javadoc 所解析,生成一套以网页文件形式体现的该程序的说明文档。
1.7 API 文档
API (Application Programming Interface,应用程序编程接口)是 Java 提供的基本编程接口。
Java 语言提供了大量的基础类,因此 Oracle 也为这些基础类提供了相应的说明文档,用于告诉开发者如何使用这些类,以及这些类里包含的方法。
Java API 文档,即为 JDK 使用说明书、帮助文档。
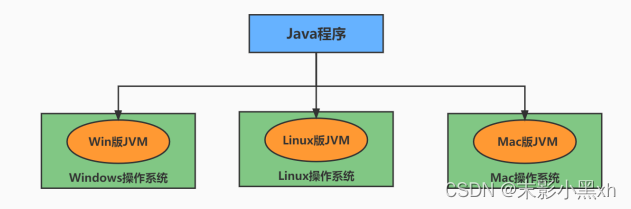
1.8 Java 核心机制:JVM
1.8.1 Java 语言的优点
- 跨平台性:
- 原理:只要在需要运行 java 应用程序的操作系统上,先安装一个 Java 虚拟机(JVM ,Java Virtual Machine) 即可,由 JVM 来负责 Java 程序在该系统中的运行。
- 面向对象性:
面向对象是一种程序设计技术,非常适合大型软件的设计和开发。面向对象编程支持封装、继承、多态等特性,让程序更好达到高内聚,低耦合的标准。 - 健壮性:
吸收了 C/C++ 语言的优点,但去掉了其影响程序健壮性的部分(如指针、内存的申请与释放等),提供了一个相对安全的内存管理和访问机制。- 安全性高:
Java 适合于网络/分布式环境,需要提供一个安全机制以防恶意代码的攻击。如:安全防范机制(ClassLoader 类加载器),可以分配不同的命空间以防替代本地的同名类、字节代码检查。
- 安全性高:
- 简单性:
Java 就是 C++ 语法的简化版,我们也可以将 Java 称之为“C++ - -”。比如:头文件,指针运算,结构,联合,操作符重载,虚基类等。- 高性能:
Java 最初发展阶段,总是被人诟病“性能低”;客观上,高级语言运行效率总是低于低级语言的,这个无法避免。Java 语言本身发展中通过虚拟机的优化提升了几十倍运行效率。比如,通过 JIT(JUST IN TIME)即时编译技术提高运行效率。
- 高性能:
1.8.2 Java 语言的缺点
- 语法过于复杂、严谨,对程序员的约束比较多,与 python、php 等相比入门较难。
- 一般适用于大型网站开发,整个架构会比较重,对于初创公司开发和维护人员的成本比较高。
- 并非适用于所有领域。比如,Objective C、Swift 在 iOS 设备上就有着无可取代的地位;浏览器中的处理几乎完全由 JavaScript 掌控;Windows 程序通常都用 C++或 C#编写;Java 在服务器端编程和跨平台客户端应用领域则很有优势。
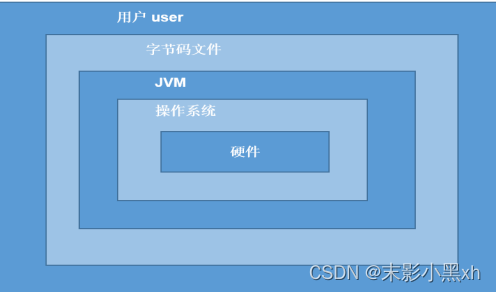
1.8.3 JVM 功能说明
JVM(Java Virtual Machine ,Java 虚拟机):是一个虚拟的计算机,是 Java 程序的运行环境。JVM 具有指令集并使用不同的存储区域,负责执行指令,管理数据、内存、寄存器。
-
功能 1:实现 Java 程序的跨平台性 。我们编写的 Java 代码,都运行在 JVM 之上。正是因为有了 JVM,才使得 Java 程序具备了跨平台性。
-
功能 2:自动内存管理(内存分配、内存回收)
- Java 程序在运行过程中,涉及到运算的数据的分配、存储等都由 JVM 来完成。
- Java 消除了程序员回收无用内存空间的职责。提供了一种系统级线程跟踪存储空间的分配情况,在内存空间达到相应阈值时,检查并释放可被释放的存储器空间。
- GC 的自动回收,提高了内存空间的利用效率,也提高了编程人员的效率,很大程度上减少了因为没有释放空间而导致的内存泄漏。
1.9 企业真题
-
一个“.java”源文件中是否可以包括多个类?有什么限制?
答:
一个源文件中可以声明多个类,但是最多只能有一个类使用 public 进行声明。
且要求声明为 public 的类的类名与源文件名相同。 -
Java 的优势有哪些?
答:跨平台型、安全性高、简单性、高性能、面向对象性、健壮性。 -
常用的几个命令行操作都有哪些?
答:
① 盘符名称:
盘符切换。E:回车,表示切换到 E 盘。
② dir
列出当前目录下的文件以及文件夹。
③ cd 目录
进入指定目录。
④ cd …
回退到上一级目录。
⑤ cd \ 或 cd /
回退到盘符目录。
⑥ md 文件目录名
创建指定的文件目录。
⑦ rd 文件目录名*
删除指定的文件目录(如文件目录内有数据,删除失败)。
⑧ cls
清屏。
⑨ exit
退出命令提示符窗口。
⑩ ↑ ↓
调阅历史操作命令。 -
Java 中是否存在内存溢出、内存泄漏?如何解决?举例说明。
答:Java 中存在内存溢出和内存泄漏问题。内存溢出指的是程序申请的内存超出了 JVM 所能分配的内存大小,导致程序崩溃。解决方法包括:
① 增加 JVM 内存限制:通过修改 JVM 启动参数,增加内存限制,例如 -Xmx。
② 优化代码:检查代码中是否存在大量的无用对象或者内存泄漏,及时释放资源。
③ 分析内存使用情况:使用工具分析内存使用情况,找到内存占用过多的地方,及时优化。
内存泄漏指的是程序中的对象在使用完毕后没有及时释放,导致内存占用不断增加。解决方法包括:
① 手动释放资源:在代码中手动释放资源,例如关闭文件、数据库连接等。
② 使用 try-with-resources:使用 try-with-resources 管理资源,确保资源被及时释放。
③ 检查代码:检查代码中是否存在内存泄漏的地方,及时优化。例如,如果在循环中创建对象并没有及时释放,就会导致内存泄漏。 -
如何看待 Java 是一门半编译半解释型的语言?
答:Java 是一门半编译半解释型的语言,这意味着 Java 具有一定的优点和缺点。优点:
① 跨平台性强:Java 的半编译半解释型特性使得它能够在不同的操作系统上运行,只需在不同平台上安装 Java 虚拟机即可。
② 安全性高:Java 的编译过程中会进行严格的类型检查和边界检查,减少了程序出错的可能性,同时 Java 还具有内存自动管理机制,防止了一些常见的安全漏洞。
③ 灵活性好:Java 的半编译半解释型特性使得它能够在运行时进行动态加载和更新,增强了程序的灵活性。
缺点:
① 执行效率低:由于 Java 是半编译半解释型的语言,需要在运行时进行解释和编译,导致执行效率较低。
② 内存占用大:Java 在运行时需要加载虚拟机和类库,占用的内存较大。
③ 资源消耗多:Java 的编译和解释过程需要占用较多的 CPU 和内存资源,对于一些资源受限的设备来说可能会造成困扰。综上所述,Java 的半编译半解释型特性使得它具有跨平台性和安全性等优点,但也存在执行效率低、内存占用大和资源消耗多等缺点。在实际应用中需要根据具体情况进行权衡和选择。
第 2 章 变量与运算符
2.1 关键字、保留字
- 关键字:被 Java 赋予特殊含义的字符串。
官方规范中有 50 个关键字,true、false、null 虽然不是关键字,但是可以当做关键字来看待。 - 保留字:goto、const
2.2 标识符
标识符:凡是可以自己命名的地方,都是标识符。
比如:类名、变量名、方法名、接口名、包名、常量名等。
标识符命名的规则:
- 由 26 个英文字母大小写,0 - 9,或 $ 组成。
- 数字不可以开头。
- 不可以使用关键字和保留字,但能包含关键字和保留字。
- Java 中严格区分大小写,长度无限制。
- 标识符不能包含空格。
标识符命名的规范:
- 包名:多个单词组成时所有字母都小写,
例如:java.lang、com.MYXH.bean - 类名、接口名:多个单词组成时,所有单词的首字母大写,例如:HelloWorld,String,System 等。
- 变量名、方法名:多个单词组成时,第一个单词首字母小写,第二个单词开始每个单词首字母大写,例如:age, name, bookName, main, binarySearch, getName 等。
- 常量名:所有字母都大写。多单词时每个单词用下划线连接,例如:MAX_VALUE, PI, DEFAULT_CAPACITY 等。
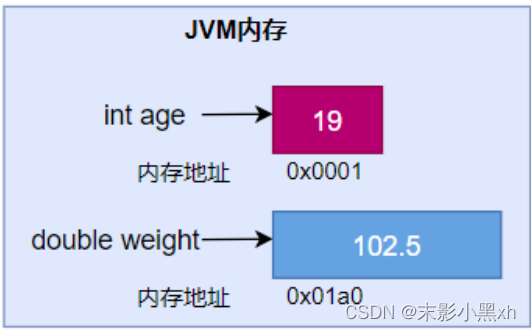
2.3 变量
变量的概念:内存中的一个存储区域,该区域的数据可以在同一类型范围内不断变化。
变量的构成包含三个要素:数据类型、变量名、存储的值。
Java 中变量声明的格式:数据类型 变量名 = 变量值
代码:
1 | // 定义变量的方式1: |
说明:
定义变量时,变量名要遵循标识符命名的规则和规范。
① 变量都有其作用域。变量只在作用域内是有效的,出了作用域就失效了。
② 在同一个作用域内,不能声明两个同名的变量。
③ 定义好变量以后,就可以通过变量名的方式对变量进行调用和运算。
④ 变量值在赋值时,必须满足变量的数据类型,并且在数据类型有效的范围内变化。
变量的内存结构如图:
2.4 基本数据类型
2.4.1 基本数据类型
- 整型:byte、short、int、long
- 浮点型:float、double
- 字符型:char
- 布尔型:boolean
2.4.2 引用数据类型
- 类(class)
- 数组(array)
- 接口(interface)
- 枚举(enum)
- 注解(annotation)
- 记录(record)
如果在开发中,需要极高的精度,需要使用 BigDecimal 类替换浮点型变量。
2.5 基本数据类型变量间的运算规则
2.5.1 自动类型提升
规则:将取值范围小(或容量小)的类型自动提升为取值范围大(或容量大)的类型 。
2.5.2 强制类型转换
规则:
- 如果需要将容量大的变量的类型转换为容量小的变量的类型,需要使用强制类型转换。
- 强制类型转换需要使用强转符:()。在()内指明要转换为的数据类型。
- 强制类型转换过程中,可能导致精度损失。
2.6 基本数据类型与 String 的运算
2.6.1 字符串类型:String
String 类,属于引用数据类型,俗称字符串。
String 类型的变量,可以使用一对""的方式进行赋值。
String 声明的字符串内部,可以包含 0 个,1 个或多个字符。
2.6.2 运算规则
- String 与基本数据类型变量间只能做连接运算,使用“+”表示。
- 运算的结果是 String 类型。
- String 类型不能通过强制类型()转换,转为其他的类型。
2.7 进制的认识
2.7.1 进制的分类
二进制(以 0B、0b 开头)、十进制、八进制(以 0 开头)、十六进制(以 0x 或 0X 开头)。
2.7.2 二进制的理解
- 正数:原码、反码、补码三码合一。
- 负数:原码、反码、补码不相同。了解三者之间的关系。
- 负数的原码:把十进制转为二进制,然后最高位设置为 1。
- 负数的反码:在原码的基础上,最高位不变,其余位取反(0 变 1,1 变 0)。
- 负数的补码:反码 + 1。
- 计算机数据的存储使用二进制补码形式存储,并且最高位是符号位。
- 正数:最高位是 0。
- 负数:最高位是 1。
- 熟悉:二进制与十进制之间的转换。
- 了解:二进制与八进制、十六进制间的转换。
2.8 运算符
运算符是一种特殊的符号,用以表示数据的运算、赋值和比较等。
- 运算符的分类:
- 按照功能分为:算术运算符、赋值运算符、比较(或关系)运算符、逻辑运算符、位运算
符、条件运算符、Lambda 运算符。 - 按照操作数个数分为:一元运算符(单目运算符)、二元运算符(双目运算符)、三元运算符 (三目运算符)。
- 按照功能分为:算术运算符、赋值运算符、比较(或关系)运算符、逻辑运算符、位运算
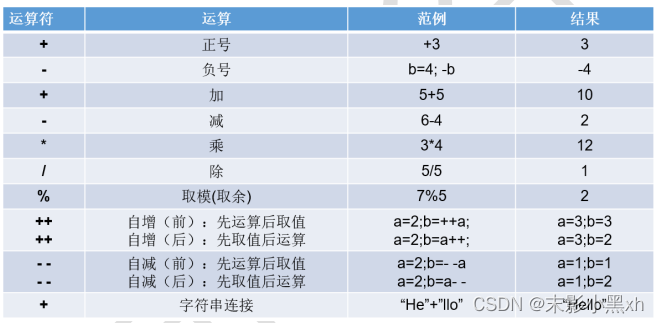
2.8.1 算术运算符
2.8.2 赋值运算符
- 符号:=
- 当“=”两侧数据类型不一致时,可以使用自动类型转换或使用强制类型转换原则进行处理。
- 支持连续赋值。
- 扩展赋值运算符: +=、 -=、*=、 /=、%=
2.8.3 比较(关系)运算符
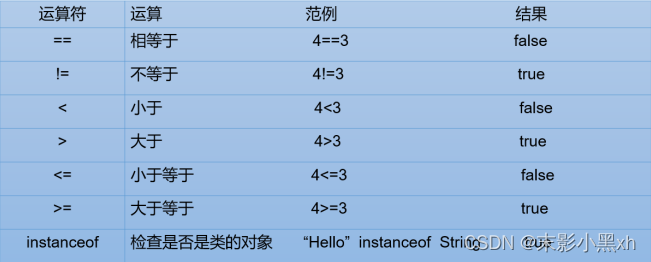
2.8.4 逻辑运算符
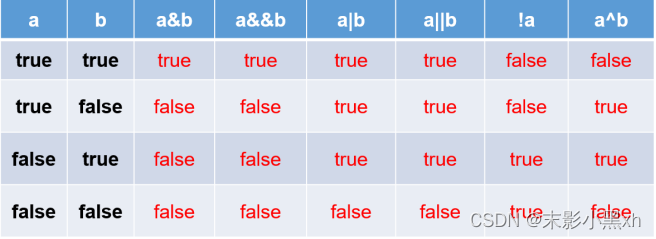
逻辑运算符,操作的都是 boolean 类型的变量或常量,而且运算得结果也是 boolean 类型的值。
- 运算符说明:
- & 和 &&:表示"且"关系,当符号左右两边布尔值都是 true 时,结果才能为 true。否则,为 false。
- | 和 ||:表示"或"关系,当符号两边布尔值有一边为 true 时,结果为 true。当两边都为 false 时,结果为 false。
- !:表示"非"关系,当变量布尔值为 true 时,结果为 false。当变量布尔值为 false 时,结果为 true。
- ^:当符号左右两边布尔值不同时,结果为 true。当两边布尔值相同时,结果为 false。
理解:异或,追求的是“异”!
2.8.5 位运算符
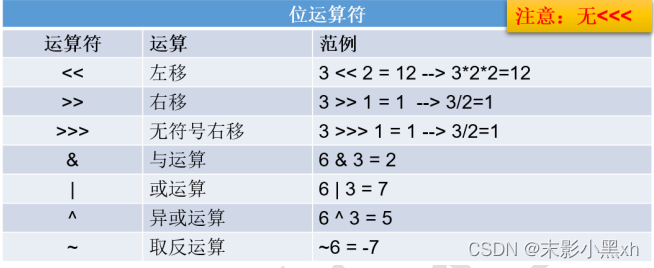
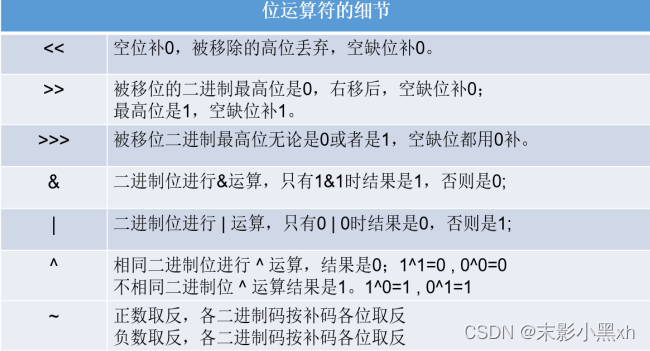
- 左移:<<
运算规则:在一定范围内,数据每向左移动一位,相当于原数据 * 2。 - 右移:>>
运算规则:在一定范围内,数据每向右移动一位,相当于原数据 / 2。
2.8.6 条件运算符
- 条件运算符格式:(条件表达式)? 表达式 1 : 表达式 2
- 说明:
① 条件表达式的结果是 boolean 类型。
② 如果条件表达式的结果是 true,则执行表达式 1。否则,执行表达式 2。
③ 表达式 1 和表达式 2 需要是相同的类型或能兼容的类型。
2.8.7 运算符的优先级
- 如果想体现优先级比较高,使用()
- 我们在编写一行执行语句时,不要出现太多的运算符。
2.8.8 字符集
- 编码与解码:
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。 - 字符编码(Character Encoding):就是一套自然语言的字符与二进制数之间的对应规则。
- 字符集:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符
号、图形符号、数字等。 - ASCII 码、ISO-8859-1 字符集、GBxxx 字符集、Unicode 码、UTF-8。
2.9 企业真题
-
怎么高效计算 2 * 8 的值?
答:
2 << 3 或 8 << 2 -
&和&&的区别?
答:
区分“&”和“&&”:
相同点:如果符号左边是 true,则二者都执行符号右边的操作。不同点:
& : 如果符号左边是 false,则继续执行符号右边的操作。
&& :如果符号左边是 false,则不再继续执行符号右边的操作(短路与)。
建议:开发中,推荐使用 &&。 -
Java 中的基本类型有哪些?String 是最基本的数据类型吗?
答:
基本数据类型(8 种)。
整型:byte、short、int、long
浮点型:float、double
字符型:char
布尔型:boolean
String 类,属于引用数据类型,俗称字符串。 -
Java 开发中计算金额时使用什么数据类型?
答:
不能使用 float 或 double,因为精度不高。
使用 BigDecimal 类替换,可以实现任意精度的数据的运算。 -
char 型变量中能不能存储一个中文汉字,为什么?
答:
可以。char c1 = ‘中’;char c2 = ‘a’。
因为 char 使用的是 unicode 字符集,包含了世界范围的所有的字符。 -
代码分析。
1
2
3
4short s1=1;
s1=s1+1; // 有什么错? 答:= 右边是 int 类型,需要强转。
short s1=1;
s1+=1; //有什么错? 答:没错。 -
int i = 0; i = i++ 执行这两句话后,变量 i 的值为?
答:
变量 i 的值为 0。 -
如何将两个变量的值互换?
String s1 = “abc”;
String s2 = “123”;
答:1
2
3String temp = s1;
s1 = s2;
s2 = temp; -
boolean 占几个字节?
答:
在编译时不谈占几个字节。
但是 JVM 在给 boolean 类型分配内存空间时,boolean 类型的变量占据一个槽位(slot,等于 4 个字节)。
细节:true:1 false:0拓展:
在内存中,byte、short、char、boolean、int、float : 占用 1 个 slot。
double、long :占用 2 个 slot。 -
为什么 Java 中 0.1 + 0.2 结果不是 0.3?
在代码中测试 0.1 + 0.2,你会惊讶的发现,结果不是 0.3,而是 0.3000……4。这是为什么?
答:
几乎所有现代的编程语言都会遇到上述问题,包括 JavaScript、Ruby、Python、Swift 和 Go 等。引发这个问题的原因是,它们都采用了 IEEE 754 标准。
IEEE 是指“电气与电子工程师协会”,其在 1985 年发布了一个 IEEE 754 计算标准,根据这个标准,小数的二进制表达能够有最大的精度上限提升。但无论如何,物理边界是突破不了的,它仍然不能实现“每一个十进制小数,都对应一个二进制小数”。正因如此,产生了 0.1 + 0.2 不等于 0.3 的问题。具体的:
整数变为二进制,能够做到“每个十进制整数都有对应的二进制数”,比如数字 3,二进制就是 11;再比如,数字 43 就是二进制 101011,这个毫无争议。
对于小数,并不能做到“每个小数都有对应的二进制数字”。举例来说,二进制小数 0.0001 表示十进制数 0.0625 (至于它是如何计算的,不用深究);二进制小数 0.0010 表示十进制数 0.125;二进制小数 0.0011 表示十进制数 0.1875。看,对于四位的二进制小数,二进制小数虽然是连贯的,但是十进制小数却不是连贯的。比如,你无法用四位二进制小数的形式表示 0.125 ~ 0.1875 之间的十进制小数。
所以在编程中,遇见小数判断相等情况,比如开发银行、交易等系统,可以采用四舍五入或者“同乘同除”等方式进行验证,避免上述问题。
第 3 章 流程控制语句
3.1 流程控制结构
- 顺序结构
- 分支结构
- if-else
- switch-case
- 循环结构
- for
- while
- do-while
3.2 分支结构之一:if-else
在程序中,凡是遇到了需要使用分支结构的地方,都可以考虑使用 if-else。
3.2.1 基本语法
-
结构 1:单分支条件判断:if
1
2
3
4if(条件表达式)
{
语句块;
} -
结构 2:双分支条件判断:if…else
1
2
3
4
5
6
7
8if(条件表达式)
{
语句块 1;
}
else
{
语句块 2;
} -
结构 3:多分支条件判断:if…else if…else
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20if (条件表达式 1)
{
语句块 1;
}
else if (条件表达式 2)
{
语句块 2;
}
...
}
else if (条件表达式 n)
{
语句块 n;
}
else
{
语句块 n+1;
}
3.3 分支结构之二:switch-case
在特殊的场景下,分支结构可以考虑使用 switch-case。
3.3.1 基本语法
分支结构之 switch-case
1 | switch(表达式) |
3.3.2 case 的穿透性
在 switch 语句中,如果 case 的后面不写 break,将出现穿透现象,也就是一旦匹配成功,不会在判断下一个 case 的值,直接向后运行,直到遇到 break 或者整个 switch 语句结束,执行终止。
3.4 循环结构之一:for
凡是循环结构,都有 4 个要素:
① 初始化条件
② 循环条件(是 boolean 类型)
③ 循环体
④ 迭代条件
3.4.1 基本语法
循环结构之一:for 循环
1 | for(① 初始化条件;② 循环条件;④ 迭代条件) |
说明:
- 我们可以在循环结构中使用 break。一旦执行 break,就跳出(或结束)当前循环结构。
- 如何结束一个循环结构?
- 方式 1:循环条件不满足。(即循环条件执行完以后是 false)
- 方式 2:在循环体中执行了 break。
- 如果一个循环结构不能结束,那就是一个死循环!我们开发中要避免出现死循环。
3.5 循环结构之二:while
凡是循环结构,就一定会有 4 个要素:
① 初始化条件
② 循环条件(是 boolean 类型)
③ 循环体
④ 迭代部分
3.5.1 基本语法
循环结构之一:while 循环
1 | ① 初始化条件 |
3.6 循环结构之三:do-while
凡是循环结构,就一定会有 4 个要素:
① 初始化条件
② 循环条件(是 boolean 类型)
③ 循环体
④ 迭代部分
3.6.1 基本语法
循环结构之一:do-while 循环
1 | ① 初始化条件 |
3.7 “无限”循环
3.7.1 基本语法
1 | while(true) {} 或 for(;;) {} |
-
开发中,有时并不确定需要循环多少次,需要根据循环体内部某些条件,来控制循环的结束(使用 break)。
-
如果此循环结构不能终止,则构成了死循环!开发中要避免出现死循环。
3.8 关键字 break、continue
break 和 continue 关键字的使用
- 使用范围:在循环结构中的作用
- 相同点:
- break:循环结构中结束(或跳出)当前循环结构。
- continue:循环结构中结束(或跳出)当次循环 。
3.9 Scanner 类的使用
如何从键盘获取不同类型(基本数据类型、String 类型)的变量:使用 Scanner 类。
键盘输入代码的四个步骤:
① 导包:import java.util.Scanner;
② 创建 Scanner 类型的对象:Scanner scan = new
Scanner(System.in);
③ 调用 Scanner 类的相关方法(next()、nextXxx()),来获取指定类型的变量。
④ 释放资源:scan.close();
3.10 获取随机数
如何获取一个随机数?
① 可以使用 Java 提供的 API:Math 类的 random() 。
② random() 调用以后,会返回一个[0.0,1.0)范围的 double 型的随机数。
3.11 企业真题
-
break 和 continue 的作用?
答:
使用范围:在循环结构中的作用。相同点:
break:循环结构中结束(或跳出)当前循环结构。
continue:循环结构中结束(或跳出)当次循环 -
if 分支语句和 switch 分支语句的异同之处?
答:
if-else 语句优势:
if 语句的条件是一个布尔类型值,if 条件表达式为 true 则进入分支,可以用于范围的判断,也可以用于等值的判断,使用范围更广。
switch 语句的条件是一个常量值(byte、short、int、char、枚举、String),只能判断某个变量或表达式的结果是否等于某个常量值,使用场景较狭窄。switch 语句优势:
当条件是判断某个变量或表达式是否等于某个固定的常量值时,使用 if 和 switch 都可以,习惯上使用 switch 更多。因为效率稍高。
当条件是区间范围的判断时,只能使用 if 语句。
使用 switch 可以利用穿透性,同时执行多个分支,而 if-else 没有穿透性。 -
switch 语句中忘写 break 会发生什么?
答:
如果在 switch 语句中忘记写 break,程序将会继续执行下一个 case 语句,直到遇到 break 或者 switch 语句结束。这种情况被称为“穿透”(fall-through),因为程序“穿透”了一个 case 语句并继续执行下一个 case 语句。这可能会导致程序出现意外行为,因为程序可能会执行不应该执行的代码。因此,在编写 switch 语句时,应该始终记得写上 break 来避免出现这种情况。 -
Java 支持哪些类型循环?
答:
for;while;do-while;
增强 for 循环(for-each)。 -
while 和 do while 循环的区别?
答:
while 循环和 do while 循环都是用于重复执行某个代码块的结构,但它们之间存在一些区别:
① while 循环是先判断条件是否成立,再决定是否执行循环体,如果条件不成立,则一次都不执行;而 do while 循环是先执行一次循环体,再判断条件是否成立,所以至少会执行一次循环体。
② while 循环的循环体可能一次都不执行,因为条件不成立;而 do while 循环的循环体至少会执行一次。
③ while 循环是入口判断循环,即在循环开始前就判断条件是否成立;而 do while 循环是出口判断循环,即在循环结束后判断条件是否成立。
④ 在循环条件不成立的情况下,while 循环不会执行循环体,而 do while 循环会执行一次循环体。总的来说,while 循环适合在条件不成立时不需要执行循环体的情况下使用;而 do while 循环适合在至少需要执行一次循环体的情况下使用。
第 4 章 IDEA 的安装与使用
4.1 IDEA 的认识
- IDEA(集成功能强大、符合人体工程学)
- Eclipse
4.2 IDEA 的下载、安装、卸载
- 卸载:使用控制面板进行卸载,注意删除 C 盘指定目录下的两个文件目录:jetbrains。
- 下载:从官网IDEA 官网https://www.jetbrains.com/进行下载:旗舰版。
- 安装:傻瓜式的安装、注册。
4.3 工程结构
- project(工程)、module(模块)、package(包)、package(包)等概念。
- 掌握:如何创建工程、如何创建模块、如何导入其他项目中的模块、如何创建包、如何创建类、如何运行。
4.4 企业真题
-
开发中你接触过的开发工具都有哪些?
答:
IDEA、Visual Studio Code、Eclipse。 -
谈谈你对 Eclipse 和 IDEA 使用上的感受?
答:
IDEA 集成功能强大、符合人体工程学,Eclipse 不够人性化。
第 5 章:数组
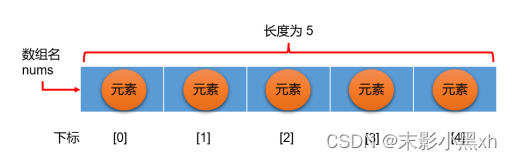
5.1 数组的概述
数组(Array):就可以理解为多个数据的组合。
程序中的容器:数组、集合框架(List、Set、Map)。
数组中的概念:
- 数组名
- 下标(或索引)
- 元素
- 数组的长度
数组存储的数据的特点:
- 依次紧密排列的、有序的、可以重复的。
- 数组的其它特点:
- 一旦初始化,其长度就是确定的、不可更改的。
5.2 一维数组
5.2.1 数组的声明和初始化
代码示例:
1 | int[] arr1 = new int[10]; |
5.2.2 数组的使用
- 调用数组的指定元素:使用角标、索引、index。
- index 从 0 开始。
- 数组的属性:length,表示数组的长度。
- 数组的遍历。
- 数组元素的默认初始化值。
5.2.3 一维数组内存分析
-
虚拟机栈:main() 作为一个栈帧,压入栈空间中。在 main() 栈帧中,存储着 arr 变量。arr 记录着数组实体的首地址值。
-
堆:数组实体存储在堆空间中。
-
Java 虚拟机的内存划分:
5.3 二维数组
二维数组本质上是元素类型是一维数组的一维数组。
5.4 数组的常用算法
- 数值型数组的特征值的计算:最大值、最小值、总和、平均值等。
- 数组元素的赋值。
- 数组的复制、赋值。
- 数组的反转。
- 数组的扩容、缩容。
- 数组的查找:
- 线性查找。
- 二分法查找(前提:数组有序)。
- 数组的排序:
- 冒泡排序(最简单)。
- 快速排序(最常用)。
5.5 Arrays 工具类的使用
- java.util.Arrays 类即为操作数组的工具类,包含了用来操作数组(比如排序和搜索)的各种方法。
- toString() 、 sort()、 binarySearch()。
5.6 数组中的常见异常
- 下标越界异常:ArrayIndexOutOfBoundsException
- 空指针异常:NullPointerException
5.7、企业真题
-
数组有没有 length()这个方法? String 有没有 length()这个方法?
答:
数组没有 length(),有 length 属性。
String 有 length()。 -
有数组 int[] arr,用 Java 代码将数组元素顺序颠倒?
答:
可以使用两个指针,一个指向数组的第一个元素,另一个指向数组的最后一个元素,交换它们的值,然后继续向中间靠拢,直到两个指针相遇。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public static void reverseArray(int[] arr)
{
int left = 0;
int right = arr.length - 1;
while (left < right)
{
int temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
left++;
right--;
}
}
public static void main(String[] args)
{
int[] arr = {1, 2, 3, 4, 5}; // 定义一个数组
System.out.println("原数组:" + Arrays.toString(arr)); // 输出原数组
reverseArray(arr); // 调用方法将数组元素顺序颠倒
System.out.println("颠倒后的数组:" + Arrays.toString(arr)); // 输出颠倒后的数组
}运行该主函数,输出结果如下:
1
2原数组:[1, 2, 3, 4, 5]
颠倒后的数组:[5, 4, 3, 2, 1] -
为什么数组要从 0 开始编号,而不是 1?
答:
数组的索引,表示了数组元素距离首地址的偏离量。因为第 1 个元素的地址与首地址相同,所以偏移量就是 0,所以数组要从 0 开始。 -
数组有什么排序的方式,手写一下?
答:
常见的数组排序方式有冒泡排序、选择排序、插入排序、快速排序、归并排序等。冒泡排序:
冒泡排序的思路是从第一个元素开始,依次比较相邻的两个元素,如果前一个元素比后一个元素大,则交换它们的位置。这样一轮下来,最大的元素就会被移动到最后一个位置。然后再从第一个元素开始,继续进行比较和交换,直到所有元素都被排序。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32public class BubbleSort
{
public static void main(String[] args)
{
int[] arr = {3, 9, 1, 8, 2, 5, 7};
bubbleSort(arr);
for(int i = 0; i < arr.length; i++)
{
System.out.print(arr[i] + " ");
}
}
public static void bubbleSort(int[] arr)
{
int n = arr.length;
for(int i = 0; i < n - 1; i++)
{
for(int j = 0; j < n - i - 1; j++)
{
if(arr[j] > arr[j + 1])
{
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
}冒泡排序的时间复杂度为 O(n^2),空间复杂度为 O(1)。
快速排序:
快速排序的思路是选取一个基准元素,将数组分为左右两部分,左半部分的元素均小于等于基准元素,右半部分的元素均大于等于基准元素。然后对左右两部分分别进行快速排序,直到整个数组有序。在上面的代码中,partition 方法用于实现分区,将数组分为左右两部分。quickSort 方法用于实现快速排序,递归调用自身对左右两部分进行排序。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51public class QuickSort
{
public static void main(String[] args)
{
int[] arr = {5, 2, 9, 3, 7, 6, 1, 8, 4};
quickSort(arr, 0, arr.length - 1);
for (int i : arr)
{
System.out.print(i + " ");
}
}
public static void quickSort(int[] arr, int left, int right)
{
if (left < right)
{
int pivot = partition(arr, left, right);
quickSort(arr, left, pivot - 1);
quickSort(arr, pivot + 1, right);
}
}
public static int partition(int[] arr, int left, int right)
{
int pivot = arr[left];
while (left < right)
{
while (left < right && arr[right] >= pivot)
{
right--;
}
arr[left] = arr[right];
while (left < right && arr[left] <= pivot)
{
left++;
}
arr[right] = arr[left];
}
arr[left] = pivot;
return left;
}
}快速排序的时间复杂度为 O(nlogn),空间复杂度为 O(logn)。
-
二分算法实现数组的查找?
答:
二分查找思路:
① 首先确定要查找的数组的范围,即左右边界;
② 计算中间位置,即中间索引值;
③ 判断中间值是否等于要查找的值,如果是,则返回中间索引值;
④ 如果中间值大于要查找的值,则在左半部分继续查找,即将右边界设为中间索引值减一;
⑤ 如果中间值小于要查找的值,则在右半部分继续查找,即将左边界设为中间索引值加一;
⑥ 重复 ②-⑤ 步骤,直到找到要查找的值或左右边界重合,此时返回-1 表示未找到。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44public class BinarySearch
{
public static int binarySearch(int[] arr, int key)
{
int low = 0;
int high = arr.length - 1;
while (low <= high)
{
int mid = (low + high) / 2;
if (key < arr[mid])
{
high = mid - 1;
}
else if (key > arr[mid])
{
low = mid + 1;
}
else
{
return mid;
}
}
return -1;
}
public static void main(String[] args)
{
int[] arr = {1, 3, 5, 7, 9};
int key = 3;
int index = binarySearch(arr, key);
if (index == -1)
{
System.out.println("找不到指定的元素");
}
else
{
System.out.println("指定元素的索引为:" + index);
}
}
}复杂度分析:
时间复杂度为 O(log n),因为每次查找都将查找范围缩小一半,最坏情况下需要查找 log n 次,其中 n 为数组长度。
空间复杂度为 O(1),因为只需要常数个额外变量存储查找范围的左右边界和中间索引值。 -
怎么求数组的最大子序列和?
答:
以下是一个使用 Java 实现的求解最大子序列和的示例代码:这个算法的思路是使用动态规划的思想。
我们从左到右遍历整个数组,使用两个变量 maxSum 和 currentSum 来记录最大子序列和和当前子序列和。
对于当前遍历到的元素 nums[i],我们可以有两种选择:
将 nums[i] 加入当前子序列中,即 currentSum = currentSum + nums[i];
以 nums[i] 作为新的起点开始一个新的子序列,即 currentSum = nums[i]。我们需要比较这两种选择哪个更优,即选择 currentSum + nums[i] 或选择 nums[i] 中的较大值作为当前子序列的和 currentSum。同时,我们需要比较当前子序列的和 currentSum 和最大子序列和 maxSum 哪个更大,即选择 Math.max(maxSum, currentSum)作为新的最大子序列和 maxSum。
最后,遍历完成后 maxSum 就是最大子序列和。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public class MaxSubArraySum
{
public static int maxSubArraySum(int[] nums)
{
int maxSum = nums[0];
int currentSum = nums[0];
for (int i = 1; i < nums.length; i++)
{
currentSum = Math.max(currentSum + nums[i], nums[i]);
maxSum = Math.max(maxSum, currentSum);
}
return maxSum;
}
public static void main(String[] args)
{
int[] nums = {-2, 1, -3, 4, -1, 2, 1, -5, 4};
int maxSum = maxSubArraySum(nums);
System.out.println("最大子序列和为:" + maxSum);
}
}输出:
1
最大子序列和为:6
解释:最大子序列为[4, -1, 2, 1],和为 6。
-
Arrays 类的排序方法是什么?如何实现排序的?
答:
Arrays 类提供了多种排序方法,包括:
① sort(Object[] a):对数组 a 进行升序排序,元素类型必须实现 Comparable 接口。
② sort(Object[] a, Comparator c):对数组 a 进行排序,使用自定义的 Comparator 比较器进行比较。
③ parallelSort(Object[] a):对数组 a 进行并行排序,效率更高。排序的实现原理主要是基于快速排序和归并排序,具体实现方式根据元素类型和排序方法不同而不同。
在 sort(Object[] a) 方法中,对于实现了 Comparable 接口的元素类型,通过 compareTo() 方法进行比较,并且使用快速排序实现;对于未实现 Comparable 接口的元素类型,则会抛出 ClassCastException 异常。
在 sort(Object[] a, Comparator c) 方法中,通过传入自定义的 Comparator 比较器进行比较,也使用快速排序实现。
在 parallelSort(Object[] a) 方法中,使用 Fork/Join 框架实现并行排序,将数组拆分成多个小数组进行排序,最后再合并起来。
Java 基础 第 2 阶段:面向对象编程——尚硅谷学习笔记(含面试题) 2023 年
第 6 章 面向对象——基础
6.1 面向过程 vs 面向对象
- 不管是面向过程、面向对象,都是程序设计的思路。
- 面向过程(Process Oriented Programming,简称 POP):以函数为基本单位,适合解决简单问题。
- 面向对象( Object Oriented Programming),简称 OOP):以类为基本单位,适合解决复杂问题。
6.2 类、对象
6.2.1 类
类:具有相同特征的事物的抽象描述,是抽象的、概念上的定义。
6.2.2 对象
对象:实际存在的该类事物的每个个体,是具体的,因而也称为实例。
面向对象完成具体功能的操作的三步流程:
- 步骤 1:创建类,并设计类的内部成员(属性、方法)。
- 步骤 2:创建类的对象。如:Phone p1 = new Phone()。
- 步骤 3:通过对象,调用其内部声明的属性或方法,完成相关的功能。
匿名对象 (anonymous object):
- 我们也可以不定义对象的句柄,而直接调用这个对象的方法。这样的对象叫做匿名对象。
- 如:new Person().shout();
- 使用情况:
- 如果一个对象只需要进行一次方法调用,那么就可以使用匿名对象。
- 我们经常将匿名对象作为实参传递给一个方法调用。
6.2.3 对象的内存解析
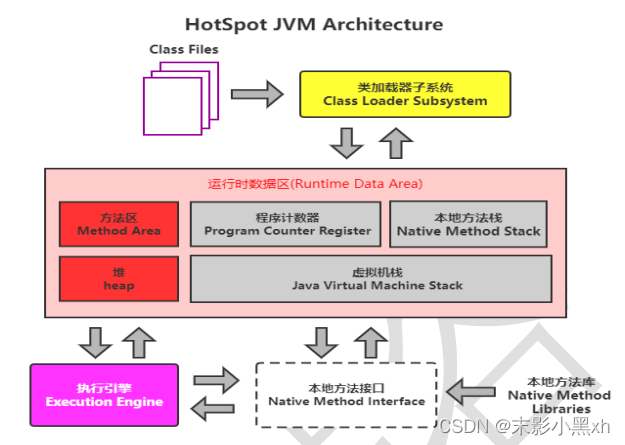
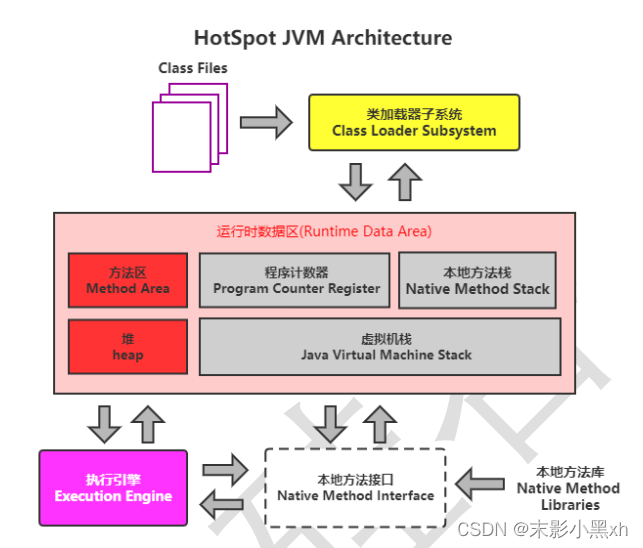
-
Java 中内存结构划分为:虚拟机栈、堆、方法区;程序计数器、本地方法栈。
-
虚拟机栈:以栈帧为基本单位,有入栈和出栈操作;每个栈帧入栈操作对应一个方法的执行;方法内的局部变量会存储在栈帧中。
-
堆空间:new 出来的结构(数组、对象):
① 数组,数组的元素在堆中
② 对象的成员变量在堆中。 -
方法区:加载的类的模板结构。
6.3 类的成员之一:属性(成员变量 field)
6.3.1 声明成员变量
语法格式:
1 | 修饰符 class 类名 |
代码示例:
1 | public class Person |
6.3.2 成员变量 vs 局部变量
- 在方法体外,类体内声明的变量称为成员变量。
- 在方法体内部等位置声明的变量称为局部变量。

- 不同点:
- 内存中存储的位置
① 成员变量:堆 。
② 局部变量:栈。 - 生命周期
① 成员变量:和对象的生命周期一样,随着对象的创建而存在,随着对象被 GC 回收而消亡, 而且每一个对象的实例变量是独立的。
② 局部变量:和方法调用的生命周期一样,每一次方法被调用而在存在,随着方法执行的结束而消亡, 而且每一次方法调用都是独立。 - 作用域
① 实例变量:通过对象就可以使用,本类中直接调用,其他类中“对象.实例变量” 。
② 局部变量:出了作用域就不能使用。
- 内存中存储的位置
6.4 类的成员之二:方法(method)
方法(method、函数)的理解:
- 方法是类或对象行为特征的抽象,用来完成某个功能操作。在某些语言中也称为函数或过
程。 - 将功能封装为方法的目的是,可以实现代码重用,减少冗余,简化代码。
- Java 里的方法不能独立存在,所有的方法必须定义在类里。
6.4.1 方法的声明
语法格式:
1 | 修饰符 返回值类型 方法名(形参列表) throws 异常列表 |
代码示例:
1 | public class Person |
6.4.2 方法的重载(overload)
- 方法的重载的要求:“两同一不同”,方法名、返回值类型相同,形参列表不同。
- 调用方法时,如何确定调用的是某个指定的方法呢?
① 方法名
② 形参列表
6.4.3 可变个数形参的方法
语法格式:
1 | void method (int ... args) |
int … arg 相当于 int[] arg
6.4.4 方法的参数传递机制:值传递
如果形参是基本数据类型的变量,则将实参保存的数据值赋给形参。
如果形参是引用数据类型的变量,则将实参保存的地址值赋给形参。
6.4.5 递归方法
递归方法构成了隐式的循环。
对比:相较于循环结构,递归方法效率稍低,内存占用偏高。
6.5.5 方法调用内存分析
方法没有被调用的时候,都在方法区中的字节码文件(.class)中存储。
方法被调用的时候,需要进入到栈内存中运行。方法每调用一次就会在栈中有一个入栈动
作,即给当前方法开辟一块独立的内存区域,用于存储当前方法的局部变量的值。
当方法执行结束后,会释放该内存,称为出栈,如果方法有返回值,就会把结果返回调用处,如果没有返回值,就直接结束,回到调用处继续执行下一条指令。
栈结构:先进后出,后进先出。
6.5 对象数组
- 数组的元素可以是基本数据类型,也可以是引用数据类型。当元素是引用类型中的类时,我们称为对象数组。
- String[ ];
- Person[ ];
- Customer[ ];
6.6 package、import 关键字
-
package:指明声明的类所属的包。
语法格式:
1
package 顶层包名.子包名 ;
-
import:当前类中,如果使用其它包下的类(除 java.lang 包),原则上就需要导入。
语法格式:
1
import 包名.类名;
6.7 面向对象的特征之一:封装性
Java 规定了 4 种权限修饰,分别是:private、缺省、protected、public。
我们可以使用 4 种权限修饰来修饰类及类的内部成员。当这些成员被调用时,体现可见性的大小。

6.7.1 封装性的体现
- 场景 1:私有化(private)类的属性,提供公共(public)的 get 和 set 方法,对此属性进行获取或修改。
- 场景 2:将类中不需要对外暴露的方法,设置为 private。
- 场景 3:单例模式中构造器 private 的了,避免在类的外部创建实例。
6.7.2 封装性的作用
- 高内聚:类的内部数据操作细节自己完成,不允许外部干涉;
(Java 程序通常以类的形态呈现,相关的功能封装到方法中。) - 低耦合:仅暴露少量的方法给外部使用,尽量方便外部调用。
(给相关的类、方法设置权限,把该隐藏的隐藏起来,该暴露的暴露出去。)
6.8 类的成员之三:构造器(Constructor)
语法格式:
1 | 修饰符 class 类名 |
代码示例:
1 | public class Person |
构造器的作用:
① 搭配上 new,用来创建对象 。
② 初始化对象的成员变量。
6.9 类的实例变量的赋值过程
-
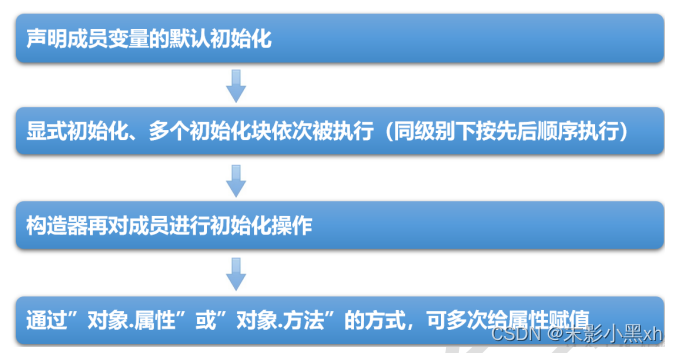
在类的属性中,可以有哪些位置给属性赋值?
① 默认初始化;
② 显式初始化;
③ 构造器中初始化;
④ 通过"对象.方法"的方式赋值;
⑤ 通过"对象.属性"的方式赋值; -
这些位置执行的先后顺序是怎样?
① - ② - ③ - ④/⑤
6.10 JavaBean
JavaBean 是一种 Java 语言写成的可重用组件。
所谓 JavaBean,是指符合如下标准的 Java 类:
- 类是公共的。
- 有一个无参的公共的构造器。
- 有属性,且有对应的 get、set 方法。
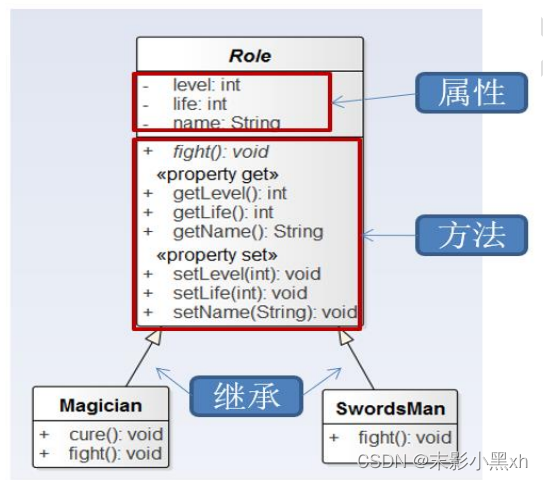
6.11 UML 类图
UML(Unified Modeling Language,统一建模语言),用来描述软件模型和架构的图形化语言。
在软件开发中,使用 UML 类图可以更加直观地描述类内部结构(类的属性和操作)以及类之间的关系(如关联、依赖、聚合等)。
6.12 企业真题
-
面向对象,面向过程的理解?
答:
面向对象和面向过程是两种不同的编程思想。面向过程编程是一种按照一定的流程和步骤来完成任务的编程方式。它将程序看作是一系列的步骤或者函数,每个函数都有一定的输入和输出。面向过程的编程思想强调的是程序的执行过程,程序的主要任务是按照一定的流程和步骤来完成任务。
面向对象编程是一种将程序看作一组对象的编程方式,它将程序看作是一组相互协作的对象,每个对象都有一定的属性和方法。面向对象的编程思想强调的是程序的设计和架构,程序的主要任务是设计和实现对象之间的关系和交互。
总的来说,面向过程的编程思想适合于简单的程序,而面向对象的编程思想适合于复杂的程序。在实际的编程中,可以根据需要选择不同的编程思想来完成任务。
-
Java 的引用类型有哪几种?
答:
类、数组、接口、枚举、注解、记录。 -
类和对象的区别?
答:
类是一种抽象的概念,描述了一类具有相同属性和行为的对象的集合。对象则是类的实例,具有独立的状态和行为。类是一种模板或蓝图,用于创建对象。它定义了对象的属性和方法,但并不实际存在于程序中。对象则是类的具体实现,它们是程序中实际存在的实体。
类和对象之间的关系是一种“是一种”(is-a)的关系。例如,一个狗类可以派生出吉娃娃犬类,吉娃娃犬就是狗类的一种具体实现。同样,一个具体的吉娃娃犬对象也是狗类的一个实例。
总之,类是一种抽象的概念,描述了一类对象的共同特征;对象则是类的具体实现,具有独立的状态和行为。
-
面向对象,你解释一下,项目中哪些地方用到面向对象?
答:
“万事万物皆对象”。面向对象是一种编程思想,它将程序中的数据和操作封装成对象,并通过对象之间的交互来完成任务。在面向对象的编程中,重点是对象,而不是函数或过程。
在项目中,面向对象通常用于设计和实现程序的核心功能模块。例如,一个电商网站的订单管理系统可以设计为一个 Order 类,它包含订单信息和操作方法,如创建订单、更新订单状态等。另外,面向对象还可以用于设计和实现用户界面、数据访问、日志记录等模块。
具体地说,项目中哪些地方用到面向对象取决于具体的业务需求和技术架构,但通常会涉及以下方面:
① 类的设计和实现:根据业务需求,设计和实现类,包括类的属性、方法、构造函数、析构函数等。
② 对象的创建和使用:在程序运行时,根据需要创建对象,调用对象的方法来完成任务。
③ 继承和多态:利用继承和多态的特性,实现代码的复用和灵活性。
④ 接口和抽象类:通过接口和抽象类,定义程序的公共接口,提高代码的可维护性和可扩展性。总之,面向对象是一种强大的编程思想,可以提高代码的可读性、可维护性和可扩展性,是现代软件开发中不可或缺的一部分。
-
Java 虚拟机中内存划分为哪些区域,详细介绍一下。
答:
Java 虚拟机中内存划分为以下几个区域:
① 程序计数器区域(Program Counter Register):程序计数器是一块较小的内存区域,它可以看作是当前线程所执行的字节码指令的行号指示器。每个线程都有一个独立的程序计数器,用于记录线程执行的位置。当线程执行 Java 方法时,程序计数器记录的是正在执行的虚拟机字节码指令的地址;当线程执行 native 方法时,程序计数器的值为 undefined。
② Java 虚拟机栈区域(Java Virtual Machine Stacks):每个线程在创建时都会分配一个 Java 虚拟机栈,用于存储方法调用的局部变量、操作数、返回值等信息。Java 虚拟机栈是一种线程私有的内存区域,它的生命周期与线程的生命周期相同。当线程调用一个方法时,Java 虚拟机会为该方法分配一个栈帧,并将该栈帧推入当前线程的 Java 虚拟机栈中。当方法执行结束时,对应的栈帧会被弹出。
③ 本地方法栈区域(Native Method Stacks):与 Java 虚拟机栈类似,本地方法栈也是一种线程私有的内存区域,用于存储 native 方法的局部变量、操作数、返回值等信息。与 Java 虚拟机栈不同的是,本地方法栈为 native 方法服务。
④ 堆区域(Heap):堆是 Java 虚拟机中最大的一块内存区域,用于存储对象实例和数组。堆是所有线程共享的内存区域,它的大小可以通过-Xmx 和-Xms 参数进行调整。Java 虚拟机的垃圾回收器会定期对堆中的无用对象进行回收。
⑤ 方法区域(Method Area):方法区是一种线程共享的内存区域,用于存储类的结构信息、常量池、静态变量、即时编译器编译后的代码等。方法区的大小可以通过-XX:MaxMetaspaceSize 参数进行调整。在 JDK8 之前,方法区被称为持久代(Permanent Generation),但在 JDK8 之后,持久代被移除,方法区被移到了本地内存中,称为元空间(Metaspace)。
⑥ 运行时常量池区域(Runtime Constant Pool):运行时常量池是方法区的一部分,用于存储编译期间生成的字面量和符号引用。与 Class 文件中的常量池不同,运行时常量池可以动态地添加、删除、修改常量池中的内容。在 JDK7 之前,运行时常量池也属于方法区,但在 JDK7 之后,运行时常量池被移到了堆中。 -
对象存在 Java 内存的哪块区域里面?
答:
堆空间。 -
private 、缺省、protected、public 的作用区域?
答:
下表是 private、缺省、protected、public 的作用区域:修饰符 类内部 同包 继承子类 其他包 private ✔️ 缺省 ✔️ ✔️ protected ✔️ ✔️ ✔️ public ✔️ ✔️ ✔️ ✔️ 解释:
类内部:在类的内部可以随意访问该成员。
同包:在同一个包中的其他类可以访问该成员。
继承子类:在继承该类的子类中可以访问该成员。
其他包:在其他包中的类可以访问该成员。 -
main 方法的 public 能不能换成 private?为什么?
答:
能。但是更改以后就不能作为程序的入口了,就只是一个普通的方法。 -
构造方法和普通方法的区别?
答:
编写代码的角度:没有共同点。声明格式、作用都不同。
字节码文件的角度:构造器会以()方法的形态呈现,用以初始化对象。 -
构造器 Constructor 是否可被 overload?
答:
可以。 -
无参构造器和有参构造器的的作用和应用?
答:
无参构造器和有参构造器是 Java 中的两种构造方法。无参构造器是指不需要传入参数的构造器,它是默认的构造器,如果一个类没有定义任何构造器,那么编译器会自动为该类生成一个无参构造器。无参构造器的作用主要是用来初始化对象的成员变量,为对象赋初值,也可以在其中进行一些初始化操作。
有参构造器是指需要传入参数的构造器,它可以根据传入的参数不同来创建不同的对象。有参构造器的作用主要是用来实现对象的初始化,可以在其中设置对象的属性,进行一些初始化操作,以及传递参数给父类的构造器。
无参构造器和有参构造器的应用场景:
① 无参构造器适用于只需要对对象进行简单的初始化的情况。
② 有参构造器适用于需要传递参数,进行复杂初始化操作的情况。
③ 如果一个类需要继承父类,那么需要在子类的有参构造器中调用父类的有参构造器,以便完成父类的初始化操作。
④ 在实现某些设计模式时,如工厂模式、建造者模式等,需要使用有参构造器来创建对象。 -
成员变量与局部变量的区别?
答:
① 定义位置不同:成员变量定义在类中,局部变量定义在方法、代码块或者语句中。
② 生命周期不同:成员变量的生命周期与对象相同,而局部变量在方法结束后就会被销毁。
③ 访问方式不同:成员变量可以被类中的所有方法访问,而局部变量只能在定义它的方法中被访问。
④ 默认值不同:成员变量有默认值,而局部变量没有。成员变量的默认值是基本类型为 0 或者 false,引用类型为 null。
⑤ 内存分配不同:成员变量在对象创建时会被分配内存空间,而局部变量在方法调用时才会被分配内存空间。
⑥ 作用范围不同:成员变量的作用范围是整个类,而局部变量的作用范围只在定义它的方法内部。 -
变量赋值和构造方法加载的优先级问题?
答:
通过字节码文件,变量显式赋值先于构造器中的赋值。从字节码文件的角度来看,变量的显式赋值是在类的初始化阶段执行的,而构造方法中的赋值是在对象实例化阶段执行的。
在类的初始化阶段,字节码解释器会按照顺序执行类中所有静态变量的显式赋值语句,将值存储在静态变量表中。然后再执行静态代码块和其他静态方法。这个过程只会执行一次,即在类被加载到内存中时执行。
在对象实例化阶段,字节码解释器会先分配对象所需的内存空间,然后会按照顺序执行实例变量的显式赋值语句,将值存储在实例变量表中。接着执行构造方法中的代码,其中可能包含对实例变量的赋值操作。这个过程对每个对象都会执行一次。
因此,从字节码文件的角度来看,变量的显式赋值优先于构造方法中的赋值,因为它们在不同的阶段执行。
假设有以下 Java 类:
1
2
3
4
5
6
7
8
9public class MyClass
{
private int x = 1;
public MyClass(int x)
{
this.x = x;
}
}对应的字节码文件如下(省略了一些细节):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36// MyClass.class
// 类的头部
public class MyClass
{
// 实例变量表
private int x; // 默认值为0
// 构造方法表
public MyClass(int x)
{
// 调用父类构造方法
super();
// 对象实例化阶段,先执行实例变量的显式赋值
this.x = 1;
// 构造方法中的赋值
this.x = x;
// 构造方法结束
return;
}
// 静态变量表
static int y; // 默认值为0
// 静态代码块
static
{
// 类的初始化阶段,先执行静态变量的显式赋值
y = 2;
// 再执行静态代码块和其他静态方法
// ...
return;
}
}从字节码文件可以看出,在类的初始化阶段,静态变量的显式赋值先于静态代码块和其他静态方法执行;而在对象实例化阶段,实例变量的显式赋值先于构造方法中的赋值执行。
以下是使用 javap 命令生成的 MyClass 类的字节码汇编代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22public class MyClass
{
private int x;
public MyClass(int);
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: aload_0
5: iconst_1
6: putfield #2 // Field x:I
9: aload_0
10: iload_1
11: putfield #2 // Field x:I
14: return
static {};
Code:
0: iconst_2
1: putstatic #3 // Field y:I
4: return
}其中,构造方法的字节码指令如下:
1
2
3
4
5
6
7
8
90: aload_0 // 将this引用入栈
1: invokespecial #1 // 调用父类构造方法
4: aload_0 // 将this引用入栈
5: iconst_1 // 将常量1入栈
6: putfield #2 // 将栈顶值(常量1)赋值给实例变量x
9: aload_0 // 将this引用入栈
10: iload_1 // 将参数x入栈
11: putfield #2 // 将栈顶值(参数x)赋值给实例变量x
14: return // 返回静态代码块的字节码指令如下:
1
2
30: iconst_2 // 将常量2入栈
1: putstatic #3 // 将栈顶值(常量2)赋值给静态变量y
4: return // 返回可以看出,字节码汇编代码中也体现了变量的显式赋值先于构造方法中的赋值。
第 7 章:面向对象——进阶
7.1 this 关键字
-
this 调用的结构:属性、方法、构造器。
-
this 调用属性或方法时,理解为当前对象或当前正在创建的对象。
代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41public class Person
{
private String name;
private int age;
// 无参构造
public Person()
{
}
// 有参构造
public Person(String name)
{
this(); // 调用本类无参构造器
this.name = name;
}
// 有参构造
public Person(String name,int age)
{
this(name); // 调用本类中有一个 String 参数的构造器
this.age = age;
}
public String getName()
{
return name;
}
public void setName(String name)
{
// 当属性名和形参名同名时,必须使用this来区分
this.name = name;
}
public int getAge()
{
return age;
}
public void setAge(int age)
{
this.age = age;
}
} -
this(形参列表)的方式,表示调用当前类中其他的重载的构造器。
7.2 面向对象的特征二:继承性
语法格式:
1 | 修饰符 class A |
子类获取了父类中声明的全部的属性、方法。但是可能受封装性的影响,不能直接调用。
7.2.1 继承性的好处
- 减少了代码的冗余,提高了复用性。
- 提高了扩展性。
- 为多态的实现,提供了前提。
7.2.2 Java 中继承性的特点
- 局限性:类的单继承性。通过类实现接口的方式,解决单继承的局限性。
- 支持多层继承,一个父类可以声明多个子类。
7.3 方法的重写(override 、overwrite)
方法的重载与重写的区别?
- 方法的重载:“两同一不同”,方法名、返回值类型相同,形参列表不同。
- 方法的重写:
- 前提:类的继承关系。
- 子类对父类中同名同参数方法的覆盖、覆写。
7.4 super 关键字
super 可以调用的结构:属性、方法、构造器。
super 调用父类的属性、方法:
- 如果子父类中出现了同名的属性,此时使用 super.的方式,表明调用的是父类中声明的属性。
- 子类重写了父类的方法。如果子类的任何一个方法中需要调用父类被重写的方法时,需要使用 super.
super 调用构造器:
- 在子类的构造器中,首行使用了"this(形参列表)“,或者使用了"super(形参列表)”。
7.5 子类对象实例化的全过程
- 结果上:体现为继承性。
- 过程上:子类调用构造器创建对象时,一定会直接或间接的调用其父类的构造器,以及父类的父类的构造器,直到调用到 Object()的构造器。
7.6 面向对象的特征三:多态性
-
广义上的理解:子类对象的多态性、方法的重写;方法的重载。
-
狭义上的理解:子类对象的多态性,即父类的引用指向子类的对象。
语法格式:
1
Object obj = new String(“HelloWorld!”); // 父类的引用指向子类的对象。
-
多态的好处:减少了大量的重载的方法的定义;对扩展开放,对修改关闭原则。
-
举例:public boolean equals(Object obj)
-
多态的使用:虚方法调用(动态链接或晚期绑定)。“编译看左边,运行看右边”。
-
多态的逆过程:向下转型,使用强转符()。
- 为了避免出现强转时的 ClassCastException,建议()之前使用 instanceOf 进行判断。
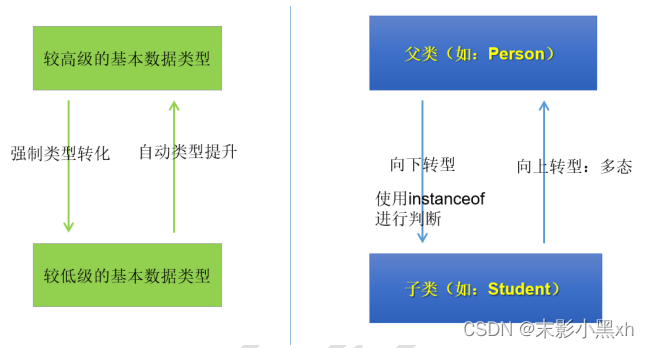
- 为了避免出现强转时的 ClassCastException,建议()之前使用 instanceOf 进行判断。
7.7 Object 类
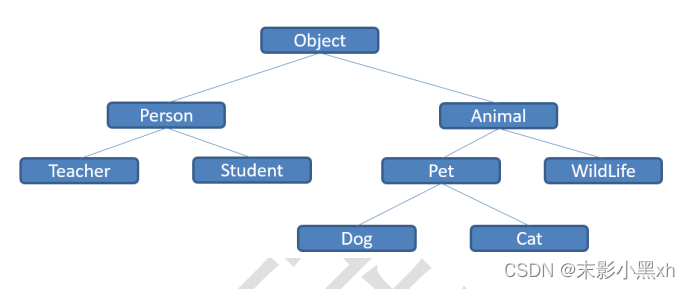
7.7.1 理解根父类
类 java.lang.Object 是类层次结构的根类,即所有其它类的父类。每个类都使用 Object 作为超类。
7.7.2 Object 类的方法
-
equals()
- == :
- 基本类型比较值:只要两个变量的值相等,即为 true。
- 引用类型比较引用(是否指向同一个对象):只有指向同一个对象时,==才返回 true。
- equals():所有类都继承了 Object,也就获得了 equals()方法,可以重写。
- 只能比较引用类型,Object 类源码中 equals()的作用与“==”相同:比较是否指向同一个对象。
- == :
-
toString()
- Object 中 toString()调用后,返回当前对象所属的类和地址值。
- 开发中常常重写 toString(),用于返回当前对象的属性信息。
-
clone()
- clone() 方法是 Object 类中的一个方法,它用于创建并返回当前对象的一个副本。
- 该方法是 protected 访问修饰符,只能被子类重写或调用。
- 在调用 clone() 方法时,如果类没有实现 Cloneable 接口,会抛出 CloneNotSupportedException 异常。因此,要使用 clone() 方法,需要满足两个条件:
- 类必须实现 Cloneable 接口。
- 在类中重写 clone() 方法,并将其访问修饰符改为 public。
- clone() 方法的使用可以避免一些对象拷贝的问题,例如浅拷贝和深拷贝。浅拷贝只复制对象的引用,而不是对象本身,因此当拷贝对象的某个属性发生变化时,原对象和拷贝对象的该属性都会发生变化。深拷贝则是完全复制一个对象,包括其所有属性,因此拷贝对象的属性变化不会影响原对象的属性。
-
finalize()
- 当对象被回收时,系统自动调用该对象的 finalize() 方法。(不是垃圾回收器调用的,
是本类对象调用的。)
- 当对象被回收时,系统自动调用该对象的 finalize() 方法。(不是垃圾回收器调用的,
-
getClass()
- public final Class<?> getClass():获取对象的运行时类型。
-
hashCode()
- public int hashCode():返回每个对象的 hash 值。
7.2.3 native 关键字
使用 native 关键字说明这个方法是原生函数,也就是这个方法是用 C/C++等非 Java 语言实现的,并且被编译成了 DLL,由 Java 去调用。
7.8 企业真题
-
父类哪些成员可以被继承,属性可以被继承吗?请举下例子。
答:
子类可以继承父类的以下成员:
① 非私有的属性和方法(包括静态和实例成员)。
② 父类的构造方法。子类不能继承父类的私有成员。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39class Person
{
public String name; // 非私有的属性
public void say()
{
// 非私有的方法
System.out.println("Hello!");
}
private int age; // 私有的属性
private void walk()
{
// 私有的方法
System.out.println("Walking...");
}
}
class Student extends Person
{
// 可以继承父类的非私有属性和方法
public void study()
{
System.out.println("Studying...");
}
// 无法继承父类的私有属性和方法
/*
public int getAge()
{
return age;
}
public void go()
{
walk();
}
*/
}在上面的例子中,子类 Student 继承了父类 Person 的 name 属性和 say()方法,但无法继承 age 属性和 walk()方法,因为它们都是私有的。
需要注意的是,子类虽然可以继承父类的属性,但是它们并不属于子类自己的属性,而是从父类继承而来的。子类可以通过继承来获得父类的属性和方法,但是不能直接访问父类的私有成员。
-
什么是 Override,与 Overload 的区别?
答:
Override 是指在子类中重写父类的方法,使得子类的方法覆盖了父类的方法,具有相同的方法名、参数列表和返回值类型。Overload 是指在同一类中定义多个方法,它们具有相同的方法名,但参数列表不同(包括参数类型、个数或顺序),从而实现不同的功能。
区别在于 Override 是继承关系中子类对父类方法的重写,Overload 是在同一类中定义多个方法,参数列表不同,目的是提供多个方法实现不同的功能。
-
Overload 的方法是否可以改变返回值的类型?
答:
Overload 的方法不能仅仅通过返回值类型的改变来进行重载。方法的重载必须要求参数列表不同,而返回值类型不是方法签名的一部分。如果只是改变返回值类型而不改变参数列表,编译器将会报错。 -
构造器 Constructor 是否可被 override?
答:
构造器 Constructor 不能被 override,因为构造器的名字必须与类名相同,并且没有返回值类型。如果子类需要调用父类的构造器,可以使用 super 关键字来实现。但是子类可以提供自己的构造器,可以使用 super 关键字在子类的构造器中调用父类的构造器。 -
为什么要有重载,我随便命名一个别的函数名不行吗?谈谈你是怎么理解的。
答:
Java 中,重载是指在同一个类中,可以定义多个同名但参数类型、个数或顺序不同的方法,这些方法可以根据不同的参数类型和个数进行区分,从而实现不同的功能。重载的作用是提高代码的可读性和可维护性。通过重载,可以使用相同的方法名来表示不同的操作,使代码更加简洁明了。同时,重载还可以提高代码的灵活性,可以根据不同的情况选择不同的方法进行调用,从而实现更加精细的控制。
如果随便命名一个别的函数名,可能会导致命名冲突,增加代码的维护难度,同时也会降低代码的可读性和可维护性。因此,在 Java 中,重载是一种非常重要的语言特性,可以提高代码的可读性和可维护性。
-
super 和 this 的区别?
答:
super 和 this 是 Java 中两个关键字,它们的作用不同。super 表示父类,可以用来访问父类中的属性和方法。在子类中,如果要调用父类中的方法或者属性,可以使用 super 关键字。例如,如果子类中有一个和父类同名的方法或者属性,可以使用 super 关键字来区分调用父类的方法或者属性。super 关键字只能用在子类中。
this 表示当前对象,可以用来访问当前对象的属性和方法。在一个类中,如果要调用当前对象的属性或者方法,可以使用 this 关键字。例如,如果一个类中有一个成员变量和一个局部变量同名,可以使用 this 关键字来区分访问成员变量或者局部变量。this 关键字可以在任何地方使用。
总的来说,super 和 this 的作用不同,super 用于访问父类的属性和方法,this 用于访问当前对象的属性和方法。
-
this、super 关键字分别代表什么?以及他们各自的使用场景和作用。
答:
this 和 super 是 Java 中的关键字,分别代表当前对象和父类对象。this 关键字代表当前对象,可以用来引用当前对象的属性和方法。this 关键字主要用于以下场景:
① 当局部变量和成员变量同名时,使用 this 关键字可以区分二者,如 this.name 表示当前对象的 name 属性,name 表示局部变量。
② 在构造器中调用另一个构造器时,使用 this 关键字可以调用同一个类中的其他构造器,如 this(name),表示调用该类中的带有一个参数的构造器。
③ 在方法链式调用时,使用 this 关键字可以返回当前对象,如 return this。
super 关键字代表父类对象,可以用来调用父类的属性和方法。super 关键字主要用于以下场景:
① 在子类中调用父类的构造方法时,使用 super 关键字可以调用父类的构造方法,如 super(),表示调用父类的无参构造器。
② 当子类和父类有同名属性或方法时,使用 super 关键字可以调用父类的属性或方法,如 super.name 表示调用父类的 name 属性。总的来说,this 关键字用于当前对象中,super 关键字用于父类对象中。它们的使用场景和作用不同,但都可以方便地引用当前对象或父类对象的属性和方法。
-
谈谈你对多态的理解。
答:
多态是面向对象程序设计中的重要概念,它是指同一个方法可以根据不同的对象调用出不同的行为。具体来说,多态包括两种类型:静态多态和动态多态。静态多态是指在编译阶段就确定了调用的方法,主要通过方法的重载和参数的多态来实现。例如,同一个类中可以有多个同名方法,但是参数类型或个数不同,编译器在编译时会根据参数类型和个数来自动匹配调用哪个方法。
动态多态是指在运行时根据实际对象的类型来确定调用的方法,主要通过方法的重写和父类引用指向子类对象来实现。例如,一个父类引用可以指向其子类对象,当调用该引用的方法时,实际调用的是子类的方法。
多态的优点在于可以增加程序的灵活性和可扩展性,使代码更加简洁、可读性更高。它可以减少代码的重复,使程序更易于维护和修改。同时,多态也是面向对象程序设计的核心思想之一,它有助于提高代码的可重用性和可维护性,增强了程序的可扩展性和可靠性。
-
多态 new 出来的对象跟不多态 new 出来的对象区别在哪?
答:
多态 new 出来的对象是基于父类或接口创建的,可以根据实际情况指向不同的子类对象,具有更强的灵活性和可扩展性;而不多态 new 出来的对象是直接创建的具体子类对象,无法在运行时进行动态绑定,缺乏灵活性和可扩展性。 -
说说你认为多态在代码中的体现。
答:
多态是指同一种操作作用于不同的对象上面,可以产生不同的执行结果。在 Java 中,多态主要通过以下三种方式体现:
① 方法重载:方法重载是指在同一个类中,有多个方法名相同但参数类型或个数不同的方法。这种方法的调用会根据传入的参数类型或个数的不同,自动匹配调用相应的方法,实现了多态。
② 方法重写:方法重写是指子类重写了父类的方法,当调用这个方法时,实际上会根据对象的实际类型调用对应的方法。这种方法实现了运行时多态。
③ 接口实现:接口是一种规范,定义了一组方法的签名,实现接口的类必须实现这些方法。当一个类实现了多个接口时,可以根据需要选择调用不同的方法,实现了多态。 -
== 与 equals() 的区别?
答:
在 Java 中,== 是一个操作符,用于比较两个对象的内存地址是否相同,即它们是否是同一个对象。而 equals()是一个方法,用于比较两个对象的内容是否相同,即它们是否具有相同的属性值。在 Java 中,所有的类都继承自 Object 类,Object 类中的 equals()方法默认使用==比较两个对象的内存地址。因此,如果我们想要比较两个对象的内容是否相同,需要重写 equals()方法来实现比较对象属性值的操作。
例如,我们可以在自定义类中重写 equals()方法,比较对象的属性值是否相同,如下所示:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class Person
{
private String name;
private int age;
// 构造方法和其他方法省略
public boolean equals(Object o)
{
if (this == o)
return true;
if (!(o instanceof Person))
return false;
Person person = (Person) o;
return age == person.age &&
Objects.equals(name, person.name);
}
}在这个例子中,我们重写了 Person 类的 equals()方法,首先使用==比较两个对象的内存地址,如果相同则返回 true,否则判断 o 是否是 Person 类的实例,如果不是则返回 false,最后比较两个对象的属性值是否相同,如果相同则返回 true,否则返回 false。
在使用 equals()方法比较两个对象时,需要注意以下几点:
① equals()方法必须满足自反性、对称性、传递性和一致性等特性;
② equals()方法的参数必须是 Object 类型,需要进行类型转换;
③ equals()方法比较两个对象的属性值时,需要使用 Objects.equals()方法,避免空指针异常。 -
重写 equals()方法要注意什么?
答:
重写 equals()方法是为了比较两个对象是否相等,因此需要注意以下几点:
① 对象比较要使用 equals()方法,而不是“==”运算符。
② 重写 equals()方法时,需要重写 hashCode()方法,保证相等的对象具有相同的哈希码。
③ equals()方法必须具有自反性、对称性、传递性和一致性。
④ equals()方法的参数必须是 Object 类型,需要进行类型检查和类型转换。
⑤ 在比较对象的属性时,需要逐个比较所有属性,而不是只比较其中的几个属性。
⑥ 如果子类中增加了新的属性,需要在 equals()方法中同时比较新的属性。
⑦ 如果父类已经实现了 equals()方法,子类可以选择继承父类的 equals()方法,也可以重写 equals()方法。如果重写了 equals()方法,需要调用父类的 equals()方法进行比较。 -
Java 中所有类的父类是什么?他都有什么方法?
答:
Java 中所有类的父类是 Object 类。Object 类中常用的方法有:
① toString():返回对象的字符串表示形式。
② equals(Object obj):判断两个对象是否相等。
③ hashCode():返回对象的哈希码值。
④ getClass():返回对象的类。
⑤ wait():使当前线程等待。
⑥ notify():唤醒正在等待该对象的线程。
⑦ notifyAll():唤醒正在等待该对象的所有线程。
⑧ finalize():在对象被垃圾回收器回收之前调用。
第 8 章 面向对象——高级
8.1 static 关键字
-
static 使用范围:
- 在 Java 类中,可用 static 修饰属性、方法、代码块、内部类。
-
语法格式:
1
2
3
4
5
6
7
8
9修饰符 class 类
{
修饰符 static 数据类型 变量名;
修饰符 static 返回值类型 方法名(形参列表)
{
方法体
}
} -
static 修饰后的成员具备以下特点:
- 静态的,随着类的加载而加载、执行。
- 随着类的加载而加载。
- 优先于对象存在。
- 修饰的成员,被所有对象所共享。
- 访问权限允许时,可不创建对象,直接被类调用。
-
类变量:类的生命周期内,只有一个。被类的多个实例共享。
8.2 单例模式
经典的设计模式有 23 种。每个设计模式均是特定环境下特定问题的处理方法。

对软件设计模式的研究造就了一本可能是面向对象设计方面最有影响的书籍:《设计模式》:《Design Patterns: Elements of Reusable Object-Oriented Software》,由 Erich Gamma、Richard Helm、Ralph Johnson 和 John Vlissides 合著(Addison-Wesley,1995)。这几位作者常被称为"四人组(Gang of Four)",而这本书也就被称为"四人组(或 GoF)"书。
单例设计模式,就是采取一定的方法保证在整个的软件系统中,对某个类只能存在一个对象实例,并且该类只提供一个取得其对象实例的方法。
实现方式:饿汉式、懒汉式、枚举类等。
饿汉式代码示例:
1 | lass Singleton |
懒汉式代码示例:
1 | class Singleton |
饿汉式和懒汉式的区别:
- 饿汉式:“立即加载”,线程安全的。
- 懒汉式:“延迟加载”,线程不安全。
8.3 理解 main()方法的语法
1 | public static void main(String[] args) |
由于 JVM 需要调用类的 main()方法,所以该方法的访问权限必须是 public。
又因为 JVM 在执行 main()方法时不必创建对象,所以该方法必须是 static 的,该方法接收一个 String 类型的数组参数,该数组中保存执行 Java 命令时传递给所运行的类的参数。
又因为 main() 方法是静态的,我们不能直接访问该类中的非静态成员,必须创建该类的一个实例对象后,才能通过这个对象去访问类中的非静态成员。
8.4 类的成员之四:代码块
-
分类:静态代码块、非静态代码块。
-
语法格式:
1
2
3
4
5
6
7修饰符 class 类
{
static
{
静态代码块
}
} -
静态代码块:随着类的加载而执行。
-
非静态代码块:随着对象的创建而执行。
-
总结
对象的实例变量可以赋值顺序:
8.5 final 关键字
final:最终的,不可更改的。
用来修饰:类、方法、变量(成员变量、局部变量)。
- 类:不能被继承。
- 方法:不能被重写。
- 变量:是一个“常量”,一旦赋值不能修改。
8.6 abstract 关键字
随着继承层次中一个个新子类的定义,类变得越来越具体,而父类则更一般,更通用。类的设计应该保证父类和子类能够共享特征。有时将一个父类设计得非常抽象,以至于它没有具体的实例,这样的类叫做抽象类。
abstract:抽象的。
抽象类的语法格式:
1 | 修饰符 abstract class 类名 |
抽象方法的语法格式:
1 | 修饰符 abstract 返回值类型 方法名([形参列表]); |
用来修饰:类、方法。
- 类:抽象类:不能实例化。
- 方法:抽象方法:没有方法体,必须由子类实现此方法。
模板方法模式(TemplateMethod) :
- 抽象类体现的就是一种模板模式的设计,抽象类作为多个子类的通用模板,子类在抽象类的基础上进行扩展、改造,但子类总体上会保留抽象类的行为方式。
8.7 interface 关键字
Java 的软件系统会有很多模块组成,那么各个模块之间也应该采用这种面向接口的低耦合,为系统提供更好的可扩展性和可维护性。
interface:接口,用来定义一组规范、一种标准。
接口声明的语法格式:
1 | 修饰符 interface 接口名 |
在 JDK8.0 之前,接口中只允许声明:
① 公共的静态的常量。
② 公共的抽象的方法。
- 在 JDK8.0 时,接口中允许声明默认方法和静态方法。
类实现接口(implements):
- 接口不能创建对象,但是可以被类实现(implements ,类似于被继承)。
- 类与接口的关系为实现关系,即类实现接口,该类可以称为接口的实现类。
接口实现的语法格式:
1 | 修饰符 class 实现类 implements 接口 |
接口可以多继承、多实现。
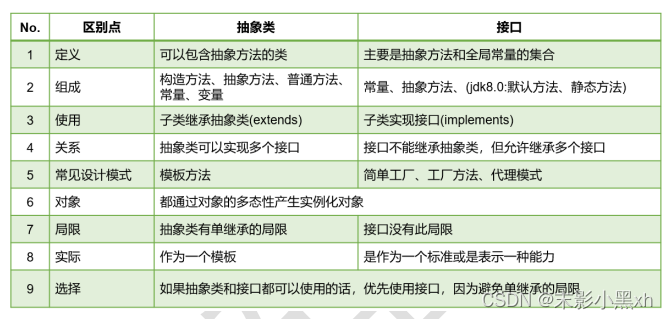
接口与抽象类之间的对比:
8.8 类的成员之五:内部类
将一个类 A 定义在另一个类 B 里面,里面的那个类 A 就称为内部类,类 B 则称为外部类。
-
成员内部类:
成员内部类的语法格式:1
2
3
4
5
6
7修饰符 class 外部类
{
修饰符 static class 内部类
{
}
} -
非匿名局部内部类:
非匿名局部内部类的语法格式:1
2
3
4
5
6
7
8
9
10修饰符 class 外部类
{
修饰符 返回值类型 方法名(形参列表)
{
final/abstract class 内部类
{
}
}
} -
匿名内部类:
匿名内部类的语法格式:1
2
3
4
5
6
7
8
9new 父接口()
{
重写方法
}
new 父类(实参列表)
{
重写方法
}
8.9 枚举类:enum
枚举类型本质上也是一种类,只不过是这个类的对象是有限的、固定的几个,不能让用户随意创建。
使用 enum 关键字定义枚举类。
语法格式:
1 | 修饰符 enum 枚举类名 |
8.10 注解:Annotation
注解(Annotation)是从 JDK5.0 开始引入,以“@注解名”在代码中存在。
Annotation 可以像修饰符一样被使用,可用于修饰包、类、构造器、方法、成员变量、参数、局部变量的声明。还可以添加一些参数值,这些信息被保存在 Annotation 的 “name=value” 对中。
注解可以在类编译、运行时进行加载,体现不同的功能。
常用注解:
- @Override: 限定重写父类方法,该注解只能用于方法。
- @Deprecated: 用于表示所修饰的元素(类,方法等)已过时。通常是因为所修饰的结构危险或存在更好的选择。
- @SuppressWarnings: 抑制编译器警告。
元注解:对现有的注解进行解释说明。
- @Target:表明可以用来修饰的结构。
- @Retation:表明生命周期。
- @Documented:表明这个注解应该被 javadoc 工具记录。
- @Inherited:允许子类继承父类中的注解如何自定义注解。
自定义注解的使用:
-
一个完整的注解应该包含三个部分: ① 声明 ② 使用 ③ 读取
-
声明自定义注解 :
语法格式:1
2
3
4
5元注解
修饰符 @interface 注解名
{
成员列表
}
框架 = 注解 + 反射 + 设计模式
8.11 JUnit 单元测试
-
测试分类:
- 黑盒测试:不需要写代码,给输入值,看程序是否能够输出期望的值。
- 白盒测试:需要写代码的。关注程序具体的执行流程。
-
JUnit 是由 Erich Gamma 和 Kent Beck 编写的一个测试框架(regression testing framework),供 Java 开发人员编写单元测试之用。
-
编写和运行@Test 单元测试方法:
-
JUnit4 版本,要求@Test 标记的方法必须满足如下要求:
- 所在的类必须是 public 的,非抽象的,包含唯一的无参构造器。
- @Test 标记的方法本身必须是 public,非抽象的,非静态的,void 无返回值,无参数的。
8.12 包装类
基本数据类型对应的包装类都有哪些?
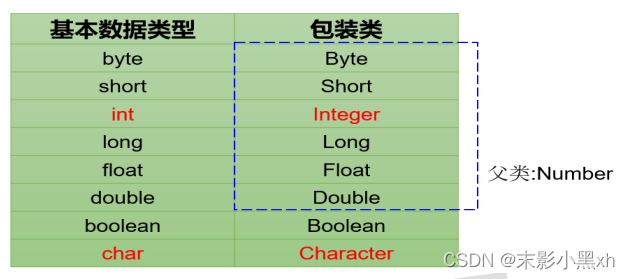
基本数据类型、包装类、String 三者之间的转换:
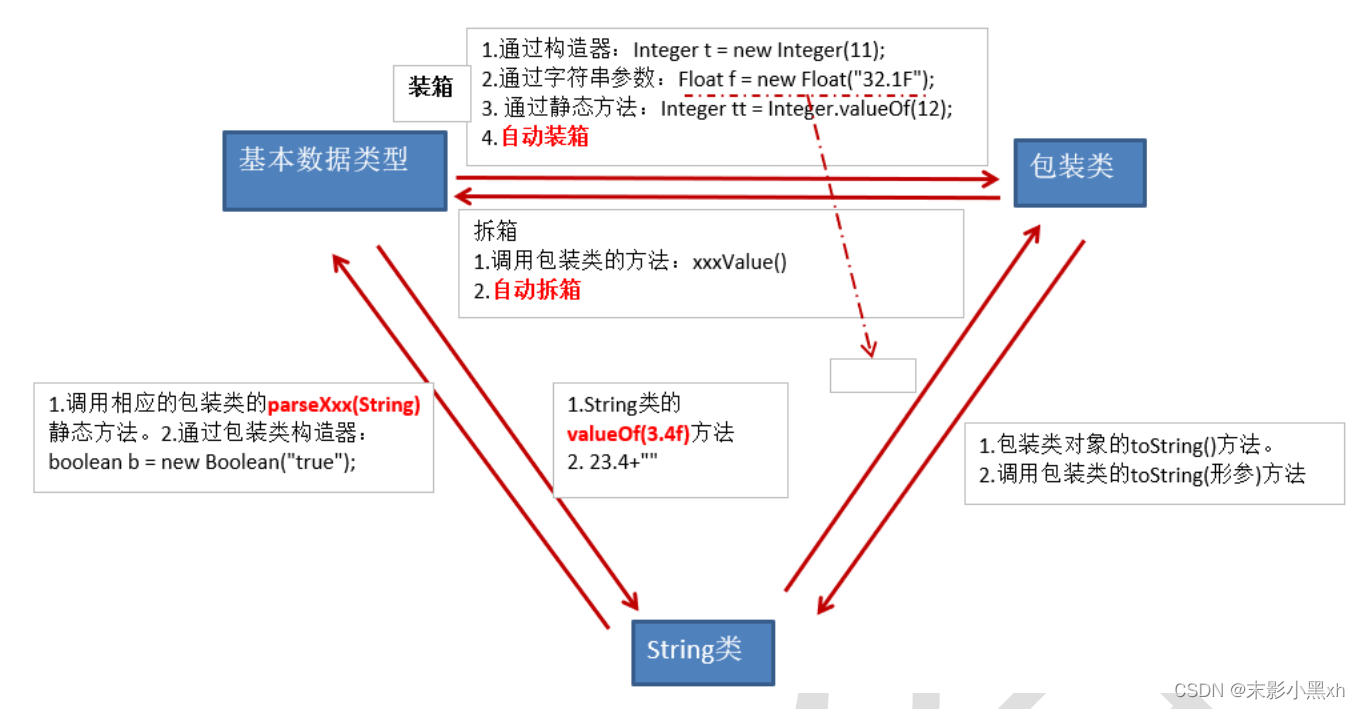
基本数据类型 <——> 包装类:自动装箱、自动拆箱。
String 类的 valueOf(xxx)方法。
包装类的 parseXxx(String str)方法。
8.13 IDEA 的 Debug
程序在执行过程中如果出现错误,该如何查找或定位错误呢?简单的代码直接就可以看出来,但如果代码比较复杂,就需要借助程序调试工具(Debug)来查找错误了。
Debug(调试)程序步骤如下:
① 添加断点。
② 启动调试。
③ 单步执行。
④ 观察变量和执行流程,找到并解决问题。
8.14 企业真题
-
静态变量和实例变量的区别?
答:
静态变量是属于类的变量,只有一个副本,被该类的所有实例共享,可以通过类名访问。实例变量是属于对象的变量,每个对象都有自己的一份副本,互相独立,只能通过实例名访问。静态变量在类加载时初始化,实例变量在实例化对象时初始化。静态变量一般用于存储常量或类级别的变量,实例变量一般用于存储对象的状态信息。 -
静态属性和静态方法是否可以被继承?是否可以被重写?以及原因?
答:
静态属性和静态方法可以被继承,但不能被重写。静态属性和静态方法是属于类的,而不是属于实例的。子类继承父类时,会继承父类的静态属性和静态方法,但是子类无法重写父类的静态属性和静态方法,因为静态属性和静态方法是属于类的,而不是属于对象的。在子类中可以使用父类的静态属性和静态方法,也可以定义自己的静态属性和静态方法,但是不能重写父类的静态属性和静态方法。
-
是否可以从一个 static 方法内部发出对非 static 方法的调用?
答:
可以从一个 static 方法内部发出对非 static 方法的调用,但前提是必须先创建一个对象实例,然后通过该实例来调用非 static 方法。因为非 static 方法是属于对象的,需要通过对象实例才能调用,而 static 方法是属于类的,可以直接通过类名调用。如果在 static 方法中要调用非 static 方法,必须先创建一个对象实例,然后通过该实例来调用非 static 方法。例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class MyClass
{
private int num;
public void nonStaticMethod()
{
System.out.println("这是一个非静态方法。");
}
public static void staticMethod()
{
MyClass obj = new MyClass();
obj.nonStaticMethod();
System.out.println("这是一个静态方法。");
}
}在上面的代码中,staticMethod() 中创建了一个 MyClass 的对象实例 obj,并通过该实例来调用 nonStaticMethod()。
-
被 static 修饰的成员(类、方法、成员变量)能否再使用 private 进行修饰?
答:
可以。被 static 修饰的成员可以再使用 private 进行修饰,表示该成员只能在当前类中被访问,不能被其他类访问。这样可以保证该成员的访问权限更加严格,增加程序的安全性。 -
知道哪些设计模式?
答:
我知道很多设计模式,包括: - 单例模式 - 工厂模式 - 抽象工厂模式 - 建造者模式 - 原型模式 - 适配器模式 - 桥接模式 - 组合模式 - 装饰器模式 - 外观模式 - 享元模式 - 代理模式 - 责任链模式 - 命令模式 - 解释器模式 - 迭代器模式 - 中介者模式 - 备忘录模式 - 观察者模式 - 状态模式 - 策略模式 - 模板方法模式 - 访问者模式当然,这只是其中的一部分,设计模式还有很多种,每种模式都有自己的应用场景和优缺点。
-
开发中都用到了那些设计模式?用在什么场合?
答:
在开发中常用的设计模式包括:
① 单例模式:保证一个类只有一个实例,并提供全局访问点。
② 工厂模式:将对象的创建和使用分离,通过工厂类来创建对象。
③ 观察者模式:一对多的依赖关系,当一个对象的状态发生改变时,所有依赖它的对象都会得到通知。
④ 建造者模式:将一个复杂对象的构建过程分解为多个简单对象的构建过程,使得构建过程灵活性增强,且更易于扩展。
⑤ 适配器模式:将一个类的接口转换成客户希望的另外一个接口,使得原本由于接口不兼容而不能一起工作的类可以一起工作。
⑥ 装饰器模式:动态地给一个对象添加一些额外的职责,而不需要修改原始类的代码。
⑦ 策略模式:定义一系列算法,将它们封装起来,并且使它们可以互相替换,使得算法的变化独立于使用算法的客户。这些设计模式都有各自的使用场合,如单例模式可以用于创建全局唯一的对象;工厂模式可以用于创建一系列相关对象;观察者模式可以用于实现事件驱动的程序设计;建造者模式可以用于构建复杂对象;适配器模式可以用于不同接口之间的转换;装饰器模式可以用于扩展对象的功能;策略模式可以用于解耦算法的实现和使用。
-
main()方法的 public 能不能换成 private,为什么?
答:
不可以。因为 main()方法是程序的入口,如果将其访问修饰符改为 private,那么程序在启动时就无法访问该方法,无法执行程序。因此,main()方法必须是 public 修饰,以便程序能够访问执行。 -
main()方法中是否可以调用非静态方法?
答:
可以调用非静态方法,但需要先创建该方法所在类的对象,然后通过对象来调用非静态方法。 -
类的组成和属性赋值执行顺序?
答:
类的组成包括类名、属性、方法和构造函数。属性赋值执行顺序是在创建类的实例时执行的,先执行构造函数,然后按照属性的定义顺序依次执行属性的赋值操作。如果属性有默认值,则先执行默认值的赋值操作,然后再执行构造函数中的赋值操作。在属性赋值时,如果属性有 setter 方法,则会调用 setter 方法来完成赋值操作。 -
静态代码块,普通代码块,构造方法,从类加载开始的执行顺序?
答:
① 静态代码块:在类加载时执行,只执行一次;
② 普通代码块:在创建对象时执行,每次创建对象都会执行一次;
③ 构造方法:在创建对象时执行,每次创建对象都会执行一次。执行顺序为:静态代码块 → 普通代码块 → 构造方法。
-
描述一下对 final 理解。
答:
final 是 Java 中的一个关键字,可以用来修饰类、方法和变量。final 关键字的主要作用是:
① final 修饰的类不能被继承,即该类为最终类。
② final 修饰的方法不能被子类重写,即该方法为最终方法。
③ final 修饰的变量为常量,即该变量的值不能被修改,一旦被赋值后就不能再改变。final 关键字的使用可以提高程序的安全性和效率,因为 final 修饰的类、方法和变量在程序运行时无法被修改,从而防止了程序中的错误和不必要的开销。同时,final 还可以用来定义常量,方便程序中的使用和维护。
-
使用 final 修饰一个变量时,是引用不能改变,引用指向的对象可以改变?
答:
如果 final 修饰的是一个引用变量,则该引用变量所指向的对象不能被改变,但该对象的属性值可以被改变。如果 final 修饰的是一个基本数据类型变量,则该变量的值不能被改变。 -
final 不能用于修饰构造方法?
答:
是的,final 关键字不能用于修饰构造方法。final 关键字可以用于修饰类、成员变量和方法,但不能用于构造方法。这是因为构造方法的主要作用是初始化对象的状态,而 final 关键字表示不可变性,这与构造方法的目的不符。 -
final 或 static final 修饰成员变量,能不能进行++操作?
答:
无法进行++操作。final 修饰的成员变量是常量,不可被修改;而 static final 修饰的成员变量是静态常量,也不可被修改。因此,++操作是不允许的。 -
什么是抽象类?如何识别一个抽象类?
答:
抽象类是一种不能被实例化的类,其目的是为了被其他类继承而设计的。抽象类中可以包含抽象方法和非抽象方法,抽象方法是指没有实现的方法,需要在子类中被实现。非抽象方法是指已经实现的方法,可以直接在抽象类中调用。抽象类可以通过关键字"abstract"来定义。如果一个类中包含至少一个抽象方法,那么该类必须被定义为抽象类。抽象类不能被实例化,只能被继承,并且子类必须实现所有抽象方法,否则子类也必须被定义为抽象类。
以下是一个抽象类的例子:1
2
3
4
5
6
7
8public abstract class Animal
{
public abstract void makeSound();
public void eat()
{
System.out.println("我在吃东西。");
}
}在上面的例子中,Animal 是一个抽象类,其中包含一个抽象方法 makeSound()和一个非抽象方法 eat()。makeSound()方法必须在子类中被实现,而 eat()方法已经被实现,可以直接在 Animal 类中调用。
-
为什么不能用 abstract 修饰属性、私有方法、构造器、静态方法、final 的方法?
答:
① 属性:抽象属性没有实现,无法在子类中重写,因此没有意义。
② 私有方法:私有方法只能在本类中被调用,无法在子类中重写,因此没有意义。
③ 构造器:构造器用于创建对象,不能被重写,因此没有意义。
④ 静态方法:静态方法属于类,不属于实例,无法被重写,因此没有意义。
⑤ final 方法:final 方法表示该方法不能被重写,因此使用 abstract 修饰没有意义。 -
接口与抽象类的区别?
答:
① 定义方式不同:接口使用 interface 关键字定义,抽象类使用 abstract 关键字定义。
② 实现方式不同:类可以实现多个接口,但只能继承一个抽象类。
③ 方法实现方式不同:接口中的方法都是抽象方法,没有方法体,实现类必须重写所有接口中的方法;抽象类中可以包含抽象方法和非抽象方法,实现类需要重写抽象方法,可以选择性地重写非抽象方法。
④ 成员变量不同:接口中只能定义常量,而抽象类可以定义普通成员变量。
⑤ 构造方法不同:接口中不能定义构造方法,而抽象类可以定义构造方法。
⑥ 目的不同:接口用于定义一组规范,而抽象类用于被继承。 -
接口是否可继承接口?抽象类是否可实现(implements)接口?抽象类是否可继承实现类(concrete class)?
答:
接口是可以继承接口的,这个过程和类之间的继承类似,子接口继承父接口的方法和常量,并可以在子接口中添加新的方法和常量。抽象类可以通过实现接口来实现接口的方法,这个过程和普通类实现接口的过程一样。
抽象类也可以继承实现类,但是这种做法不太常见,因为实现类已经实现了接口中的方法,而抽象类的目的是为了让子类来实现,这样就会导致代码的重复和混淆。
-
接口可以有自己属性吗?
答:
在面向对象编程中,接口是一个纯粹的抽象概念,不应该包含实现代码或属性。接口只定义了类应该具有的方法和属性,但不提供它们的实现。因此,接口本身不应该有任何属性。 -
访问接口的默认方法如何使用?
答:
访问接口的默认方法可以通过实现该接口的类来调用。默认方法在接口中被定义,但是可以在实现类中被重写或者调用。如果实现类没有重写接口中的默认方法,那么默认方法将被继承并使用。
以下是访问接口默认方法的示例代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21interface MyInterface
{
default void myMethod()
{
System.out.println("这是一个默认方法。");
}
}
class MyClass implements MyInterface
{
// 此类不会重写接口中的默认方法。
}
public class Main
{
public static void main(String[] args)
{
MyClass obj = new MyClass();
obj.myMethod(); //输出:这是一个默认方法。
}
}在上面的代码中,我们定义了一个接口 MyInterface,其中包含了一个默认方法 myMethod()。然后,我们通过实现该接口的类 MyClass 来调用默认方法。在 main()方法中,我们创建了一个 MyClass 对象并调用了 myMethod()方法,输出了默认方法的内容。
-
内部类有哪几种?
答:
内部类分为四种:
① 成员内部类(也称为普通内部类)
② 静态内部类
③ 局部内部类
④ 匿名内部类 -
内部类的特点说一下。
答:
① 内部类是定义在另一个类内部的类,在外部类的范围内声明,但是不能独立存在。
② 内部类可以访问外部类的所有成员,包括私有成员。
③ 内部类可以使用外部类的引用,通过 this 关键字来访问外部类的成员。
④ 内部类可以被 private、protected、public 和 static 修饰,可以作为外部类的成员或局部变量。
⑤ 内部类可以继承其他类或实现接口,可以被其他类继承或实现。
⑥ 内部类可以访问外部类的私有构造方法,可以用来实现单例模式。
⑦ 内部类可以被用来实现回调机制,通过实现接口来实现回调函数。 -
枚举可以继承吗?
答:
枚举类型不能被继承,因为它们已经是最终的类型。枚举类型是一种特殊的值类型,它们的值是固定的且不可修改,因此没有必要对其进行继承。 -
Java 基本类型与包装类的区别?
答:
Java 基本类型是指 Java 语言中最基本的数据类型,包括整数类型、浮点数类型、字符类型和布尔类型,其值是直接存储在内存中的。而包装类是一种特殊的类,用于将基本类型转换为对象,以便在面向对象的环境中使用。包装类提供了一些方法,使得基本类型可以像对象一样进行操作。Java 基本类型与包装类的区别主要有以下几点:
① 基本类型的变量直接存储值,而包装类的对象存储的是值的引用。
② 基本类型的变量在内存中占用的空间比包装类的对象小。
③ 基本类型的变量不能为 null,而包装类的对象可以为 null。
④ 基本类型的变量不能调用方法,而包装类的对象可以调用方法。
⑤ 基本类型的变量可以直接进行算术运算,而包装类的对象需要通过方法进行运算。
⑥ 基本类型的变量可以直接赋值,而包装类的对象需要使用构造方法或 valueOf()方法进行赋值。
⑦ 基本类型的变量在方法中传递时是按值传递,而包装类的对象在方法中传递时是按引用传递。 -
谈谈你对面向对象的理解?
答:
面向对象是一种编程范式,它将现实世界中的事物抽象成对象,并将对象之间的关系封装成类,从而实现程序的模块化、复用和扩展。面向对象的编程主要基于三个核心概念:封装、继承和多态。封装是指将数据和行为封装在一个对象中,对外部只暴露必要的接口,隐藏内部实现细节,从而保证数据的安全性和可靠性。
继承是指一个类可以继承另一个类的属性和方法,从而减少代码的重复和冗余,提高代码的复用性和可维护性。
多态是指同一种行为具有不同的表现形式,不同的对象可以对同一消息作出不同的响应,从而增强代码的灵活性和可扩展性。
面向对象的编程思想可以使程序更加易于理解、扩展和维护,同时也可以提高代码的可复用性和可测试性,因此在现代软件开发中得到了广泛的应用。
-
面向对象的特征有哪些方面?
答:
面向对象的特征有以下几个方面:
① 封装性:将数据和操作数据的方法封装在一起,对外部隐藏其内部实现细节,只提供公共接口,以保证数据的安全性和完整性。
② 继承性:通过继承机制,子类可以继承父类的属性和方法,从而减少重复代码,提高代码的复用性和可维护性。
③ 多态性:同一种类的对象在不同的情况下表现出不同的行为,即一个方法可以有多个不同的实现方式,提高了代码的灵活性和可扩展性。
④ 抽象性:通过抽象类和接口,将对象的共性抽象出来,从而使得代码更加简洁、易于理解和维护。
⑤ 组合性:通过将多个对象组合在一起,形成一个更加复杂的对象,从而提高了代码的可拓展性和可复用性。
Java 基础 第 3 阶段:高级应用——尚硅谷学习笔记(含面试题) 2023 年
第 9 章 异常处理
9.1 异常的概述
9.1.1 什么是异常?
指的是程序在执行过程中,出现的非正常情况,如果不处理最终会导致 JVM 的非正常停止。
9.1.2 异常的抛出机制
Java 中把不同的异常用不同的类表示,一旦发生某种异常,就创建该异常类型的对象,并且抛出(throw)。
然后程序员可以捕获(catch)到这个异常对象,并处理。如果没有捕获(catch)这个异常对象,那么这个异常对象将会导致程序终止。
9.1.3 如何对待异常
对于程序出现的异常,一般有两种解决方法:
- 一是遇到错误就终止程序的运行。
- 另一种方法是程序员在编写程序时,就充分考虑到各种可能发生的异常和错误,极力预防和避免。实在无法避免的,要编写相应的代码进行异常的检测、以及异常的处理,保证代码的健壮性。
9.2 异常的体系结构及常见的异常
9.2.1 Throwable
-
java.lang.Throwable:异常体系的根父类。
-
Throwable 中的常用方法:
- public void printStackTrace():
打印异常的详细信息。
包含了异常的类型、异常的原因、异常出现的位置、在开发和调试阶段都得使用 printStackTrace()。 - public String getMessage():
获取发生异常的原因。
- public void printStackTrace():
9.2.2 Error 和 Exception
-
Throwable 可分为两类:
Error 和 Exception。
分别对应着 java.lang.Error 与 java.lang.Exception 两个类。 -
Error:
Java 虚拟机无法解决的严重问题。
如:
JVM 系统内部错误、资源耗尽等严重情况。
一般不编写针对性的代码进行处理。- 例如:
StackOverflowError(栈内存溢出)和 OutOfMemoryError(堆内存溢出,简称 OOM)。
- 例如:
-
Exception:
其它因编程错误或偶然的外在因素导致的一般性问题,需要使用针对性的代码进行处理,使程序继续运行。否则一旦发生异常,程序也会挂掉。- 例如:
空指针访问。
试图读取不存在的文件。
网络连接中断。
数组角标越界。
- 例如:
9.3 编译时异常和运行时异常
Java 程序的执行分为编译时过程和运行时过程。有的错误只有在运行时才会发生。
- 比如:
除数为 0,数组下标越界等。
因此,根据异常可能出现的阶段,可以将异常分为:
- 编译时期异常(即 checked 异常、受检异常):
在代码编译阶段,编译器就能明确警
示当前代码可能发生(不是一定发生)xx 异常,并明确督促程序员提前编写处理它的代码。如果程序员没有编写对应的异常处理代码,则编译器就会直接判定编译失败,从而不能生成字节码文件。通常,这类异常的发生不是由程序员的代码引起的,
或者不是靠加简单判断就可以避免的。- 例如:
FileNotFoundException(文件找不到异常)。
- 例如:
- 运行时期异常(即 runtime 异常、unchecked 异常、非受检异常):
在代码编译阶段,编译器完全不做任何检查,无论该异常是否会发生,编译器都不给出任何提示。只有等代码运行起来并确实发生了 xx 异常,它才能被发现。通常,这类异常是由程序员的代码编写不当引起的,只要稍加判断,或者细心检查就可以避免。- 例如:
java.lang.RuntimeException:类及它的子类都是运行时异常。- 比如:
ArrayIndexOutOfBoundsException:
数组下标越界异常。
ClassCastException:
类型转换异常。
- 比如:
- 例如:
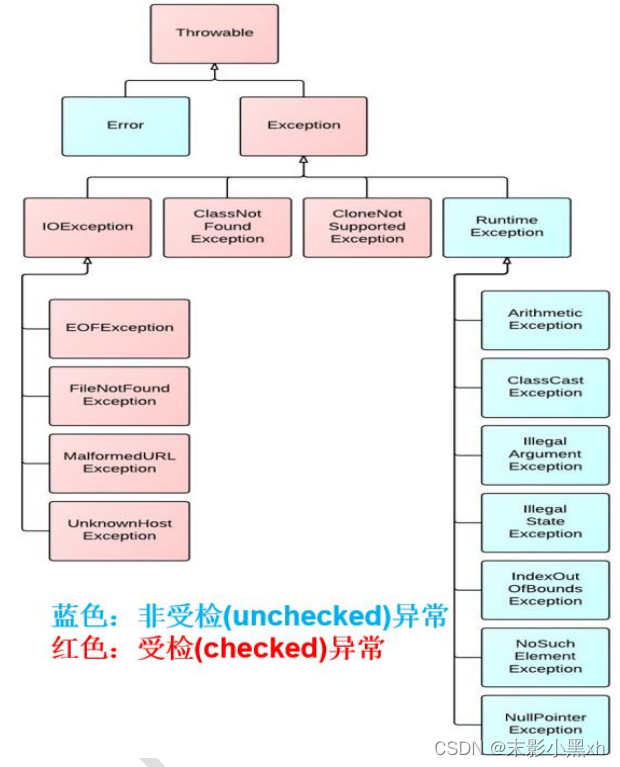
9.4 异常处理的方式
9.4.1 异常处理概述
-
过程 1:“抛”
- “自动抛” : 程序在执行的过程当中,一旦出现异常,就会在出现异常的代码处,自动生成对应异常类的对象,并将此对象抛出。
- “手动抛” :程序在执行的过程当中,不满足指定条件的情况下,我们主动的使用"throw + 异常类的对象"方式抛出异常对象。
-
过程 2:“抓”
- 狭义上讲:try-catch 的方式捕获异常,并处理。
- 广义上讲:把“抓”理解为“处理”。则此时对应着异常处理的两种方式:
① try-catch-finally
② throws
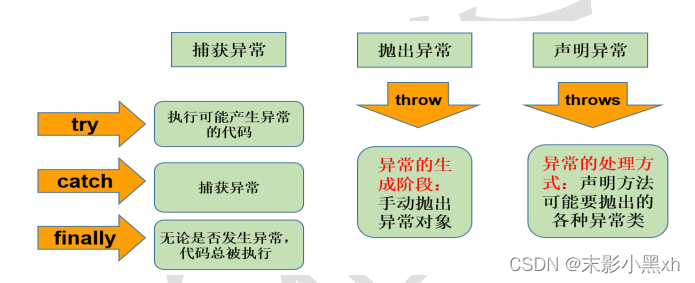
9.4.2 方式 1:捕获异常(try-catch-finally)
try-catch-finally 语法格式:
1 | try |
try-catch-finally 使用细节:
- 将可能出现异常的代码声明在 try 语句中。一旦代码出现异常,就会自动生成一个对应异常类的对象。并将此对象抛出。
- 针对于 try 中抛出的异常类的对象,使用之后的 catch 语句进行匹配。一旦匹配上,就进入 catch 语句块进行处理。
- 一旦处理结束,代码就可继续向下执行。
catch 中异常处理的方式:
- 自己编写输出的语句。
- printStackTrace():打印异常的详细信息。 (推荐)
- getMessage():获取发生异常的原因。
finally 的使用说明:
- finally 的理解:
我们将一定要被执行的代码声明在 finally 结构中。 - 什么样的代码我们一定要声明在 finally 中呢?
- 我们在开发中,有一些资源(比如:输入流、输出流,数据库连接、Socket 连接等资源),在使用完以后,必须显式的进行关闭操作,否则,GC 不会自动的回收这些资源。进而导致内存的泄漏。
- 为了保证这些资源在使用完以后,不管是否出现了未被处理的异常的情况下,这些资源能被关闭。我们必须将这些操作声明
在 finally 中。
9.4.3 方式 2:声明抛出异常类型(throws)
throws 语法格式:
1 | 修饰符 返回值类型 方法名(参数) throws 异常类名 1,异常类名 2... |
是否真正处理了异常?
- 从编译是否能通过的角度看,给出了异常万一出现时候的解决方案。此方案就是,继续向上抛出(throws)。
- 但是,此 throws 的方式,仅是将可能出现的异常抛给了此方法的调用者。此调用者仍然需要考虑如何处理相关异常。从这个角度来看,throws 的方式不算是真正意义上处理了异常。
方法的重写 throws 的要求:
- 子类重写的方法抛出的异常类型可以与父类被重写的方法抛出的异常类型相同,或是父类被重写的方法抛出的异常类型的子类。
9.4.4 如何选择异常处理的两种方式?
- 如果程序代码中,涉及到资源的调用(流、数据库连接、网络连接等),则必须考虑使用 try-catch-finally 来处理,保证不出现内存泄漏。
- 如果父类被重写的方法没有 throws 异常类型,则子类重写的方法中如果出现异常,只能考虑使用 try-catch-finally 进行处理,不能 throws。
- 开发中,方法 a 中依次调用了方法 b,c,d 等方法,方法 b,c,d 之间是递进关系。此时,如果方法 b,c,d 中有异常,我们通常选择使用 throws,而方法 a 中通常选择使用 try-catch-finally。
9.5 手动 throw 异常对象
Java 中异常对象的生成有两种方式:
- 由虚拟机自动生成:
程序运行过程中,虚拟机检测到程序发生了问题,那么针对当前代码,就会在后台自动创建一个对应异常类的实例对象并抛出。 - 由开发人员手动创建:
new 异常类型(实参列表);
如果创建好的异常对象不抛出对程序没有任何影响,和创建一个普通对象一样,但是一旦 throw 抛出,就会对程序运行产生影响了。
9.6 自定义异常类
9.6.1 为什么需要自定义异常类
- Java 中不同的异常类,分别表示着某一种具体的异常情况。那么在开发中总是有些异常情况是核心类库中没有定义好的,此时我们需要根据自己业务的异常情况来定义异常类。
- 例如年龄负数问题,考试成绩负数问题,某员工已在团队中等。
9.6.2 如何自定义异常类
要继承一个异常类型:
- 自定义一个编译时异常类型:
自定义类继承 java.lang.Exception。 - 自定义一个运行时异常类型:
自定义类继承 java.lang.RuntimeException。
建议大家提供至少两个构造器,一个是无参构造,一个是(String message)构造器。
自定义异常需要提供 serialVersionUID。
9.7 企业真题
-
Java 的异常体系简单介绍下。
答:
Java 的异常体系是指 Java 语言中用于处理程序运行时错误的一组类和接口,它们构成了一个层次化的结构。在 Java 中,异常被定义为一种表示程序运行时错误的对象,它们可以由系统或程序员自己抛出,被程序的调用栈捕获并处理。Java 的异常体系主要包括以下几个部分:
① Throwable 类:Throwable 是所有异常类的父类,它定义了常见的异常处理方法,如 getMessage()、printStackTrace()等。
② Error 类:Error 是一种表示严重的系统级错误的异常,如 OutOfMemoryError、StackOverflowError 等,程序一般无法恢复。
③ Exception 类:Exception 是一种表示程序运行时错误的异常,它可以被程序处理并恢复。Exception 又分为两种:
RuntimeException 类:RuntimeException 是一种表示程序逻辑错误的异常,如 NullPointerException、ArrayIndexOutOfBoundsException 等。
非 RuntimeException 类:非 RuntimeException 是一种表示程序外部错误的异常,如 IOException、SQLException 等。
④ Checked 异常:Checked 异常是指在编译时必须处理的异常,如 IOException、SQLException 等。
⑤ Unchecked 异常:Unchecked 异常是指在编译时不必处理的异常,如 NullPointerException、ArrayIndexOutOfBoundsException 等。Java 的异常体系为程序员提供了一种有效的处理程序运行时错误的方式,使得程序的稳定性和可靠性得到提高。
-
Java 异常处理机制?
答:
两种处理方案:try-catch-finally、throws。Java 异常处理机制是一种用于处理程序运行时错误的机制。当程序出现错误时,会抛出一个异常对象,这个异常对象可以被程序捕获并进行处理。Java 中的异常分为两种:受检异常和非受检异常。
受检异常(Checked Exception)必须在方法签名中声明,并且在调用该方法时必须进行处理,否则编译器会报错。常见的受检异常有 IOException、SQLException 等。
非受检异常(Unchecked Exception)不需要在方法签名中声明,也不需要进行处理。常见的非受检异常有 NullPointerException、ArrayIndexOutOfBoundsException 等。
Java 中的异常处理机制主要包括 try-catch-finally 语句块和 throw 语句。try-catch-finally 语句块用于捕获和处理异常,throw 语句用于抛出异常。在 try 块中执行代码,如果发生异常则进入 catch 块,如果没有发生异常则跳过 catch 块。无论是否发生异常,finally 块中的代码都会执行。
-
异常的两种类型,Error 和 Exception 的区别?
答:
Error 和 Exception 都是 Java 中的 Throwable 类的子类,但它们之间有一些区别。Error 是指 JVM 无法处理的严重问题,通常是由于系统资源耗尽或其他不可恢复的错误导致的。例如,OutOfMemoryError,StackOverflowError 等。Error 通常是不可处理的,程序应该尽可能地避免出现这种情况。
Exception 是指可以被程序处理的异常。它们通常由程序错误或意外情况引起,例如输入无效,文件不存在等。Exception 分为两种类型:checked exception 和 unchecked exception。checked exception 是在编译时就可以被检测到的异常,必须在代码中处理或声明抛出。unchecked exception 是在运行时才能被检测到的异常,不需要在代码中处理或声明抛出。
总之,Error 是无法处理的异常,而 Exception 是可以被处理的异常。
-
运行时异常与一般异常有何异同?
答:
运行时异常和一般异常的主要区别在于编译期检查和处理的时机不同。一般异常(Checked Exception)必须在编译期间显式地捕获和处理,否则代码就无法编译通过。这种异常通常是由于外部因素导致的,例如文件不存在、网络连接失败等,程序员需要在代码中显式地处理这些异常情况。
而运行时异常(Unchecked Exception)则不需要在编译期间显式地捕获和处理,可以在运行期间由虚拟机自动抛出。这种异常通常是由于程序逻辑错误导致的,例如空指针异常、数组越界异常等。程序员可以通过编写正确的代码来避免这些异常的发生,但是如果发生了,通常也无法通过捕获和处理来修复程序的错误。
因此,一般异常通常是由程序员自己引起,并需要在代码中显式地处理;而运行时异常通常是由程序逻辑错误引起的,程序员需要通过编写正确的代码来避免这些异常的发生。
-
说几个你常见到的异常?
答:
① NullPointerException:当调用一个空对象的方法或访问其属性时抛出。
② ArrayIndexOutOfBoundsException:当访问数组元素超出其范围时抛出。
③ ClassCastException:当试图将一个对象强制转换为不兼容的类型时抛出。
④IllegalArgumentException:当传递的参数不符合方法要求时抛出。
⑤ IOException:当发生输入/输出异常时抛出。
⑥ FileNotFoundException:当尝试打开不存在的文件时抛出。
⑦ ArithmeticException:当发生算术错误时抛出,如除以零。
⑧ InterruptedException:当线程在等待或睡眠时被中断时抛出。
⑨ UnsupportedOperationException:当不支持请求的操作时抛出。
⑩ SQLException:当访问数据库时发生错误时抛出。 -
说说 final、finally、finalize 的区别?
答:
final 是 Java 中的关键字,可以用来修饰类、方法和变量。当一个类被声明为 final 时,它不能被继承;当一个方法被声明为 final 时,它不能被重写;当一个变量被声明为 final 时,它的值不能被修改。finally 是 Java 中的关键字,用于定义一个代码块,无论是否发生异常,该代码块中的代码都会被执行。通常用于释放资源、关闭连接等操作。
finalize 是 Java 中的 Object 类中的一个方法,用于在对象被垃圾回收器回收之前执行一些清理操作。一般不建议在代码中显式调用该方法,而是让垃圾回收器自动调用。
-
如果不使用 try-catch,程序出现异常会如何?
答:
如果不使用 try-catch,程序出现异常会导致程序崩溃,并在控制台输出异常信息。这可能会导致数据丢失,影响程序的正常运行。使用 try-catch 可以捕获异常并进行处理,避免程序崩溃,保证程序的稳定性和可靠性。 -
try-catch 捕捉的是什么异常?
答:
try-catch 可以捕捉任何类型的异常,包括系统异常、运行时异常和自定义异常。 -
如果执行 finally 代码块之前方法返回了结果或者 jvm 退出了,这时 finally 块中的代码还会执行吗?
答:
如果方法返回了结果或者 JVM 退出了,finally 块中的代码也会执行。finally 块是用来确保在任何情况下都会执行特定的代码,无论是正常情况下还是出现异常的情况下。因此,即使方法返回了结果或者 JVM 退出了,finally 块中的代码也会被执行。特别的,如果在方法中调用了 System.exit(0),JVM 会立即退出,finally 块中的代码将不会执行。因为 System.exit(0)会直接终止 JVM,包括所有线程的执行,因此 finally 块中的代码也无法执行。
-
在 try 语句中有 return 语句,最后写 finally 语句,finally 语句中的的代码会不会执行?何时执行?如果执行是在 return 前还是后?
答:
在 try 语句中有 return 语句时,finally 语句中的代码一定会执行。finally 语句中的代码会在 return 语句执行之前执行。即使在 try 语句块中使用了 return 语句,finally 语句中的代码也会被执行,确保代码块中的资源被正确释放。 -
捕获异常在 catch 块里一定会进入 finally 吗?catch 里能 return 吗?catch 里 return 还会进 finally 吗?在 try 里 return 是什么情况?
答:
捕获异常在 catch 块里不一定会进入 finally,只有在 try 或 catch 块中有 return、throw 或异常抛出时,才会进入 finally 块。catch 里可以 return,但是要注意在 return 之前可能需要释放资源或做一些清理工作。catch 里 return 不会进入 finally。
在 try 里 return 时,如果 try 块中的代码执行完毕并成功返回,则会直接跳出 try 块并返回值,不会进入 finally。但是如果 try 块中的代码抛出异常,则会先进入 catch 块,处理完异常后再进入 finally 块。
-
throw 和 throws 的区别?
答:
throw 和 throws 是 Java 中的关键字,用于异常处理。throw 用于手动抛出一个异常,它通常用于方法体内部,用于抛出一个异常对象。例如:
1
2
3
4
5
6
7public void method()
{
if (somethingIsWrong)
{
throw new MyException("出了问题。");
}
}在上面的例子中,如果 somethingIsWrong 为 true,就会抛出一个 MyException 异常。
throws 则用于方法声明上,用于声明该方法可能会抛出哪些异常。例如:
1
2
3
4public void method() throws MyException
{
// 做一些可能引发MyException的事情
}在上面的例子中,方法 method 可能会抛出一个 MyException 异常,因此在方法声明上使用了 throws 关键字。
总结:
throw 用于抛出一个异常对象,通常用于方法体内部。
throws 用于方法声明上,用于声明该方法可能会抛出哪些异常。 -
子类重写父类抛出异常的方法,能否抛出比父类更高级别的异常类?
答:
不可以。子类重写父类抛出异常的方法时,抛出的异常类必须是父类方法抛出异常类的子类或者相同的异常类。抛出更高级别的异常类会破坏异常处理机制的完整性,可能导致程序无法正常处理异常。 -
如何自定义一个异常?
答:
在 Java 中,我们可以通过继承 Exception 或 RuntimeException 来自定义一个异常类。其中,Exception 表示编译时异常,必须在方法声明中抛出或捕获处理;而 RuntimeException 表示运行时异常,可以不在方法声明中抛出或捕获处理。我们一般建议自定义异常类时继承 Exception。自定义异常类需要满足以下要求:
① 继承 Exception 或 RuntimeException。
② 提供至少两个构造方法,一个是无参构造方法,一个是带有 String 参数的构造方法,用于传递异常信息。
③ 建议为异常类提供 serialVersionUID,用于序列化和反序列化操作。
下面是一个自定义异常类的示例代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14public class MyException extends Exception
{
private static final long serialVersionUID = 1L;
public MyException()
{
super();
}
public MyException(String message)
{
super(message);
}
}使用自定义异常类时,可以在方法声明中抛出异常,并在方法体中使用 throw 语句抛出自定义异常。例如:
1
2
3
4
5public void doSomething() throws MyException
{
// 做点什么
throw new MyException("出了问题");
}在调用该方法时,需要使用 try-catch 语句捕获该异常或继续向上抛出该异常。例如:
1
2
3
4
5
6
7
8
9
10
11public static void main(String[] args)
{
try
{
doSomething();
}
catch (MyException e)
{
e.printStackTrace();
}
}
第 10 章 多线程
10.1 程序、进程与线程
程序(program):为完成特定任务,用某种语言编写的一组指令的集合。即指一段静态的代码。
进程(process):程序的一次执行过程,或是正在内存中运行的应用程序。程序是静态的,进程是动态的。
进程作为操作系统调度和分配资源的最小单位。
线程(thread):进程可进一步细化为线程,是程序内部的一条执行路径。
线程作为 CPU 调度和执行的最小单位。
线程调度策略:
- 分时调度:所有线程轮流使用 CPU 的使用权,并且平均分配每个线程占用 CPU 的时间。
- 抢占式调度:让优先级高的线程以较大的概率优先使用 CPU。如果线程的优先级相同,那么会随机选择一个(线程随机性),Java 使用的为抢占式调度。
单核 CPU 与多核 CPU。
并行与并发:
-
并行(parallel):指两个或多个事件在同一时刻发生(同时发生)。指在同一时刻,有多条指令在多个 CPU 上同时执行。比如:多个人同时做不同的事。
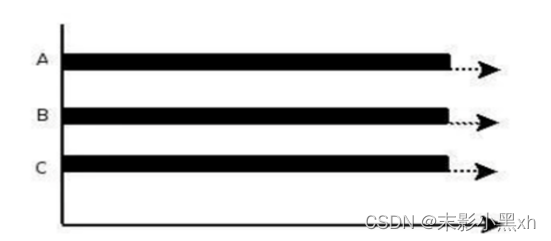
-
并发(concurrency):指两个或多个事件在同一个时间段内发生。即在一段时间内,有多条指令在单个 CPU 上快速轮换、交替执行,使得在宏观上具有多个进程同
时执行的效果。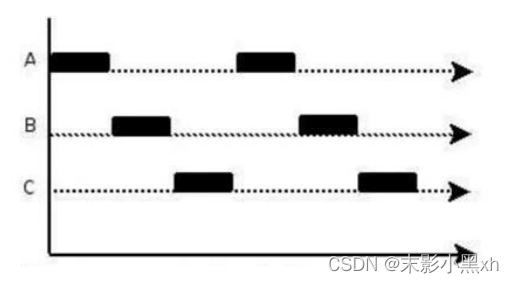
10.2 创建多线程
10.2.1 方式 1:继承 Thread 类
Java 通过继承 Thread 类来创建并启动多线程。
步骤如下:
① 定义 Thread 类的子类,并重写该类的 run()方法,该 run()方法的方法体就代表了线程需要完成的任务。
② 创建 Thread 子类的实例,即创建了线程对象。
③ 调用线程对象的 start()方法来启动该线程。
代码示例:
1 | // 自定义线程类 |
10.2.2 方式 2:实现 Runnable 接口
Java 有单继承的限制,当我们无法继承 Thread 类时,那么该如何做呢?在核心类库中提供了 Runnable 接口,我们可以实现 Runnable 接口,重写 run()方法,然后再通过 Thread 类的对象代理启动和执行我们的线程体 run()方法。
步骤如下:
① 定义 Runnable 接口的实现类,并重写该接口的 run()方法,该 run()方法的方法体同样是该线程的线程执行体。
② 创建 Runnable 实现类的实例,并以此实例作为 Thread 的 target 参数来创建 Thread 对象,该 Thread 对象才是真正 的线程对象。
③ 调用线程对象的 start()方法,启动线程。调用 Runnable 接口实现类的 run 方法。
代码示例:
1 | public class MyRunnable implements Runnable |
10.2.3 方式 3:实现 Callable 接口 (jdk5.0 新增)
与使用 Runnable 相比, Callable 功能更强大些。
- 相比 run()方法,可以有返回值。
- 方法可以抛出异常。
- 支持泛型的返回值(需要借助 FutureTask 类,获取返回结果)。
Future 接口:
- 可以对具体 Runnable、Callable 任务的执行结果进行取消、查询是否完成、获取结果等。
- FutureTask 是 Futrue 接口的唯一的实现类。
- FutureTask 同时实现了 Runnable, Future 接口。它既可以作为 Runnable 被线程执行,又可以作为 Future 得到 Callable 的返回值
缺点:在获取分线程执行结果的时候,当前线程(或是主线程)受阻塞,效率较低。
代码示例:
1 | // 1.创建一个实现 Callable 的实现类 |
10.2.4 方式 4:使用线程池(jdk5.0 新增)
现有问题:
- 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的效率,因为频繁创建线程和销毁线程需要时间。
- 那么有没有一种办法使得线程可以复用,即执行完一个任务,并不被销毁,而是可以继续执行其他的任务?
思路:
- 提前创建好多个线程,放入线程池中,使用时直接获取,使用完放回池中。可以避免频繁创建销毁、实现重复利用。类似生活中的公共交通工具。
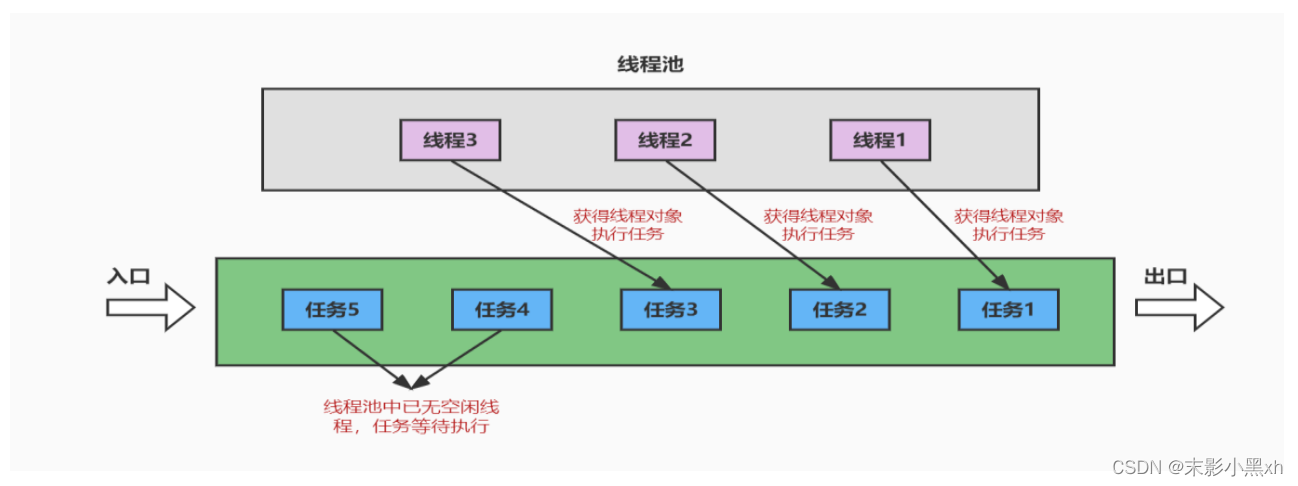
代码示例:
1 | class NumberThread1 implements Runnable |
10.3 Thread 类的常用方法
10.3.1 构造器
- public Thread() :分配一个新的线程对象。
- public Thread(String name) :分配一个指定名字的新的线程对象。
- public Thread(Runnable target) :指定创建线程的目标对象,它实现了 Runnable 接口中的 run 方法。
- public Thread(Runnable target,String name) :分配一个带有指定目标新的线程对象并指定名字。
10.3.2 常用方法
- public void run() :此线程要执行的任务在此处定义代码。
- public void start() :导致此线程开始执行; Java 虚拟机调用此线程的 run 方法。
- public String getName() :获取当前线程名称。
- public void setName(String name):设置该线程名称。
- public static Thread currentThread() :返回对当前正在执行的线程对象的引用。在 Thread 子类中就是 this,通常用于主线程和 Runnable 实现类。
- public static void sleep(long millis) :使当前正在执行的线程以指定的毫秒数暂停(暂时停止执行)。
- public static void yield():yield 只是让当前线程暂停一下,让系统的线程调度器重新调度一次,希望优先级与当前线程相同或更高的其他线程能够获得执行机会,但是这个不能保证,完全有可能的情况是,当某个线程调用了 yield 方法暂停之后,线程调度器又将其调度出来重新执行。
- public final boolean isAlive():测试线程是否处于活动状态。如果线程已经启动且尚未终止,则为活动状态。
- void join() :等待该线程终止。
- void join(long millis) :等待该线程终止的时间最长为 millis 毫秒。如果 millis 时间到,将不再等待。
- void join(long millis, int nanos) :等待该线程终止的时间最长为 millis 毫秒 + nanos 纳秒。
- public final void stop():已过时,不建议使用。强行结束一个线程的执行,直接进入死亡状态。run()即刻停止,可能会导致一些清理性的工作得不到完成,如文件,数据库等的关闭。同时,会立即释放该线程所持有的所有的锁,导致数据得不到同步的处理,出现数据不一致的问题。
- void suspend() / void resume() : 这两个操作就好比播放器的暂停和恢复。二者必须成对出现,否则非常容易发生死锁。suspend()调用会导致线程暂停,但不会释放任何锁资源,导致其它线程都无法访问被它占用的锁,直到调用 resume()。已过时,不建议使用。
- setDaemon(true):调用 setDaemon(true)方法可将指定线程设置为守护线程。
10.3.3. 线程的优先级
-
Thread 类内部声明的三个常量:
- MAX_PRIORITY(10):最高优先级。
- MIN _PRIORITY (1):最低优先级。
- NORM_PRIORITY (5):普通优先级,默认情况下 main 线程具有普通优先级。
-
getPriority():获取线程的优先级。
-
setPriority():设置线程的优先级,范围[1,10]。
10.4 多线程的生命周期
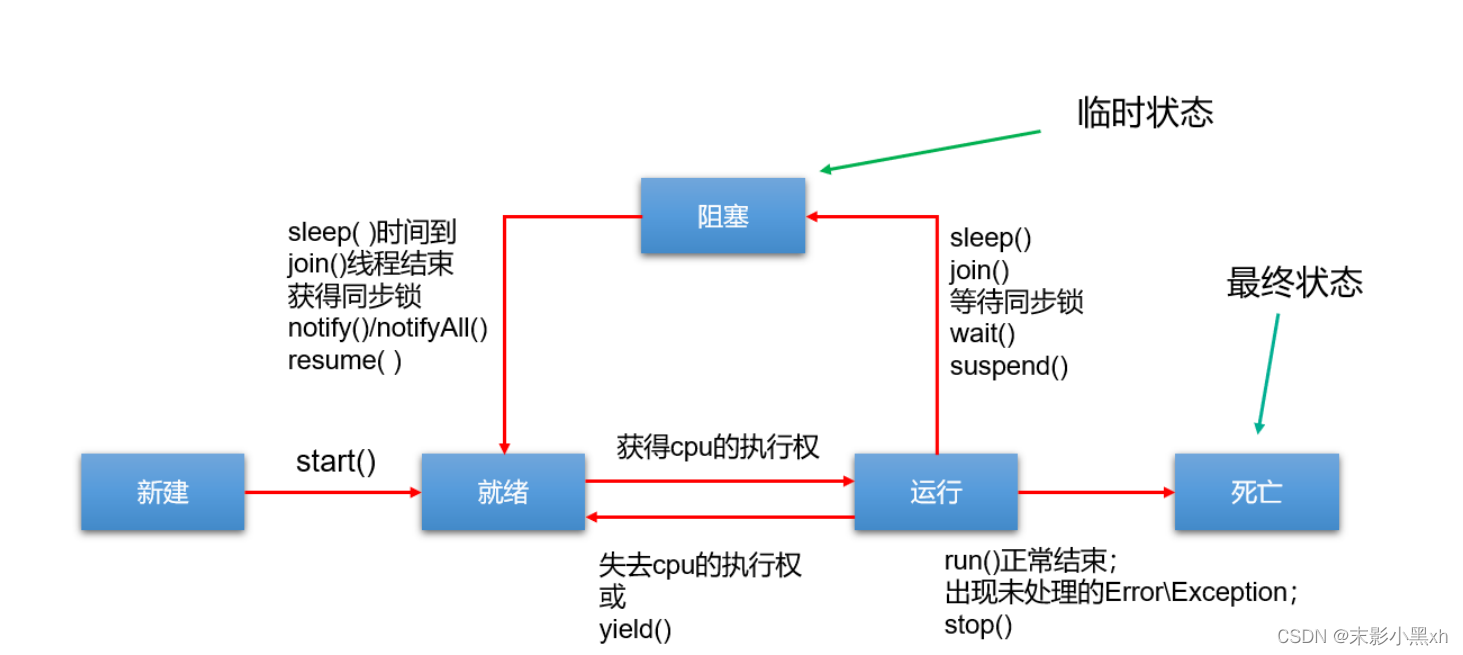
10.4.1 jdk5.0 之前的线程的生命周期
线程的生命周期有五种状态:新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)、死亡(Dead)。CPU 需要在多条线程之间切换,于是线程状态会多次在运行、阻塞、就绪之间切换。
10.4.2 jdk5.0 之后的线程的生命周期
jdk5.0 及之后,Thread 类中定义了一个内部类 State。
1 | public enum State |
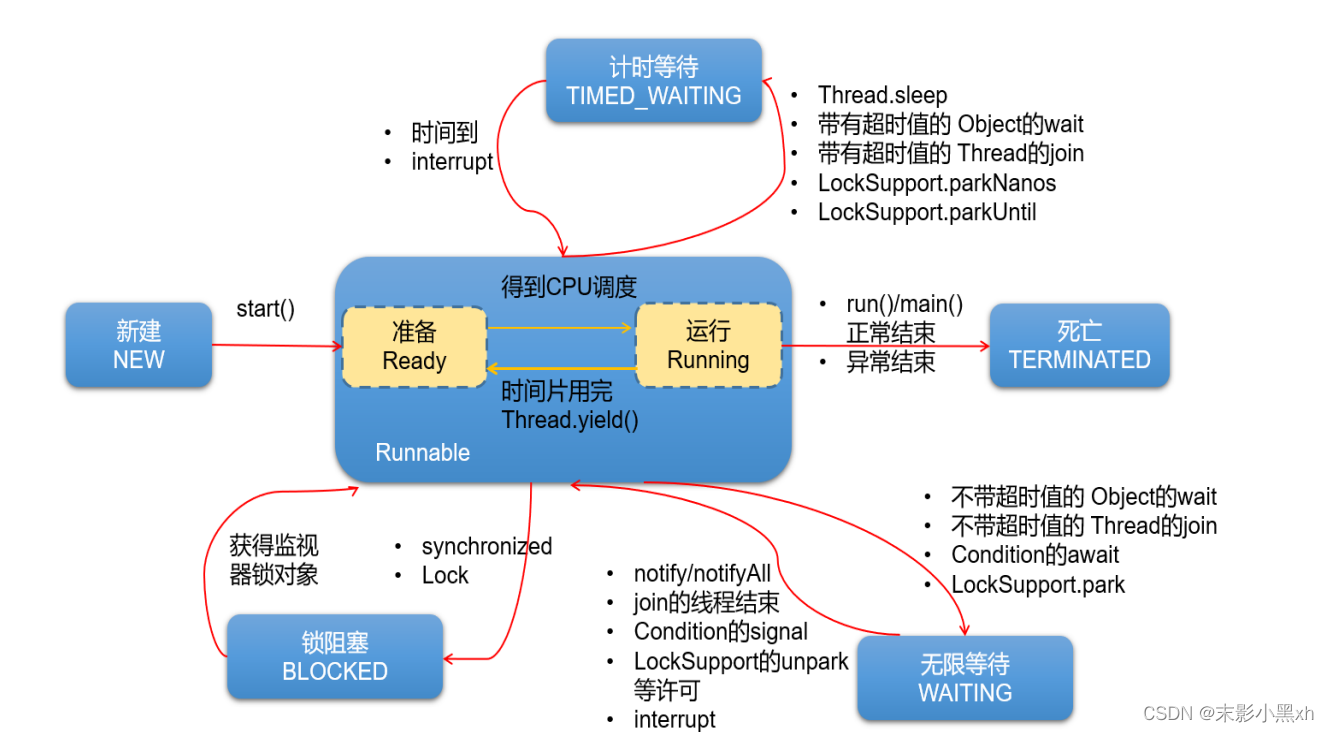
10.5 线程安全问题
什么是线程的安全问题?多个线程操作共享数据,就有可能出现安全问题。
10.5.1 同步机制解决线程安全问题
要解决多线程并发访问一个资源的安全性问题,也就是解决重复票与不存在票问题,Java 中提供了同步机制 (synchronized)来解决。
10.5.2 同步机制解决线程安全问题的原理
同步机制的原理,其实就相当于给某段代码加“锁”,任何线程想要执行这段代码,都要先获得“锁”,我们称它为同步锁。
因为 Java 对象在堆中的数据分为分为对象头、实例变量、空白的填充。
对象头中包含:
- Mark Word:记录了和当前对象有关的 GC、锁标记等信息。
- 指向类的指针:每一个对象需要记录它是由哪个类创建出来的。
- 数组长度(只有数组对象才有)。
哪个线程获得了“同步锁”对象之后,”同步锁“对象就会记录这个线程的 ID,这样其他线程就只能等待了,除非这个线程”释放“了锁对象,其他线程才能重新获得/占用”同步锁“对象。
10.5.3 同步代码块
同步代码块:synchronized 关键字可以用于某个区块前面,表示只对这个区块的资源实行互斥访问。
语法格式:
1 | synchronized(同步锁) |
10.5.4 同步方法
同步方法:synchronized 关键字直接修饰方法,表示同一时刻只有一个线程能进入这个方法,其他线程在外面等着。
语法格式:
1 | public synchronized void method() |
10.5.5 同步锁机制
-
重点关注两个事:
- 共享数据及操作共享数据的代码。
- 同步监视器,即同步锁要保证唯一性。
-
在实现 Runnable 接口的方式中,同步监视器可以考虑使用:this。
-
在继承 Thread 类的方式中,同步监视器要慎用 this,可以考虑使用:当前类.class。
-
非静态的同步方法,默认同步监视器是 this
-
静态的同步方法,默认同步监视器是当前类本身。
10.5.6 Lock 锁(jdk5.0 新增)
与采用 synchronized 相比,Lock 可提供多种锁方案,更灵活、更强大。Lock 通过显式定义同步锁对象来实现同步。同步锁使用 Lock 对象充当。
java.util.concurrent.locks.Lock 接口是控制多个线程对共享资源进行访问的工具。锁提供了对共享资源的独占访问,每次只能有一个线程对 Lock 对象加锁,线程开始访问共享资源之前应先获得 Lock 对象。
在实现线程安全的控制中,比较常用的是 ReentrantLock,可以显式加锁、释放锁。
- ReentrantLock 类实现了 Lock 接口,它拥有与 synchronized 相同的并发性和内存语义,但是添加了类似锁投票、定时锁等候和可中断锁等候的一
些特性。此外,它还提供了在激烈争用情况下更佳的性能。
Lock 锁也称同步锁,加锁与释放锁方法,如下:
- public void lock() :加同步锁。
- public void unlock() :释放同步锁。
代码示例:
1 | class LockTest |
10.6 同步机制相关的问题
10.6.1 单例设计模式的线程安全问题
懒汉式单例模式的线程安全写法可以使用双重检查锁定(Double-Checked Locking)来实现。具体实现如下:
1 | public class Singleton |
在以上代码中,使用了双重检查锁定来确保线程安全。第一次检查用于判断 instance 是否已经存在,如果已经存在,则直接返回;否则进入临界区加锁。在加锁后,再次检查 instance 是否已经存在,防止多个线程同时进入第一次检查后的 if 语句块。如果 instance 仍然为 null,则创建一个新的实例。最后,返回 instance。同时,使用 volatile 关键字确保 instance 的可见性和顺序性,避免由于指令重排而导致的线程安全问题。
10.6.2 死锁
不同的线程分别占用对方需要的同步资源不放弃,都在等待对方放弃自己需要的同步资源,就形成了线程的死锁。
诱发死锁的原因:
- 互斥条件。
- 占用且等待。
- 不可抢夺(或不可抢占)。
- 循环等待。
- 以上 4 个条件,同时出现就会触发死锁。
解决死锁:
死锁一旦出现,基本很难人为干预,只能尽量规避。可以考虑打破上面的诱发条件。
- 针对条件 1:互斥条件基本上无法被破坏。因为线程需要通过互斥解决安全问题。
- 针对条件 2:可以考虑一次性申请所有所需的资源,这样就不存在等待的问题。
- 针对条件 3:占用部分资源的线程在进一步申请其他资源时,如果申请不到,就主动释放掉已经占用的资源。
- 针对条件 4:可以将资源改为线性顺序。申请资源时,先申请序号较小的,这样避免循环等待问题。
10.7 线程间的通信
- 在同步机制下,考虑线程间的通信。
- wait():
线程不再活动,不再参与调度,进入 wait set 中,因此不会浪费 CPU 资源,也不会去竞争锁了,这时的线程状态是 WAITING 或 TIMED_WAITING。它还要等着别的线程执行一个特别的动作,也即“通知(notify)”或者等待时间到,在这个对象上等待的线程从 wait set 中释放出来,重新进入到调度队列(ready queue)中。 - notify():则选取所通知对象的 wait set 中的一个线程释放。
- notifyAll():则释放所通知对象的 wait set 上的全部线程。
10.8 生产者与消费者问题
等待唤醒机制可以解决经典的“生产者与消费者”的问题。生产者与消费者问题(Producer-consumer problem),也称有限缓冲问题(Bounded-buffer problem),是一个多线程同步问题的经典案例。该问题描述了两个(多个)共享固定大小缓冲区的线程——即所谓的“生产者”和“消费者”——在实际运行时会发生的问题。
生产者的主要作用是生成一定量的数据放到缓冲区中,然后重复此过程。与此同时,消费者也在缓冲区消耗这些数据。该问题的关键就是要保证生产者不会在缓冲区满时加入数据,消费者也不会在缓冲区中空时消耗数据。
生产者与消费者问题中其实隐含了两个问题:
- 线程安全问题:因为生产者与消费者共享数据缓冲区,产生安全问题。不过这个问题可以使用同步解决。
- 线程的协调工作问题: - 要解决该问题,就必须让生产者线程在缓冲区满时等待(wait),暂停进入阻塞状态,等到下次消费者消耗了缓冲区中的数据的时候,通知(notify)正在等待的线程恢复到就绪状态,重新开始往缓冲区添加数据。同样,也可以让消费者线程在缓冲区空时进入等待(wait),暂停进入阻塞状态,等到生产
者往缓冲区添加数据之后,再通知(notify)正在等待的线程恢复到就绪状态。通过这样的通信机制来解决此类问题。
代码示例:
1 | public class ConsumerProducerTest |
10.9 企业真题
-
什么是线程?
答:
线程是操作系统能够进行运算调度的最小单位,它被包含在进程中,是进程中的实际运作单位。一个进程可以包含多个线程,每个线程之间可以共享进程的资源,如内存、文件句柄等,同时也可以拥有自己的独立资源,如程序计数器、寄存器等。线程可以在同一进程内并发执行,提高了程序的运行效率。 -
线程和进程有什么区别?
答:
① 定义:进程是计算机中正在运行的一个程序,它拥有自己的内存空间和系统资源,而线程是进程中的一个执行单元,一个进程可以包含多个线程。
② 资源占用:进程拥有独立的内存空间和系统资源,而线程共享所属进程的资源,包括内存、文件等。
③ 并发性:进程之间相互独立,互不干扰,而线程之间共享进程的资源,需要通过同步机制来保证并发性。
④ 切换开销:进程间切换需要保存和恢复进程的上下文,开销较大,而线程间切换只需要保存和恢复线程的上下文,开销较小。
⑤ 安全性:由于线程共享进程的资源,如果一个线程出现问题,可能会影响到整个进程的稳定性和安全性,而进程之间相互独立,一个进程出现问题不会影响其他进程的运行。
⑥ 独立性:进程之间可以独立运行,可以实现分布式计算和多任务处理,而线程依赖于进程,不能独立运行。
综上所述,进程和线程都是计算机中实现多任务处理的重要概念,它们各自有自己的特点和优势,应根据实际需求选择合适的方式来实现多任务处理。 -
多线程使用场景?
答:
① 处理大量数据:使用多线程可以同时处理多个数据,提高数据处理的速度。
② 并发访问:多线程可以同时访问同一个资源,提高资源的利用效率。
③ 服务器端编程:服务器需要同时处理多个客户端请求,使用多线程可以提高服务器的并发处理能力。
④ 图形界面程序:图形界面程序需要同时处理多个用户输入事件,使用多线程可以提高程序的响应速度。
⑤ 大规模计算:使用多线程可以同时进行多个计算任务,提高计算的效率。
⑥ 多媒体处理:多媒体处理需要同时进行多个任务,使用多线程可以提高处理速度。
⑦ 游戏开发:游戏需要同时处理多个角色的动作,使用多线程可以提高游戏的流畅度和响应速度。
⑧ 数据库操作:数据库需要同时处理多个查询和更新请求,使用多线程可以提高数据库的并发处理能力。 -
如何在 Java 中出实现多线程?
答:
① 继承 Thread 类并重写 run()方法。1
2
3
4
5
6
7
8
9
10
11
12public class MyThread extends Thread
{
public void run()
{
// 业务逻辑
}
}
// 启动线程
MyThread thread = new MyThread();
thread.start();② 实现 Runnable 接口并重写 run()方法。
1
2
3
4
5
6
7
8
9
10
11
12
13public class MyRunnable implements Runnable
{
public void run()
{
// 业务逻辑
}
}
// 启动线程
MyRunnable runnable = new MyRunnable();
Thread thread = new Thread(runnable);
thread.start();③ 实现 Callable 接口并重写 call()方法。
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class MyCallable implements Callable<String>
{
public String call() throws Exception
{
// 业务逻辑
return "Hello World!";
}
}
// 启动线程
MyCallable callable = new MyCallable();
Future<String> future = executor.submit(callable);
String result = future.get();④ 使用线程池
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34public class ThreadPoolExample
{
public static void main(String[] args)
{
// 创建一个固定大小的线程池,其中包含5个线程
ExecutorService executor = Executors.newFixedThreadPool(5);
// 提交10个任务给线程池执行
for (int i = 1; i <= 10; i++)
{
executor.submit(new Task(i));
}
// 关闭线程池
executor.shutdown();
}
// 定义一个任务类,实现Runnable接口
static class Task implements Runnable
{
private int taskId;
public Task(int taskId)
{
this.taskId = taskId;
}
public void run()
{
System.out.println("任务 " + taskId + " 正在线程中运行。 " + Thread.currentThread().getName());
}
}
} -
Thread 类中的 start()和 run()有什么区别?
答:
start()方法用于启动一个新的线程,而 run()方法只是普通的方法调用。当调用 start()方法时,系统会创建一个新的线程,并在该线程中执行 run()方法。如果直接调用 run()方法,那么该方法就会在当前线程中执行,不会创建新的线程。因此,如果想要实现多线程,必须使用 start()方法来启动新线程,而不是直接调用 run()方法。 -
启动一个线程是用 run()还是 start()?
答:
启动一个线程应该使用 start()方法,而不是直接调用 run()方法。因为直接调用 run()方法不会创建一个新的线程,而只是在当前线程中执行 run()方法的代码。而使用 start()方法会创建一个新的线程并在新线程中执行 run()方法的代码。这样可以避免阻塞当前线程的执行,提高程序的并发性能。 -
Java 中 Runnable 和 Callable 有什么不同?
答:
在 Java 中,Runnable 和 Callable 都是用来实现多线程的接口,但是它们有以下不同点:
① 返回值类型不同:Runnable 的 run()方法没有返回值,而 Callable 的 call()方法有返回值。
② 异常处理不同:Runnable 的 run()方法不能抛出 checked exception,但是 Callable 的 call()方法可以抛出 checked exception,需要在调用时进行处理。
③ 使用方式不同:Runnable 接口通常用于执行一些没有返回值的简单任务,而 Callable 接口通常用于执行一些有返回值的复杂任务,例如计算、查询等。
④ 使用线程池时不同:如果使用线程池来执行任务,Runnable 可以直接提交给线程池执行,但是 Callable 需要使用 Future 来获取返回值。总之,Runnable 和 Callable 都是用来实现多线程的接口,但是它们的使用方式和作用略有不同。
-
什么是线程池,为什么要使用它?
答:
线程池是一种管理和复用线程的机制,它可以在应用程序中预先创建一定数量的线程,并将这些线程放入一个池中,当需要执行任务时,从线程池中取出一个线程来执行任务,任务执行完毕后,该线程不被销毁,而是返回线程池等待下一次任务的到来。使用线程池的好处在于:
① 减少线程的创建和销毁次数,避免频繁创建和销毁线程对系统资源的消耗。
② 提高线程的复用率,使线程可以被重复利用,减少线程的阻塞等待时间。
③ 控制线程的数量,避免线程数量过多导致系统资源的浪费和线程调度的开销。
④ 提高系统的稳定性和可靠性,避免线程的崩溃和异常对系统的影响。
⑤ 提高程序的响应速度和吞吐量,提高程序的并发能力。 -
sleep() 和 yield()区别?
答:
sleep()和 yield()都是线程控制的方法,但它们的作用不同。
① sleep()会让当前线程进入阻塞状态,让出 CPU,不参与调度,直到休眠时间结束或被中断才会继续执行。sleep()方法是静态方法,可以通过 Thread 类直接调用。
② yield()会让当前线程让出 CPU,但是不会进入阻塞状态,而是重新回到就绪状态,等待线程调度器再次调度。yield()方法也是静态方法,可以通过 Thread 类直接调用。因此,sleep()和 yield()的区别在于 sleep()会让线程进入阻塞状态,而 yield()则不会。另外,sleep()方法可以指定休眠的时间,而 yield()方法则不可以。
-
线程创建的中的方法、属性?
答:
线程创建时可以指定以下方法和属性:方法:
① start():启动线程。
② run():线程的执行体,需要自行实现。
③ join():等待线程执行完毕。
④ interrupt():中断线程。属性:
① name:线程名字。
② daemon:是否为守护线程。
③ priority:线程优先级。
④ isAlive():线程是否处于活动状态。
⑤ isDaemon():线程是否为守护线程。
⑥ isInterrupted():线程是否被中断。 -
线程的生命周期?
答:
Java 中线程的生命周期包括以下五个状态:
① 新建状态(New):当线程对象被创建时,它处于新建状态。此时,线程还没有开始执行,也没有分配到系统资源。
② 就绪状态(Runnable):当线程调用 start()方法后,它进入就绪状态。此时,线程已经分配到了系统资源,但还没有开始执行。处于就绪状态的线程会等待 CPU 时间片的分配。
③ 运行状态(Running):当线程获得 CPU 时间片后,它进入运行状态。此时,线程开始执行 run()方法中的代码。
④ 阻塞状态(Blocked):线程在等待某个条件的时候,可能会进入阻塞状态。比如,线程在等待获取锁时,如果锁已经被其他线程占用,则该线程会进入阻塞状态。
⑤ 终止状态(Terminated):当线程执行完 run()方法中的代码后,它就进入了终止状态。此时,线程已经完成了它的任务,不再占用系统资源。 -
线程的基本状态以及状态之间的关系?
答:
线程有五种基本状态:
① 新建状态(New):当线程对象被创建时,它处于新建状态。
② 就绪状态(Runnable):当线程被启动后,它进入就绪状态,等待系统调度它运行。
③ 运行状态(Running):当线程被系统调度后,它进入运行状态,开始执行任务。
④ 阻塞状态(Blocked):当线程因为某些原因无法运行时,它进入阻塞状态。
⑤ 终止状态(Terminated):当线程执行完任务后,或者因为异常或其他原因被强制终止时,它进入终止状态。线程状态之间的关系如下:
① 新建状态可以转化为就绪状态。
② 就绪状态可以转化为运行状态。
③ 运行状态可以转化为就绪状态或阻塞状态。
④ 阻塞状态可以转化为就绪状态。
⑤ 运行状态或阻塞状态可以转化为终止状态。 -
stop()和 suspend()方法为何不推荐使用?
答:
stop()方法会立即停止线程,可能会导致线程资源无法释放,造成死锁或者数据不一致等问题,因此不推荐使用。suspend()方法会暂停线程,但是不会释放线程占用的资源,如果在暂停期间其他线程需要使用该资源,就会发生死锁等问题,因此也不推荐使用。同时,suspend()方法还可能导致线程状态不可预测,无法保证线程的正确性。
-
Java 线程优先级是怎么定义的?
答:
Java 线程优先级是通过整数来定义的,范围从 1 到 10。默认情况下,所有线程都具有相同的优先级,即 NORM_PRIORITY(5)。较高的优先级使线程更有可能在竞争资源时获得 CPU 时间,但不能保证高优先级的线程总是优先于低优先级的线程。线程优先级的设置可以使用 Thread 类的 setPriority()方法进行设置。 -
你如何理解线程安全的?线程安全问题是如何造成的?
答:
线程安全是指当多个线程同时访问同一个共享资源时,不会出现任何意外的结果,即程序执行的结果与单线程执行的结果是一致的。线程安全问题通常是由于多个线程同时访问同一个共享资源时,对该资源的读写操作没有得到正确的同步处理所导致的,例如在并发环境下访问同一个全局变量、共享缓存、共享文件等。这样可能会导致数据不一致、死锁、竞态条件等问题,从而影响程序的正确性和稳定性。为了解决线程安全问题,常见的做法是使用锁、信号量、原子操作等同步机制来保证多个线程对共享资源的访问是有序的,从而避免出现竞争条件和数据不一致的问题。 -
多线程共用一个数据变量需要注意什么?
答:
① 线程安全:多线程共用一个数据变量时,需要确保数据的安全性,即线程之间不能互相干扰或破坏数据。
② 同步机制:为了保证数据的正确性,需要使用同步机制,例如锁、信号量等,确保同一时间只有一个线程能够访问数据变量。
③ 内存可见性:多线程共用一个数据变量时,需要确保数据的内存可见性,即当一个线程修改了数据变量时,其他线程能够及时看到这个变化。
④ 死锁问题:当多个线程同时需要访问多个共用的数据变量时,可能会出现死锁问题。因此需要避免多个线程同时访问多个共用的数据变量。
⑤ 性能问题:多线程共用一个数据变量时,需要考虑线程之间的调度和竞争问题,以及锁的开销等因素,确保程序的性能。 -
多线程保证线程安全一般有几种方式?
答:
Java 多线程保证线程安全一般有以下几种方式:
① 同步代码块:使用 synchronized 关键字来同步代码块,使得多个线程在执行该代码块时只能有一个线程执行。
② 同步方法:将需要同步的方法声明为 synchronized 方法,同一时间只能有一个线程执行该方法。
③ Lock 锁:使用 Lock 接口提供的 lock()和 unlock()方法来实现同步,相比于 synchronized 关键字,Lock 锁提供了更灵活的同步方式。
④ volatile 关键字:使用 volatile 关键字来保证变量的可见性和禁止指令重排,从而保证多线程环境下变量的正确性。
⑤ 原子类:使用 Java 提供的原子类来保证操作的原子性,如 AtomicInteger、AtomicLong 等。
⑥ ThreadLocal 类:使用 ThreadLocal 类来实现线程本地变量,保证每个线程都有自己的变量副本,从而避免并发访问问题。
⑦ 并发容器:Java 提供了许多线程安全的容器类,如 ConcurrentHashMap、ConcurrentLinkedQueue 等,可以直接使用这些容器类来避免并发访问问题。 -
用什么关键字修饰同步方法?
答:
Java 中,可以使用 synchronized 关键字修饰同步方法。 -
synchronized 加载静态方法和普通方法区别?
答:
在 Java 中,synchronized 关键字可以用于修饰静态方法和普通方法,但它们之间有一些区别。对于静态方法,同步锁是当前类的 Class 对象。而对于普通方法,同步锁是当前实例对象。因此,如果一个线程访问一个静态 synchronized 方法,那么其他线程将不能访问该类的任何其他静态 synchronized 方法,但是可以访问该类的非静态 synchronized 方法。而如果一个线程访问一个非静态 synchronized 方法,那么其他线程将不能访问该实例的其他非静态 synchronized 方法,但是可以访问该类的所有静态 synchronized 方法。
因此,不同的方法使用不同的同步监视器,这是它们之间的区别。静态方法使用类的 Class 对象作为同步监视器,而普通方法使用实例对象作为同步监视器。
-
Java 中 synchronized 和 ReentrantLock 有什么不同?
答:
synchronized 和 ReentrantLock 都是用于实现线程同步的机制,但它们有以下不同:
① 性能:ReentrantLock 性能比 synchronized 更好,因为它是基于 CAS (Compare and Swap) 实现的,而 synchronized 是基于 JVM 实现的。在高并发情况下,ReentrantLock 的性能优势更加明显。
② 可中断性:ReentrantLock 具有可中断性,即当一个线程正在等待获取锁时,可以通过调用 lockInterruptibly() 方法来让该线程中断等待,而 synchronized 没有这个特性。
③ 公平锁:ReentrantLock 可以是公平锁,即按照等待时间的先后顺序来获取锁,而 synchronized 只能是非公平锁。
④ 可重入性:synchronized 是可重入锁,即线程可以重复获取已经持有的锁,而 ReentrantLock 也是可重入锁。
⑤ 等待可中断:ReentrantLock 可以设置等待获取锁的超时时间,而 synchronized 没有这个特性。
⑥ 条件锁:ReentrantLock 可以通过 Condition 接口来实现条件锁,即只有满足某个条件时才能获取锁,而 synchronized 没有这个特性。综上所述,ReentrantLock 相对于 synchronized 更加灵活和强大,但使用起来也更加复杂,需要手动释放锁和处理异常等问题。在需要高并发性能和更多功能的场景下,可以选择使用 ReentrantLock。
-
当一个线程进入一个对象的一个 synchronized 方法后,其它线程是否可进入此对象的其它方法?
答:
当一个线程进入一个对象的一个 synchronized 方法后,其它线程无法进入此对象的其他 synchronized 方法,因为它们都需要获取同步监视器(也称为锁)才能执行。同步监视器是对象级别的,因此当一个线程持有同步监视器时,其他线程无法获得该监视器。但是,非 synchronized 方法不需要获取同步监视器,因此可以在同一时间被多个线程并发调用。 -
线程同步与阻塞的关系?同步一定阻塞吗?阻塞一定同步吗?
答:
线程同步和阻塞是两个概念,它们之间有关联,但并不一定相互依存。线程同步是指多个线程在执行过程中,需要协调和同步彼此的操作,以保证数据的正确性和程序的正确性。线程同步可以通过使用锁、信号量等机制来实现。
阻塞是指线程在执行过程中被暂停,等待某些条件的满足后再继续执行。线程阻塞可以是由于等待某个资源的可用性,或者等待某个操作的完成等原因导致的。
同步和阻塞之间有关系,因为在进行线程同步的过程中,可能会需要对某些资源进行加锁,这样其他线程就不能访问该资源,从而导致其他线程阻塞。但是同步和阻塞并不一定相互依存,同步操作不一定会导致阻塞,阻塞操作也不一定需要同步。
例如,线程间的消息传递机制可以实现同步操作,但是不需要阻塞。而单线程中的阻塞操作,也不需要同步。因此,同步和阻塞是两个概念,需要根据具体的场景来进行选择和使用。
-
什么是死锁,产生死锁的原因及必要条件?
答:
死锁是多个进程或线程在互相等待对方释放资源而陷入无限等待的一种状态。这种状态下,每个进程或线程都在等待其他进程或线程释放资源,而不能继续执行下去。死锁产生的原因通常有以下几种:
① 资源竞争:多个进程或线程争夺有限的资源,如磁盘、内存等,当某个进程或线程持有一部分资源而又需要其他资源时,就会造成死锁。
② 进程或线程的顺序不当:当多个进程或线程按照不同的顺序请求资源时,也容易产生死锁。
③ 资源分配不当:当系统分配资源不当时,也会导致死锁的产生。死锁产生的必要条件有以下四个:
① 互斥条件:至少有一个资源必须处于非共享模式,即一次只能被一个进程或线程使用。
② 占有和等待条件:一个进程或线程必须占有至少一个资源,并等待其他进程或线程释放所需的资源。
③ 非抢占条件:资源不能被抢占,只能由占有资源的进程或线程显式地释放。
④ 循环等待条件:多个进程或线程形成一个循环等待资源的环路。 -
如何避免死锁?
答:
死锁是指两个或多个进程在执行过程中因争夺资源而产生的一种僵局,彼此都在等待对方先释放资源而无法继续执行下去。以下是避免死锁的几种方法:
① 避免资源竞争:尽量避免多个进程同时竞争同一资源,可以通过资源分配策略、资源复制等方式来实现。
② 避免持有和等待:一个进程不能持有某个资源并等待另一个进程占用的资源,可以通过一次性获取所有需要的资源来避免此情况。
③ 避免循环等待:多个进程之间不能形成循环等待资源的关系,可以通过给资源编号,按照一定顺序申请资源来避免。
④ 破坏资源占用和等待条件:通过限制进程的最大资源需求量、强制进程释放已占用的资源等方式来破坏资源占用和等待条件。
⑤ 破坏进程等待条件:通过限制进程等待时间、强制进程放弃等待的资源等方式来破坏进程等待条件。
总之,避免死锁需要综合考虑多种因素,采用合适的方法来解决问题。 -
Java 中 notify()和 notifyAll()有什么区别?
答:
notify()和 notifyAll()都是用于线程间通信的方法,它们的主要区别在于:
① notify()只会唤醒等待队列中的一个线程,而 notifyAll()会唤醒等待队列中的所有线程。
② notify()是随机唤醒等待队列中的一个线程,而 notifyAll()会唤醒所有等待队列中的线程,让它们去竞争锁。因此,如果你想唤醒所有等待队列中的线程,可以使用 notifyAll();如果你只想唤醒一个线程,可以使用 notify()。但是需要注意的是,notify()可能会导致某些线程一直等待下去,因为它只唤醒一个线程,如果唤醒的是不需要的线程,那么这个线程就会一直等待下去,而 notifyAll()则不会有这个问题。
-
为什么 wait()和 notify()方法要在同步块中调用?
答:
wait()和 notify()方法需要在同步块(synchronized block)中调用,主要是因为它们都需要获取对象的监视器(monitor)才能执行。监视器是 Java 中的一种内部锁机制,用于控制并发访问。在同步块中,线程可以获取对象的监视器,从而保证对共享资源的访问是同步的。具体来说,wait()方法会释放对象的监视器,让其他线程可以获取并修改共享资源。notify()方法会通知等待在对象上的一个线程,让其重新竞争该对象的监视器。如果这些方法不在同步块中调用,就可能会导致多个线程同时竞争对象的监视器,从而破坏同步性和线程安全性。
因此,为了保证线程安全和同步性,wait()和 notify()方法必须在同步块中调用,以确保线程能够正确获取和释放对象的监视器。
-
多线程中生产者消费者代码(同步、wait、notifly 编程)?
答:
以下是一个使用同步、wait 和 notify 编程的生产者消费者示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95public class ProducerConsumer
{
private List<Integer> buffer = new ArrayList<>(); // 创建一个空的列表用于存储数据
private int maxSize = 5; // 定义列表的最大长度为 5
public void produce() throws InterruptedException
{
synchronized (this)
{
// 同步代码块,确保线程安全
while (buffer.size() == maxSize)
{
// 如果列表已经达到最大长度
wait(); // 线程进入等待状态
}
int num = (int) (Math.random() * 100); // 生成一个随机数
buffer.add(num); // 将随机数添加到列表中
System.out.println("Produced: " + num); // 输出生产的数据
notify(); // 唤醒一个等待的线程
}
}
public void consume() throws InterruptedException
{
synchronized (this)
{
// 同步代码块,确保线程安全
while (buffer.size() == 0)
{
// 如果列表为空
wait(); // 线程进入等待状态
}
int num = buffer.remove(0); // 从列表中删除第一个元素
System.out.println("Consumed: " + num); // 输出消费的数据
notify(); // 唤醒一个等待的线程
}
}
public static void main(String[] args)
{
ProducerConsumer pc = new ProducerConsumer(); // 创建一个生产者消费者对象
Thread t1 = new Thread(new Runnable()
{
// 创建一个用于生产数据的线程
public void run()
{
try {
while (true)
{
// 一直循环
pc.produce(); // 生产数据
Thread.sleep(1000); // 线程休眠1秒
}
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
});
Thread t2 = new Thread(new Runnable()
{
// 创建一个用于消费数据的线程
public void run()
{
try
{
while (true)
{
// 一直循环
pc.consume(); // 消费数据
Thread.sleep(1000); // 线程休眠1秒
}
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
});
t1.start(); // 启动生产数据的线程
t2.start(); // 启动消费数据的线程
}
}在这个示例中,生产者和消费者都在同一个类中实现。buffer 是一个用于存储数据的列表,maxSize 是列表的最大长度。produce()和 consume()方法都使用 synchronized 关键字来保证线程安全。在 produce()方法中,如果 buffer 已经达到最大长度,则线程会进入等待状态,直到有其他线程调用 notify()方法唤醒它。然后,它会生成一个随机数并将其添加到 buffer 中。在 consume()方法中,如果 buffer 为空,则线程会进入等待状态,直到有其他线程调用 notify()方法唤醒它。然后,它会从 buffer 中删除第一个元素。
在 main()方法中,我们创建了两个线程,一个用于生产数据,另一个用于消费数据。这两个线程会一直运行,直到程序被终止。
-
wait()和 sleep()有什么区别?调用这两个函数后,线程状态分别作何改变?
答:
wait()和 sleep()在 Java 中都是用于线程的暂停,但是它们的用途和行为是不同的。wait()是 Object 类的方法,用于线程间的协调。调用 wait()方法的线程会释放对象锁并进入等待状态,直到其他线程调用对象的 notify()或 notifyAll()方法来唤醒它。调用 wait()方法后,线程状态变为 WAITING。
sleep()是 Thread 类的方法,用于让线程暂停一段时间。调用 sleep()方法后,线程会进入阻塞状态,并且不会释放对象锁。sleep()方法会让线程休眠指定的时间,然后自动唤醒线程。调用 sleep()方法后,线程状态变为 TIMED_WAITING。
综上所述,wait()和 sleep()的区别在于它们的用途和行为,调用后线程的状态也不同。wait()用于线程间的协调,调用后线程状态变为 WAITING;sleep()用于让线程暂停一段时间,调用后线程状态变为 TIMED_WAITING。
-
手写一个线程安全的单例模式(Singleton)。
答:
饿汉式:1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Singleton
{
private static Singleton instance = new Singleton();
private Singleton()
{
}
public static Singleton getInstance()
{
return instance;
}
}安全的懒汉式:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17public class Singleton
{
private static Singleton instance;
private Singleton()
{
}
public static synchronized Singleton getInstance()
{
if (instance == null)
{
instance = new Singleton();
}
return instance;
}
}内部类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class Singleton
{
private Singleton()
{
}
private static class SingletonHolder
{
private static final Singleton INSTANCE = new Singleton();
}
public static Singleton getInstance()
{
return SingletonHolder.INSTANCE;
}
}以上三种方式都是线程安全的单例模式,其中饿汉式在类加载时就创建了实例,安全的懒汉式使用了 synchronized 关键字来保证线程安全,而内部类则利用了类加载的线程安全性来保证单例。
-
手写一个懒汉式的单例模式,解决其线程安全问题,并且说明为什么这样子去解决?
答:
懒汉式单例模式指的是在需要使用实例时才去创建实例,而不是在类加载时就创建实例。线程安全问题是因为多个线程同时访问时可能会创建多个实例,导致不符合单例模式的定义。为了解决线程安全问题,可以使用 synchronized 关键字来实现同步锁,保证在多线程环境下只会创建一个实例。
以下是手写的懒汉式单例模式代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19public class Singleton
{
private static Singleton instance;
private Singleton()
{
}
public static synchronized Singleton getInstance()
{
if (instance == null)
{
instance = new Singleton();
}
return instance;
}
}在 getInstance 方法上添加 synchronized 关键字,保证在多线程环境下只有一个线程可以进入创建实例的代码块,从而避免创建多个实例的问题。
这样子去解决的原因是因为 synchronized 关键字可以保证在同一时刻只有一个线程可以进入同步代码块,其它线程需要等待该线程执行完毕后才能进入。这样可以保证在多线程环境下只会创建一个实例,从而解决了线程安全问题。
第 11 章 常用类与基础 API
11.1 String 类
11.1.1 String 的特性
- java.lang.String 类代表字符串。Java 程序中所有的字符串文字(例如"hello" )都可以看作是实现此类的实例。
- 字符串是常量,用双引号引起来表示。它们的值在创建之后不能更改。
- 字符串 String 类型本身是 final 声明的,意味着我们不能继承 String。
- String 对象的字符内容是存储在一个字符数组 value[]中的。“hello” 等效于 char[] data={‘h’,‘e’,‘l’,‘l’,‘o’}。
- String 的两种定义方式:
① 字面量的定义方式 String s = “hello”
② new 的方式:String s = new String(“hello”); - Java 语言提供对字符串串联符号(“+”)以及将其他对象转换为字符串的特殊支持(toString()方法)。
11.1.2 String 的内存解析
字符串常量池、堆内存。
11.1.3 String 的常用 API
-
构造器
- public String() :初始化新创建的 String 对象,以使其表示空字符序列。
- String(String original): 初始化一个新创建的 String 对象,使其表示一个与参数相同的字符序列;换句话说,新创建的字符串是该参数字符串的副本。
- public String(char[] value) :通过当前参数中的字符数组来构造新的 String。
- public String(char[] value,int offset, int count) :通过字符数组的一部分来构造新的 String。
- public String(byte[] bytes) :通过使用平台的默认字符集解码当前参数中的字节数组来构造新的 String。
- public String(byte[] bytes,String charsetName) :通过使用指定的字符集解码当前参数中的字节数组来构造新的 String。
-
String 与其他结构之间的转换
- 字符串 ——> 基本数据类型、包装类:
- Integer 包装类的 public static int parseInt(String s):可以将由“数字”字符组成的字符串转换为整型。
- 类似地,使用 java.lang 包中的 Byte、Short、Long、Float、Double 类调相应的类方法可以将由“数字”字符组成的字符串,转化为相应的基本数据类型。
- 基本数据类型、包装类 ——> 字符串: - 调用 String 类的 public String valueOf(int n)可将 int 型转换为字符串。 - 相应的 valueOf(byte b)、valueOf(long l)、valueOf(float f)、valueOf(double d)、
valueOf(boolean b)可由参数的相应类型到字符串的转换。 - 字符数组 ——> 字符串: - String 类的构造器:String(char[]) 和 String(char[],int offset,int length) 分别用字
符数组中的全部字符和部分字符创建字符串对象。 - 字符串 ——> 字符数组:
- public char[] toCharArray():将字符串中的全部字符存放在一个字符数组中的方法。
- public void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin):提供了将指定索引范围内的字符串存放到数组中的方法。
- 字符串 ——> 字节数组:(编码)
- public byte[] getBytes() :使用平台的默认字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中。
- public byte[] getBytes(String charsetName) :使用指定的字符集将此 String 编码到 byte 序列,并将结果存储到新的 byte 数组。
- 字节数组 ——> 字符串:(解码)
- String(byte[]):通过使用平台的默认字符集解码指定的 byte 数组,构造一个新的 String。
- String(byte[],int offset,int length) :用指定的字节数组的一部分,即从数组起始位置 offset 开始取 length 个字节构造一个字符串对象。
- String(byte[], String charsetName ) 或 new String(byte[], int, int,String charsetName ):解码,按照指定的编码方式进行解码。
- 字符串 ——> 基本数据类型、包装类:
-
常用方法
- boolean isEmpty():字符串是否为空。
- int length():返回字符串的长
度。 - String concat(xx):拼接。
- boolean equals(Object obj):比较字符串是否相等,区分大小写。
- boolean equalsIgnoreCase(Object obj):比较字符串是否相等,不区分大小写。
- int compareTo(String other):比较字符串
大小,区分大小写,按照 Unicode 编码值比较大小。 - int compareToIgnoreCase(String other):比较字符串大小,不区分大小写 。
- String toLowerCase():将字符串中大写字母转为小写。
- StringtoUpperCase():将字符串中小写字母转为大写。
- String trim():去掉字符串前后空白符。
- public String intern():结果在常量池中共享。
-
查找
- boolean contains(xx):是否包含 xx。
- int indexOf(xx):从前往后找当前字符串中 xx,即如果有返回第一次出现的下标,要是没有返回-1。
- int indexOf(String str, int fromIndex):返回指定子字符串在此字符串中第一次出现处的索引,从指定的索引开始。
- int lastIndexOf(xx):从后往前找当前字符串中 xx,即如果有返回最后一次出现的下标,要是没有返回-1。
- int lastIndexOf(String str, int fromIndex):返回指定子字符串在此字符串中最后一次出现处的索引,从指定的索引开始反向搜索。
-
字符串截取
- String substring(int beginIndex) :返回一个新的字符串,它是此字符串的从 beginIndex 开始截取到最后的一个子字符串。
- String substring(int beginIndex, int endIndex) :返回一个新字符串,它是此字符串从 beginIndex
开始截取到 endIndex(不包含)的一个子字符串。
-
和字符、字符数组相关
- char charAt(index):返回[index]位置的字符。
- char[] toCharArray(): 将此字符串转换为一个新的字符数组返回。
- static String valueOf(char[] data) :返回指定数组中表示该字符序列的 String。
- static String valueOf(char[] data, int offset, int count) : 返回指定数组中表示该字符序列的 String。
- static String copyValueOf(char[] data): 返回指定数组中表示该字符序列的 String。
- static String copyValueOf(char[] data, int
offset, int count):返回指定数组中表示该字符序列的 String。
-
开头与结尾
- boolean startsWith(xx):测试此字符串是否以指定的前缀开始。
- boolean startsWith(String prefix, int toffset):测试此字符串从指定索引开始的子字符串是否以指定前缀开始。
- boolean endsWith(xx):测试此字符串是否以指定的后缀结束。
-
替换
- String replace(char oldChar, char newChar):返回一个新的字符串,它是通过用 newChar 替换此字符串中出现的所有 oldChar 得到的。 不支持正则。
- String replace(CharSequence target, CharSequence replacement):使用指定的字面值替换序列替换此字符串所有匹配字面值目标序列的子字符串。
- String replaceAll(String regex, String replacement):使用给定的 replacement 替换此字符串所有匹配给定的正则表达式的子字符串。
- String replaceFirst(String regex, String replacement):使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串。
11.2 StringBuffer、StringBuilder 类
因为 String 对象是不可变对象,虽然可以共享常量对象,但是对于频繁字符串的修改和拼接操作,效率极低,空间消耗也比较高。因此,JDK 又在 java.lang 包提供了可变字符序列 StringBuffer 和 StringBuilder 类型。
区分 String、StringBuffer、StringBuilder
- String:不可变的字符序列; 底层使用 char[]数组存储。(JDK8.0)
- StringBuffer:可变的字符序列;线程安全(方法有 synchronized 修饰),效率低;底层使用 char[]数组存储 。(JDK8.0)
- StringBuilder:可变的字符序列; jdk1.5 引入,线程不安全的,效率高;底层使用 char[]数组存储。(JDK8.0)
11.3 jdk8 之前的日期、时间 API
11.3.1 java.lang.System 类的日期、时间 API
System 类提供的 public static long currentTimeMillis():用来返回当前时间与 1970 年 1 月 1 日 0 时 0 分 0 秒之间以毫秒为单位的时间差。
- 此方法适于计算时间差。
11.3.2 java.util.Date 类的日期、时间 API
表示特定的瞬间,精确到毫秒。
-
构造器
- Date():使用无参构造器创建的对象可以获取本地当前时间。
- Date(long 毫秒数):把该毫秒值换算成日期时间对象。
-
常用方法
- getTime(): 返回自 1970 年 1 月 1 日 00:00:00 GMT 以来此 Date 对象表示的毫秒数。
- toString(): 把此 Date 对象转换为以下形式的 String: dow mon dd hh:mm:ss zzz yyyy 其中: dow 是一周中的某一天 (Sun, Mon, Tue, Wed, Thu, Fri, Sat),zzz 是时间标准。
11.3.3 java.text.SimpleDateFormat
-
java.text.SimpleDateFormat 类是一个不与语言环境有关的方式来格式化和解析日期的具体类。
-
可以进行格式化:日期 ——> 文本。
-
可以进行解析:文本 ——> 日期。
-
构造器
- SimpleDateFormat() :默认的模式和语言环境创建对象。
- public SimpleDateFormat(String pattern):该构造方法可以用参数 pattern 指定的格式创建一个对象。
-
格式化
- public String format(Date date):方法格式化时间对象 date。
-
解析
- public Date parse(String source):从给定字符串的开始解析文本,以生成一个日期。
11.3.4 java.util.Calendar(日历)
-
Calendar 类是一个抽象类,主用用于完成日期字段之间相互操作的功能。
-
获取 Calendar 实例的方法
- 使用 Calendar.getInstance()方法。
- 调用它的子类 GregorianCalendar(公历)的构造器。
-
一个 Calendar 的实例是系统时间的抽象表示,可以修改或获取 YEAR、MONTH、DAYOFWEEK、HOUROFDAY 、MINUTE、SECOND 等日历字段对应的时间值。
- public int get(int field):返回给定日历字段的值。
- public void set(int field,int value) :将给定的日历字段设置为指定的值。
- public void add(int field,int amount):根据日历的规则,为给定的日历字段添加或者减去指定的时间量。
- public final Date getTime():将 Calendar 转成 Date 对象。
- public final void setTime(Date date):使用指定的 Date 对象重置 Calendar 的时间。
11.4 jdk8 中新的日期、时间 API
11.4.1 本地日期时间:LocalDate、LocalTime、LocalDateTime


- LocalDate、LocalTime、LocalDateTime ——>类似于 Calendar。
11.4.2 瞬时:Instant
• Instant:时间线上的一个瞬时点。 这可能被用来记录应用程序中的事件时间戳。


- Instant ——>类似于 Date。
11.4.3 日期时间格式化:DateTimeFormatter


- DateTimeFormatter ——>类似于 SimpleDateFormat。
11.5 比较器
在 Java 中经常会涉及到对象数组的排序问题,那么就涉及到对象之间的比较问题。
Java 实现对象排序的方式有两种:
- 自然排序:java.lang.Comparable
- 定制排序:java.util.Comparator
11.5.1 自然排序:java.lang.Comparable
Comparable 接口强行对实现它的每个类的对象进行整体排序。这种排序被称为类的自然排序。
实现 Comparable 的类必须实现 compareTo(Object obj)方法,两个对象即通过 compareTo(Object obj) 方法的返回值来比较大小。如果当前对象 this 大于形参对象 obj,则返回正整数,如果当前对象 this 小于形参对象 obj,则返回负整数,如果当前对象 this 等于形参对象 obj,则返回零。
11.5.2 定制排序:java.util.Comparator
思考:
- 当元素的类型没有实现 java.lang.Comparable 接口而又不方便修改代码。(例如:一些第三方的类,你只有.class 文件,没有源文件)
- 如果一个类,实现了 Comparable 接口,也指定了两个对象的比较大小的
规则,但是此时此刻我不想按照它预定义的方法比较大小,但是我又不能随意修改,因为会影响其他地方的使用,怎么办?
JDK 在设计类库之初,也考虑到这种情况,所以又增加了一个 java.util.Comparator 接口。强行对多个对象进行整体排序的比较。
- 重写 compare(Object o1,Object o2)方法,比较 o1 和 o2 的大小:如果方法返回正整数,则表示 o1 大于 o2;如果返回 0,表示相等;返回负整数,表示 o1 小于 o2。
- 可以将 Comparator 传递给 sort 方法(如 Collections.sort 或 Arrays.sort),从而允许在排序顺序上实现精确控制。
11.6 系统相关类
11.6.1 java.lang.System 类
System 类代表系统,系统级的很多属性和控制方法都放置在该类的内部。该类位于 java.lang 包。
由于该类的构造器是 private 的,所以无法创建该类的对象。其内部的成员变量和成员方法都是 static 的,所以也可以很方便的进行调用。
成员变量:
- Scanner scan = new Scanner(System.in);
- System 类内部包含 in、out 和 err 三个成员变量,分别代表标准输入流(键盘输入),标准输出流(显示器)和标准错误输出流(显示器)。
成员方法:
- native long currentTimeMillis(): 该方法的作用是返回当前的计算机时间,时间的表达格式为当前计算机时间和 GMT 时间(格林威治时间)1970 年 1 月 1 号 0 时 0 分 0 秒所差的毫秒数。
- void exit(int status): 该方法的作用是退出程序。其中 status 的值为 0 代表正常退出,非零代表异常退出。使用该方法可以在图形界面编程
中实现程序的退出功能等。 - void gc(): 该方法的作用是请求系统进行垃圾回收。至于系统是否立刻回收,则取决于系统中垃圾回收算法的实现以及系统执行时的情况。
- String getProperty(String key): 该方法的作用是获得系统中属性名为 key 的属性对应的值。
11.6.2 java.lang.Runtime 类
- 每个 Java 应用程序都有一个 Runtime 类实例,使应用程序能够与其运行的环境相连接。
- public static Runtime getRuntime(): 返回与当前 Java 应用程序相关的运行时对象。应用程序不能创建自己的 Runtime 类实例。
- public long totalMemory():返回 Java 虚拟机中初始化时的内存总量。此方法返回的值可能随时间的推移而变化,这取决于主机环境。默认为物理电脑内存的 1/64。
- public long maxMemory():返回 Java 虚拟机中最大程度能使用的内存总量。默认为物理电脑内存的 1/4。
- public long freeMemory():回 Java 虚拟机中的空闲内存量。调用 gc 方法可能导致 freeMemory 返回值的增加。
11.7 数学相关的类
11.7.1 java.lang.Math
java.lang.Math 类包含用于执行基本数学运算的方法,如初等指数、对数、平方根和三角函数。类似这样的工具类,其所有方法均为静态方法,并且不会创建对象,调用起来非常简单。
11.7.2 BigInteger
Integer 类作为 int 的包装类,能存储的最大整型值为 2^31 - 1。
Long 类也是有限的,最大为 2^63 - 1。如果要表示再大的整数,不管是基本数据类型还是他们的包装类都无能为力,更不用说进行运算了。
java.math 包的 BigInteger 可以表示不可变的任意精度的整数。BigInteger 提供所有 Java 的基本整数操作符的对应物,并提供 java.lang.Math 的所有相关方法。另外,BigInteger 还提供以下运算:模算术、GCD 计算、质数测试、素数生成、位操作以及一些其他操作。
构造器:
- BigInteger(String val):根据字符串构建 BigInteger 对象
方法:
- public BigInteger abs():返回此 BigInteger 的绝对值的 BigInteger。
- BigInteger add(BigInteger val) :返回其值为 (this + val) 的 BigInteger。
- BigInteger subtract(BigInteger val) :返回其值为 (this - val) 的 BigInteger。
- BigInteger multiply(BigInteger val) :返回其值为 (this * val) 的 BigInteger。
- BigInteger divide(BigInteger val) :返回其值为 (this / val) 的 BigInteger。整数相除只保留整数部分。
- BigInteger remainder(BigInteger val) :返回其值为 (this % val) 的 BigInteger。
- BigInteger[] divideAndRemainder(BigInteger val):返回包含 (this / val) 后跟 (this % val) 的两个 BigInteger 的数组。
- BigInteger pow(int exponent) :返回其值为 (this^exponent) 的 BigInteger。
11.7.3 BigDecimal
一般的 Float 类和 Double 类可以用来做科学计算或工程计算,但在商业计算中,要求数字精度比较高,故用到 java.math.BigDecimal 类。
BigDecimal 类支持不可变的、任意精度的有符号十进制定点数。
构造器:
- public BigDecimal(double val)
- public BigDecimal(String val)
常用方法:
- public BigDecimal add(BigDecimal augend)
- public BigDecimal subtract(BigDecimal subtrahend)
- public BigDecimal multiply(BigDecimal multiplicand)
- public BigDecimal divide(BigDecimal divisor, int scale, int roundingMode):divisor 是除数,scale 指明保留几位小数,roundingMode
指明舍入模式。(ROUNDUP :向上加 1、ROUNDDOWN :直接舍去、ROUNDHALFUP:四舍五入)
11.7.4 java.util.Random
- 用于产生随机数。
- boolean nextBoolean():返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 boolean 值。
- void nextBytes(byte[] bytes):生成随机字节并将其置于用户提供的 byte 数组中。
- double nextDouble():返回下一个伪随机数,它是取自此随机数生成器序列的、在 0.0 和 1.0 之间均匀分布的 double 值。
- float nextFloat():返回下一个伪随机数,它是取自此随机数生成器序列的、在 0.0 和 1.0 之间均匀分布的 float 值。
- double nextGaussian():返回下一个伪随机数,它是取自此随机数生成器序列的、呈高斯(“正态”)分布的 double 值,其平均值是 0.0,标准差是 1.0。
- int nextInt():返回下一个伪随机数,它是此随机数生成器的序列中均匀分布的 int 值。
- int nextInt(int n):返回一个伪随机数,它是取自此随机数生成器序列的、在 0(包括)和指定值(不包括)之间均匀分布的 int 值。
- long nextLong():返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 long 值。
11.8 企业真题
-
以下两种方式创建的 String 对象有什么不同?
1
2String str1 = "Hello";
String str2 = new String("Hello");答:
① 直接赋值创建 String 对象:1
String str1 = "Hello";
这种方式创建的 String 对象是在字符串常量池中创建的,如果已经存在相同的字符串常量,就会直接返回该常量的引用,而不会重新创建。
② 使用 new 关键字创建 String 对象:
1
String str2 = new String("Hello");
这种方式创建的 String 对象是在堆内存中创建的,不会共享存储空间,即使是相同的字符串内容也会创建多个对象。
因此,使用直接赋值方式创建 String 对象更加高效,能够节省存储空间和创建对象的时间。
-
String s = new String(“xyz”);创建了几个 String Object?
答:
如果我们只考虑这一行代码,确实只创建了一个 String Object。但是,由于 Java 有一个字符串池(string pool)的概念,如果字符串池中没有"xyz"这个字符串,那么这个字符串会被添加到字符串池中。因此,实际上可能会创建两个 String Object:一个在堆中,一个在字符串池中。但是,这取决于 JVM 的实现方式和优化策略,因此不是绝对的。 -
String a=“abc” String b=“a”+“bc” ,那么 a==b?
答:
true,因为"a"+“bc"会被编译器优化为"abc”,所以 a 和 b 都是指向值为"abc"的 String 对象。 -
String 中 “+” 怎样实现?
答:
在 Java 中,字符串连接可以使用 “+” 运算符来实现。当两个字符串相加时,Java 会将它们连接起来,形成一个新的字符串。例如:1
2
3
4String str1 = "Hello";
String str2 = "World";
String str3 = str1 + " " + str2;
System.out.println(str3);输出结果为: “Hello World”。
在底层实现中,Java 会使用 StringBuilder 或 StringBuffer 类来实现字符串连接。这两个类都提供了 append() 方法来实现字符串的拼接,而 “+” 运算符就是使用了这些方法。在实际开发中,建议使用 StringBuilder 或 StringBuffer 类来进行字符串拼接,因为它们的效率更高。
-
Java 中 String 是不是 final 的?
答:
是的,Java 中的 String 是 final 的,这意味着它们是不可变的。一旦一个 String 对象被创建,它的值就不能被改变。如果需要修改一个字符串,必须创建一个新的 String 对象来代替原来的对象。这种不可变性使得 String 对象在多线程环境下更加安全和可靠。 -
String 为啥不可变,在内存中的具体形态?
答:
String 不可变的原因是因为它的值被创建后就不能再被修改。这是因为 String 类被设计为 final 类,因此它的方法都不能被重写,也不能被子类化。这就意味着一旦一个 String 对象被创建,它的值就不能被更改,只能创建一个新的 String 对象来代替。在内存中,每个 String 对象都有一个字符串常量池。字符串常量池是一个特殊的内存区域,用于存储所有的字符串常量。当创建一个 String 对象时,如果字符串常量池中已经存在相同值的字符串常量,则返回该常量的引用,否则就会在常量池中新建一个字符串常量,并返回该常量的引用。
具体来说,当我们使用字符串字面值创建一个 String 对象时,Java 会首先在字符串常量池中查找是否已经存在相同值的字符串常量。如果存在,则返回该常量的引用;如果不存在,则在字符串常量池中新建一个字符串常量,并返回该常量的引用。如果我们使用 new 关键字显式创建一个 String 对象,则该对象会被存储在堆内存中,而不是字符串常量池中。
总之,String 的不可变性是由 final 关键字和其设计决定的,而字符串常量池则是一种优化机制,用于避免重复创建相同值的字符串常量。
-
String 可以在 switch 中使用吗?
答:
是的,从 Java 7 开始,String 类型可以在 switch 语句中使用。在之前的版本中,只能使用基本数据类型和枚举类型。在使用字符串时,每个 case 分支都必须是一个字符串常量。例如:1
2
3
4
5
6
7
8
9
10
11
12String str = "hello";
switch (str)
{
case "hello":
System.out.println("Hello!");
break;
case "world":
System.out.println("World!");
break;
default:
System.out.println("Other!");
}注意,在 switch 语句中使用字符串时,需要使用双引号将字符串括起来。
-
String 中有哪些方法?列举几个。
答:
① length():返回字符串的长度。
② charAt(int index):返回指定位置的字符。
③ indexOf(String str):返回指定字符串在该字符串中第一次出现的位置。
④ substring(int beginIndex, int endIndex):返回从指定位置开始到结束位置的子字符串。
⑤ equals(Object obj):比较字符串是否相等。
⑥ toUpperCase():将字符串转换为大写。
⑦ toLowerCase():将字符串转换为小写。
⑧ replace(char oldChar, char newChar):用新字符替换旧字符。
⑨ trim():去除字符串两端的空格。
⑩ split(String regex):将字符串按照指定正则表达式分割成字符串数组。 -
subString()到底做了什么?
答:
Java 中的 subString()方法用于从一个字符串中获取一个子字符串。它接受两个参数,即要提取的子字符串的起始索引和结束索引。它返回从起始索引到结束索引(不包括结束索引)的子字符串。subString()方法实际上在原始字符串上创建了一个新的字符串对象,该字符串对象包含从原始字符串中提取的子字符串。这个新字符串对象是原始字符串的一个子字符串,它与原始字符串共享相同的字符数组。因此,如果在原始字符串中进行更改,则可能会影响子字符串。
需要注意的是,如果传递给 subString()方法的起始索引或结束索引超出了字符串的范围,则会抛出 StringIndexOutOfBoundsException 异常。
-
Java 中操作字符串有哪些类?他们之间有什么区别?
答:
Java 中操作字符串的类有 String、StringBuffer 和 StringBuilder。它们之间的区别如下:
① String 类是不可变的,意味着一旦创建了一个字符串对象,就不能改变它的值,任何对字符串的修改都会创建一个新的字符串对象。String 类适用于字符串不需要频繁修改的场景。
② StringBuffer 类是可变的,可以对字符串进行修改,适用于需要频繁修改字符串的场景。在多线程环境下,StringBuffer 是线程安全的。
③ StringBuilder 类也是可变的,与 StringBuffer 类相似,但不保证线程安全。StringBuilder 类适用于在单线程环境下,需要频繁修改字符串的场景。总之,如果需要频繁修改字符串并且在多线程环境下,建议使用 StringBuffer 类。如果在单线程环境下需要频繁修改字符串,建议使用 StringBuilder 类。如果字符串不需要频繁修改,使用 String 类即可。
-
String 的线程安全问题?
答:
String 是不可变对象,因此它是线程安全的。多个线程可以同时访问同一个 String 对象,而不会出现竞争条件或线程安全问题。但是,如果在多个线程之间共享可变的 StringBuilder 或 StringBuffer 对象时,就会出现线程安全问题,因为这些对象是可变的。在这种情况下,需要使用同步机制来保证线程安全。 -
StringBuilder 和 StringBuffer 的线程安全问题?
答:
StringBuilder 和 StringBuffer 都是可变字符串的实现类,区别在于 StringBuffer 是线程安全的,而 StringBuilder 是非线程安全的。线程安全的意思是多个线程同时操作一个对象时,不会出现数据不一致或者异常的情况。在多线程环境下,如果使用 StringBuilder 进行字符串的操作,可能会出现数据不一致的问题。因为 StringBuilder 不是线程安全的,多个线程同时操作一个 StringBuilder 对象时,会出现竞争条件,导致数据不一致。
而 StringBuffer 是线程安全的,它的所有公共方法都是同步的,保证了多个线程同时操作一个 StringBuffer 对象时,数据的一致性。
因此,如果在多线程环境下需要进行字符串的操作,应该使用 StringBuffer,而不是 StringBuilder。如果在单线程环境下进行字符串的操作,建议使用 StringBuilder,因为它比 StringBuffer 更高效。
-
简单说说 Comparable 和 Comparator 的区别和场景?
答:
Comparable 是一个接口,它是 Java 中的一个内部比较器,可以通过实现该接口来定义类的内部比较规则。实现 Comparable 接口的类可以进行自然排序,即按照类的内部定义的比较规则进行排序。Comparator 也是一个接口,它是 Java 中的一个外部比较器,可以通过实现该接口来定义类的外部比较规则。实现 Comparator 接口的类可以进行定制排序,即按照自己定义的比较规则进行排序。
总的来说,Comparable 是用于定义类的内部比较规则,Comparator 是用于定义类的外部比较规则。如果我们需要对已有的类进行排序,而该类没有实现 Comparable 接口,或者我们需要按照不同的比较规则进行排序,那么就需要使用 Comparator 接口来进行定制排序。
-
Comparable 接口和 Comparator 接口实现比较?
答:
Comparable 接口是 Java 中的一个接口,它只有一个方法 compareTo(Object obj),用于定义对象之间的自然排序。如果一个类实现了 Comparable 接口,就可以使用 Collections.sort 或 Arrays.sort 方法对该类的对象进行排序。Comparator 接口也是 Java 中的一个接口,它有两个方法 compare(Object obj1, Object obj2) 和 equals(Object obj),用于定义对象之间的比较。如果一个类实现了 Comparator 接口,就可以使用 Collections.sort 或 Arrays.sort 方法,并传入该类的对象作为比较器,对其他类的对象进行排序。
两者的区别在于 Comparable 接口是在对象内部实现的,而 Comparator 接口是在对象外部实现的。如果一个类只需要一种排序方式,可以实现 Comparable 接口;如果需要多种排序方式,或者需要对其他类的对象进行排序,可以实现 Comparator 接口。
第 12 章 集合框架
12.1 数组存储数据方面的特点和弊端
数组存储多个数据方面的特点:
- 数组一旦初始化,其长度就是确定的。
- 数组中的多个元素是依次紧密排列的,有序的,可重复的。
- 数组一旦初始化完成,其元素的类型就是确定的。不是此类型的元素,就不能添加到此数组中。
- 元素的类型既可以是基本数据类型,也可以是引用数据类型。
数组存储多个数据方面的弊端:
- 数组一旦初始化,其长度就不可变了。
- 数组中存储数据特点的单一性。对于无序的、不可重复的场景的多个数据就无能为力了。
- 数组中可用的方法、属性都极少。具体的需求,都需要自己来组织相关的代码逻辑。
- 针对于数组中元素的删除、插入操作,性能较差。
12.2 集合框架概述
- Java 集合可分为 Collection 和 Map 两大体系。
- Collection 接口:用于存储一个一个的数据,也称单列数据集合。
- List 子接口:用来存储有序的、可以重复的数据。(主要用来替换数组,"动态"数组)
- 实现类:ArrayList(主要实现类)、LinkedList、Vector。
- Set 子接口:用来存储无序的、不可重复的数据。
- 实现类:HashSet(主要实现类)、LinkedHashSet、TreeSet。
- List 子接口:用来存储有序的、可以重复的数据。(主要用来替换数组,"动态"数组)
- Map 接口:用于存储具有映射关系“key-value 对”的集合,即一对一对的数据,也称双列数据集合。
- HashMap(主要实现类)、LinkedHashMap、TreeMap、Hashtable、Properties。
- JDK 提供的集合 API 位于 java.util 包内。
12.3 Collection 接口的常用方法
12.3.1 添加
- add(E obj):添加元素对象到当前集合中。
- addAll(Collection other):添加 other 集合中的所有元素对象到当前集合中。
12.3.2 判断
- int size():获取当前集合中实际存储的元素个数。
- boolean isEmpty():判断当前集合是否为空集合。
- boolean contains(Object obj):判断当前集合中是否存在一个与 obj 对象 equals 返回 true 的元素。
- boolean containsAll(Collection coll):判断 coll 集合中的元素是否在当前集合中都存在。即 coll 集合是否是当前集合的“子集” 。
- boolean equals(Object obj):判断当前集合与 obj 是否相等。
12.3.3 删除
- void clear():清空集合元素。
- boolean remove(Object obj) :从当前集合中删除第一个找到的与 obj 对象 equals 返回 true 的元素。
- boolean removeAll(Collection coll):从当前集合中删除所有与 coll 集合中相同的元素。
- boolean retainAll(Collection coll):从当前集合
中删除两个集合中不同的元素,使得当前集合仅保留与 coll 集合中的元素相同的元素,即当前集合中仅保留两个集合的交集。
12.3.4 其它
- Object[] toArray():返回包含当前集合中所有元素的数组。
- hashCode():获取集合对象的哈希值。
- iterator():返回迭代器对象,用于集合遍历。
12.4 Iterator(迭代器)接口
12.4.1 Iterator 接口
在程序开发中,经常需要遍历集合中的所有元素。针对这种需求,JDK 专门提供了一个接口 java.util.Iterator。Iterator 接口也是 Java 集合中的一员,但它与 Collection、Map 接口有所不同。
Collection 接口与 Map 接口主要用于存储元素。
Iterator,被称为迭代器接口,本身并不提供存储对象的能力,主要用于遍历 Collection 中的元素。
Collection 接口继承了 java.lang.Iterable 接口,该接口有一个 iterator()方法,那么所有实现了 Collection 接口的集合类都有一个 iterator()方法,用以返回一个实现了 Iterator 接口的对象。
- public Iterator iterator(): 获取集合对应的迭代器,用来遍历集合中的元素的。
- 集合对象每次调用 iterator()方法都得到一个全新的迭代器对象,默认游标都在集合的第一个元素之前。
Iterator 接口的常用方法如下:
- public E next():返回迭代的下一个元素。
- public boolean hasNext():如果仍有元素可以迭代,则返回 true。
注意:在调用 it.next()方法之前必须要调用 it.hasNext()进行检测。若不调用,且下一条记录无效,直接调用 it.next()会抛出 NoSuchElementException 异常。
代码示例:
1 | // 1. 如何获取迭代器(Iterator)对象? |
12.4.2 迭代器的执行原理
Iterator 迭代器对象在遍历集合时,内部采用指针的方式来跟踪集合中的元素,接下来通过一个图例来演示 Iterator 对象迭代元素的过程:
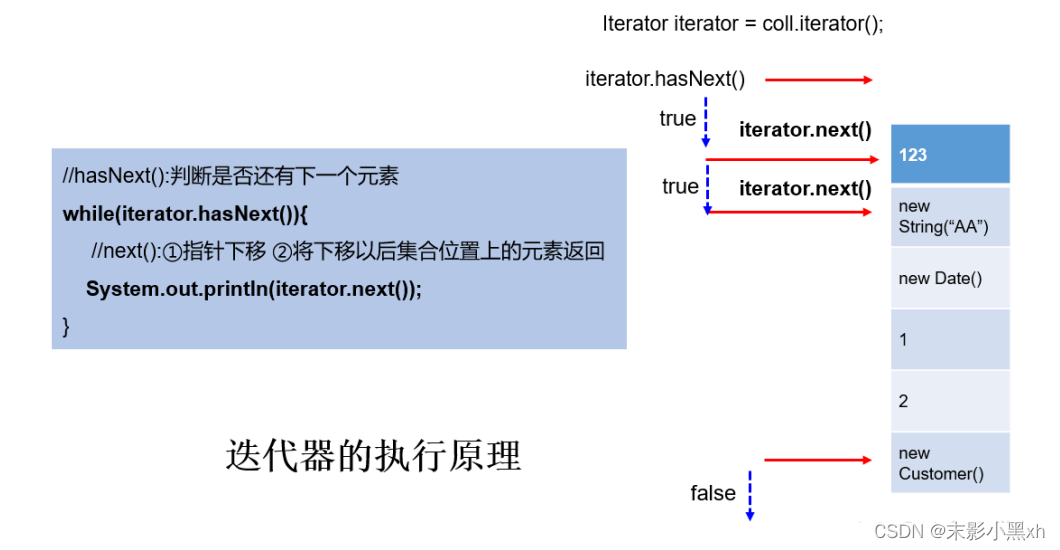
使用 Iterator 迭代器删除元素:java.util.Iterator 迭代器中有一个方法:void remove()。
注意:
- Iterator 可以删除集合的元素,但是遍历过程中通过迭代器对象的 remove 方法,不是集合对象的 remove 方法。
- 如果还未调用 next()或在上一次调用 next() 方法之后已经调用了 remove() 方法,再调用 remove()都会报 IllegalStateException。
- Collection 已经有 remove(xx)方法了,为什么 Iterator 迭代器还要提供删除方法呢?因为迭代器的 remove()可以按指定的条件进行删除。
迭代器的执行原理是设计模式的一种。
迭代器不负责数据的存储,负责对集合类的遍历。
12.4.3 foreach 循环
foreach 循环(也称增强 for 循环)是 JDK5.0 中定义的一个高级 for 循环,专门用来遍历数组和集合的。
语法格式:
1 | for(元素的数据类型 局部变量 : Collection 集合或数组) |
对于集合的遍历,增强 for 的内部原理其实是个 Iterator 迭代器。
12.5 Collection 的子接口:List
12.5.1 List 接口概述
鉴于 Java 中数组用来存储数据的局限性,我们通常使用 java.util.List 替代数组。
List 集合类中元素有序、且可重复,集合中的每个元素都有其对应的顺序索引。
JDK API 中 List 接口的实现类常用的有:ArrayList、LinkedList 和 Vector。
12.5.2 List 接口方法
List 除了从 Collection 集合继承的方法外,List 集合里添加了一些根据索引来操作集合元素的方法。
-
插入元素
- void add(int index, Object ele):在 index 位置插入 ele 元素。
- boolean addAll(int index, Collection eles):从 index 位置开始将 eles 中的所有元素添加进来。
-
获取元素
- Object get(int index):获取指定 index 位置的元素。
- List subList(int fromIndex, int toIndex):返回从 fromIndex 到 toIndex 位置的子集合。
-
获取元素索引
- int indexOf(Object obj):返回 obj 在集合中首次出现的位置。
- int lastIndexOf(Object obj):返回 obj 在当前集合中末次出现的位置。
-
删除和替换元素
- Object remove(int index):移除指定 index 位置的元素,并返回此元素。
- Object set(int index, Object ele):设置指定 index 位置的元素为 ele。
12.5.3 List 接口主要实现类:ArrayList
ArrayList 是 List 接口的主要实现类
本质上,ArrayList 是对象引用的一个”变长”数组。
Arrays.asList(…) 方法返回的 List 集合,既不是 ArrayList 实例,也不是 Vector 实例。Arrays.asList(…) 返回值是一个固定长度的 List 集合。
12.5.4 List 的实现类:LinkedList
对于频繁的插入或删除元素的操作,建议使用 LinkedList 类,效率较高。这是由底层采用链表(双向链表)结构存储数据决定的。
方法:
- void addFirst(Object obj)
- void addLast(Object obj)
- Object getFirst()
- Object getLast()
- Object removeFirst()
- Object removeLast()
12.5.5 List 的实现类:Vector
Vector 是一个古老的集合,JDK1.0 就有了。大多数操作与 ArrayList 相同,区别之处在于 Vector 是线程安全的。
在各种 List 中,最好把 ArrayList 作为默认选择。当插入、删除频繁时,使用 LinkedList;Vector 总是比 ArrayList 慢,所以尽量避免使用。
方法:
- void addElement(Object obj)
- void insertElementAt(Object obj,int index)
- void setElementAt(Object obj,int index)
- void removeElement(Object obj)
- void removeAllElements()
12.6 Collection 的子接口:Set
12.6.1 Set 接口概述
Set 接口是 Collection 的子接口,Set 接口相较于 Collection 接口没有提供额外的方法。
Set 集合不允许包含相同的元素,如果试把两个相同的元素加入同一个 Set 集合中,则添加操作失败。
Set 集合支持的遍历方式和 Collection 集合一样:foreach 和 Iterator。
Set 的常用实现类有:HashSet、TreeSet、LinkedHashSet。
12.6.2 Set 主要实现类:HashSet
HashSet 是 Set 接口的主要实现类,大多数时候使用 Set 集合时都使用这个实现类。
HashSet 按 Hash 算法来存储集合中的元素,因此具有很好的存储、查找、删除性能。
HashSet 具有以下特点:
- 不能保证元素的排列顺序。
- HashSet 不是线程安全的。
- 集合元素可以是 null。
HashSet 集合判断两个元素相等的标准:两个对象通过 hashCode() 方法得到的哈希值相等,并且两个对象的 equals()方法返回值为 true。
对于存放在 Set 容器中的对象,对应的类一定要重写 hashCode()和 equals(Object obj)方法,以实现对象相等规则。即:“相等的对象必须具有相等的散列码”。
HashSet 集合中元素的无序性,不等同于随机性。这里的无序性与元素的添加位置有关。具体来说:我们在添加每一个元素到数组中时,具体的存储位置是由元素的 hashCode()调用后返回的 hash 值决定的。导致在数组中每个元素不是依次紧密存放的,表现出一定的无序性。
12.6.3 Set 实现类:LinkedHashSet
LinkedHashSet 是 HashSet 的子类,不允许集合元素重复。
LinkedHashSet 根据元素的 hashCode 值来决定元素的存储位置,但它同时使用双向链表维护元素的次序,这使得元素看起来是以添加顺序保存的。
LinkedHashSet 插入性能略低于 HashSet,但在迭代访问 Set 里的全部元素时有很好的性能。
12.6.4 Set 实现类:TreeSet
TreeSet 是 SortedSet 接口的实现类,TreeSet 可以按照添加的元素的指定的属性的大小顺序进行遍历。
TreeSet 底层使用红黑树结构存储数据。
方法:
- Comparator comparator()
- Object first()
- Object last()
- Object lower(Object e)
- Object higher(Object e)
- SortedSet subSet(fromElement, toElement)
- SortedSet headSet(toElement)
- SortedSet tailSet(fromElement)
TreeSet 特点:不允许重复、实现排序。(自然排序或定制排序)
TreeSet 两种排序方法:自然排序和定制排序。默认情况下,TreeSet 采用自然排序。
- 自然排序:TreeSet 会调用集合元素的 compareTo(Object obj) 方法来比较元素之间的大小关系,然后将集合元素按升序(默认情况)排列。
- 如果试图把一个对象添加到 TreeSet 时,则该对象的类必须实现 Comparable 接口。
- 实现 Comparable 的类必须实现 compareTo(Object obj) 方法,两个对象即通过 compareTo(Object obj) 方法的返回值来比较大小。
- 定制排序:如果元素所属的类没有实现 Comparable 接口,或不希望按照升序(默认情况)的方式排列元素或希望按照其它属性大小进行排序,则考虑使用定制排序。定制排序,通过 Comparator 接口来实现。需要重写 compare(T o1,T o2)方法。
- 利用 int compare(T o1,T o2)方法,比较 o1 和 o2 的大小:如果方法返回正整数,则表示 o1 大于 o2;如果返回 0,表示相等;返回负整数,表示 o1 小于 o2。
- 要实现定制排序,需要将实现 Comparator 接口的实例作为形参传递给 TreeSet 的构造器。
12.7 Map 接口
Java 提供了专门的集合框架用来存储这种映射关系的对象,即 java.util.Map 接口。
12.7.1 Map 接口概述
Map 与 Collection 并列存在。用于保存具有映射关系的数据:key-value。
Collection 集合称为单列集合,元素是孤立存在的。
Map 集合称为双列集合,元素是成对存在的。
Map 中的 key 和 value 都可以是任何引用类型的数据。但常用 String 类作为 Map 的“键”。
Map 接口的常用实现类:HashMap、LinkedHashMap、TreeMap 和 Properties。其中,HashMap 是 Map 接口使用频率最高的实现类。
12.7.2 Map 中 key-value 特点
这里主要以 HashMap 为例说明。HashMap 中存储的 key、value 的特点如下:
- Map 中的 key 用 Set 来存放,不允许重复,即同一个 Map 对象所对应的类,须重写 hashCode()和 equals()方法。
- key 和 value 之间存在单向一对一关系,即通过指定的 key 总能找到唯一的、确定的 value,不同 key 对应的 value 可以重复。value 所在的类要重写 equals()方法。
- key 和 value 构成一个 entry。所有的 entry 彼此之间是无序的、不可重复的。
12.7.3 Map 接口的常用方法
添加、修改操作:
- Object put(Object key,Object value):将指定 key-value 添加到(或修改)当前 map 对象中。
- void putAll(Map m):将 m 中的所有 key-value 对存放到当前 map 中。
删除操作:
- Object remove(Object key):移除指定 key 的 key-value 对,并返回 value。
- void clear():清空当前 map 中的所有数据。
元素查询的操作:
- Object get(Object key):获取指定 key 对应的 value。
- boolean containsKey(Object key):是否包含指定的 key。
- boolean containsValue(Object value):是否包含指定的 value。
- int size():返回 map 中 key-value 对的个数。
- boolean isEmpty():判断当前 map 是否为空。
- boolean equals(Object obj):判断当前 map 和参数对象 obj 是否相等。
元视图操作的方法:
- Set keySet():返回所有 key 构成的 Set 集合。
- Collection values():返回所有 value 构成的 Collection 集合。
- Set entrySet():返回所有 key-value 对构成的 Set 集合。
12.7.4 Map 的主要实现类:HashMap
HashMap 是 Map 接口使用频率最高的实现类。
HashMap 是线程不安全的。允许添加 null 键和 null 值。
存储数据采用的哈希表结构,底层使用一维数组 + 单向链表 + 红黑树进行 key-value 数据的存储。与 HashSet 一样,元素的存取顺序不能保证一致。
HashMap 判断两个 key 相等的标准是:两个 key 的 hashCode 值相等,通过 equals() 方法返回 true。
HashMap 判断两个 value 相等的标准是:两个 value 通过 equals() 方法返回 true。
12.7.5 Map 实现类:LinkedHashMap
LinkedHashMap 是 HashMap 的子类。
存储数据采用的哈希表结构+链表结构,在 HashMap 存储结构的基础上,使用了一对双向链表来记录添加元素的先后顺序,可以保证遍历元素时,与添加的顺序一致。
通过哈希表结构可以保证键的唯一、不重复,需要键所在类重写 hashCode()方法、equals()方法。
12.7.6 Map 实现类:TreeMap
TreeMap 存储 key-value 对时,需要根据 key-value 对进行排序。TreeMap 可以保证所有的 key-value 对处于有序状态。
TreeSet 底层使用红黑树结构存储数据
TreeMap 的 Key 的排序:
- 自然排序:TreeMap 的所有的 Key 必须实现 Comparable 接口,而且所有的 Key 应该是同一个类的对象,否则将会抛出 ClasssCastException。
- 定制排序:创建 TreeMap 时,构造器传入一个 Comparator 对象,该对象负责对 TreeMap 中的所有 key 进行排序。此时不需要 Map 的 Key
实现 Comparable 接口。
TreeMap 判断两个 key 相等的标准:两个 key 通过 compareTo()方法或者 compare()
方法返回 0。
12.7.7 Map 实现类:Hashtable
Hashtable 是 Map 接口的古老实现类,JDK1.0 就提供了。不同于 HashMap,Hashtable 是线程安全的。
Hashtable 实现原理和 HashMap 相同,功能相同。底层都使用哈希表结构(数组 + 单向链表),查询速度快。
与 HashMap 一样,Hashtable 也不能保证其中 Key-Value 对的顺序。
Hashtable 判断两个 key 相等、两个 value 相等的标准,与 HashMap 一致。
与 HashMap 不同,Hashtable 不允许使用 null 作为 key 或 value。
12.7.8 Map 实现类:Properties
Properties 类是 Hashtable 的子类,该对象用于处理属性文件。
由于属性文件里的 key、value 都是字符串类型,所以 Properties 中要求 key 和 value 都是字符串类型。
存取数据时,建议使用 setProperty(String key,String value)方法和 getProperty(String key)方法。
12.8 Collections 工具类
参考操作数组的工具类:Arrays,Collections 是一个操作 Set、List 和 Map 等集合的工具类。
Collections 中提供了一系列静态的方法对集合元素进行排序、查询和修改等操作,还提供了对集合对象设置不可变、对集合对象实现同步控制等方法(均为 static 方法)。
排序操作:
- reverse(List):反转 List 中元素的顺序。
- shuffle(List):对 List 集合元素进行随机排序。
- sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序。
- sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行
排序。
swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换。
查找:
- Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素。
- Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合
中的最大元素。 - Object min(Collection):根据元素的自然顺序,返回给定集合中的最小元素。
- Object min(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合
中的最小元素。 - int binarySearch(List list,T key)在 List 集合中查找某个元素的下标,但是 List 的元素必须是 T 或 T 的子类对象,而且必须是可比较大小的,即支持自然排序的。而且集合也事先必须是有序的,否则结果不确定。
- int binarySearch(List list,T key,Comparator c)在 List 集合中查找某个元素的下标,但是 List 的元素必须是 T 或 T 的子类对象,而且集合也事先必须是按照 c 比较器规则进行排序过的,否则结果不确定。
- int frequency(Collection c,Object o):返回指定集合中指定元素的出现次数。
复制、替换:
- void copy(List dest,List src):将 src 中的内容复制到 dest 中。
- boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值。
- 提供了多个 unmodifiableXxx()方法,该方法返回指定 Xxx 的不可修改的视图。
添加:
- boolean addAll(Collection c,T… elements)将所有指定元素添加到指定 collection 中。
同步:
- Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题。
12.9 企业真题
-
List,Set,Map 是否继承自 collection 接口?
答:
在 Java 中,List,Set 和 Map 是三种常用的集合类型,它们分别属于 java.util 包中的不同接口。List 和 Set 继承自 Collection 接口,而 Map 接口与 Collection 接口并无直接关系。这里是它们的关系层次:- java.util.Collection
- java.util.List
- java.util.Set
- java.util.Map
Collection 接口是 Java 集合框架的根接口,定义了一组操作集合的基本方法,如 add,remove,size 等。List 和 Set 是 Collection 接口的两个子接口,分别表示有序可重复和无序不可重复的集合。
Map 接口表示键值对的映射关系,它不能直接视为一种集合类型,因为它不继承自 Collection 接口。但是,它提供了一些方法可以将其键值对转换成 Set 或 Collection 类型的集合,例如 keySet()方法可以返回一个包含所有键的 Set 集合,values()方法可以返回一个包含所有值的 Collection 集合。
- java.util.Collection
-
说说 List,Set,Map 三者的区别?
答:
List、Set 和 Map 都是 Java 中的集合类型,它们之间的主要区别如下:
① List 是一个有序的集合,它允许重复的元素。List 中的元素可以通过索引访问,也可以使用迭代器进行遍历。
② Set 是一个不允许重复元素的集合,它不保证元素的顺序。Set 中的元素可以使用迭代器进行遍历,但不能通过索引访问。
③ Map 是一个键值对的集合,每个元素都包含一个键和一个值。Map 中的键是唯一的,但值可以重复。Map 中的元素可以使用键来访问,也可以使用迭代器进行遍历。
总的来说,List 适用于需要有序并且可以重复的元素的场景,Set 适用于需要去重并且不需要保证元素顺序的场景,Map 适用于需要按键访问值的场景。
-
写出 list、map、set 接口的实现类,并说出其特点?
答:
List、Map、Set 都是 Java 中常用的接口,它们的实现类如下:
① List 的实现类:- ArrayList:基于数组实现的 List,支持快速随机访问,但插入和删除元素的效率相对较低。
- LinkedList:基于链表实现的 List,插入和删除元素的效率比 ArrayList 高,但随机访问的效率较低。
② Map 的实现类:
- HashMap:基于哈希表实现的 Map,支持快速的插入、删除和查找操作。
- TreeMap:基于红黑树实现的 Map,支持有序遍历和范围查找。
③ Set 的实现类:
- HashSet:基于哈希表实现的 Set,支持快速的插入、删除和查找操作。
- TreeSet:基于红黑树实现的 Set,支持有序遍历和范围查找。
这些实现类的特点可以总结如下:
- ArrayList 和 LinkedList 都是有序的 List 实现,但它们的实现方式不同,因此它们的性能特点也不同。
- HashMap 和 HashSet 都是基于哈希表实现的,具有快速的插入、删除和查找操作的特点。
- TreeMap 和 TreeSet 都是基于红黑树实现的,支持有序遍历和范围查找,但相对于哈希表实现的容器,它们的插入、删除和查找操作的速度较慢。
-
常见集合类的区别和适用场景?
答:
Java 中常见的集合类包括 List、Set、Map 等,它们的区别和适用场景如下:
① List:List 是一个有序的集合,可以存储重复的元素。常见的实现类有 ArrayList 和 LinkedList。ArrayList 适用于随机访问,而 LinkedList 适用于插入和删除操作频繁的情况。
② Set:Set 是一个不允许重复元素的集合,通常用于去重。常见的实现类有 HashSet、LinkedHashSet 和 TreeSet。HashSet 是最常用的实现类,它使用哈希算法来实现元素的存储和查找,具有很好的性能。LinkedHashSet 继承自 HashSet,保留了插入顺序。TreeSet 则是基于红黑树实现的,可以对元素进行排序。
③ Map:Map 是一种键值对映射的集合,每个键只能对应一个值。常见的实现类有 HashMap、LinkedHashMap 和 TreeMap。HashMap 是最常用的实现类,它使用哈希算法来实现键值对的存储和查找,具有很好的性能。LinkedHashMap 继承自 HashMap,保留了插入顺序。TreeMap 则是基于红黑树实现的,可以对键进行排序。适用场景:
① List 适用于需要按照插入顺序存储数据、允许存储重复元素的情况。
② Set 适用于需要去重的情况。
③ Map 适用于需要按照键值对方式存储数据的情况。 -
集合的父类是谁?哪些安全的?
答:
Java 中集合的父类是 java.util.Collection。
线程安全的集合类有:
① java.util.concurrent.ConcurrentHashMap
② java.util.concurrent.CopyOnWriteArrayList
③ java.util.concurrent.CopyOnWriteArraySet
④ java.util.concurrent.ConcurrentSkipListMap
⑤ java.util.concurrent.ConcurrentSkipListSet
⑥ java.util.Collections.synchronizedList
⑦ java.util.Collections.synchronizedSet
⑧ java.util.Collections.synchronizedMap这些集合类在多线程环境下使用是安全的,因为它们内部实现了同步机制来保证线程安全。
线程不安全的集合类有:
① java.util.ArrayList
② java.util.LinkedList
③ java.util.HashSet
④ java.util.TreeSet
⑤ java.util.HashMap
⑥ java.util.TreeMap这些集合类在多线程环境下使用时可能会出现线程安全问题,需要在使用时进行同步处理来保证线程安全。
-
集合说一下哪些是线程不安全的?
答:
在 Java 集合框架中,有一些集合类是线程不安全的,也就是说在多线程环境下使用它们可能会导致数据不一致或者其他并发问题。以下是一些线程不安全的 Java 集合类:
① ArrayList- ArrayList 是一个可变数组,当多个线程同时修改同一个 ArrayList 实例时,可能会导致数据不一致问题,因为 ArrayList 内部并没有实现同步机制。
② HashMap
- HashMap 是一个哈希表,也是线程不安全的。当多个线程同时修改同一个 HashMap 实例时,可能会导致数据不一致问题,因为 HashMap 内部并没有实现同步机制。
③ HashSet
- HashSet 是一个基于 HashMap 实现的集合类,因此它也是线程不安全的。
④ LinkedList
- LinkedList 是一个链表,也是线程不安全的。当多个线程同时修改同一个 LinkedList 实例时,可能会导致数据不一致问题,因为 LinkedList 内部并没有实现同步机制。
⑤ TreeMap
- TreeMap 是一个基于红黑树实现的映射表,也是线程不安全的。当多个线程同时修改同一个 TreeMap 实例时,可能会导致数据不一致问题,因为 TreeMap 内部并没有实现同步机制。
要在多线程环境中使用这些集合类,可以考虑使用它们的线程安全版本,例如:Vector、Hashtable、ConcurrentHashMap、CopyOnWriteArrayList、CopyOnWriteArraySet 等。这些线程安全的集合类可以保证在多线程环境中使用时不会出现数据不一致或者其他并发问题。
-
遍历集合的方式有哪些?
答:
在 Java 中,遍历集合的方式主要有以下几种:
① 使用迭代器(Iterator):通过调用集合的 iterator() 方法获取迭代器,然后使用 while 循环和 hasNext()、next() 方法遍历集合中的元素。1
2
3
4
5
6
7
8
9List<String> list = new ArrayList<>();
Iterator<String> iterator = list.iterator();
while (iterator.hasNext())
{
String element = iterator.next();
// 处理元素
}② 使用增强型 for 循环(foreach):Java 5 引入了 foreach 循环,可以更方便地遍历集合中的元素。
1
2
3
4
5
6List<String> list = new ArrayList<>();
for (String element : list)
{
// 处理元素
}③ 使用 Lambda 表达式:Java 8 引入了 Lambda 表达式,可以更简洁地遍历集合中的元素。
1
2
3
4
5List<String> list = new ArrayList<>();
list.forEach(element -> {
// 处理元素
});④ 使用 Stream API:Java 8 还引入了 Stream API,可以更灵活地对集合中的元素进行过滤、转换等操作。
1
2
3
4
5List<String> list = new ArrayList<>();
list.stream().filter(element -> element.startsWith("a")).forEach(element -> {
// 处理元素
});以上是 Java 中比较常用的几种遍历集合的方式,选择具体的方式可以根据实际情况进行考虑。
-
List 下面有哪些实现?
答:
在 Java 中,List 是一个接口,它定义了一组操作有序集合元素的方法。List 接口有许多实现,其中一些最常用的包括:
① ArrayList:基于数组实现的可调整大小的列表,支持快速的随机访问和在列表末尾的常数时间添加和删除元素。
② LinkedList:基于链表实现的列表,支持 O(1)时间复杂度的添加和删除元素,但随机访问元素的时间复杂度为 O(n)。
③ Vector:与 ArrayList 类似的动态数组,但是所有公共操作都是同步的,因此效率较低,通常不推荐使用。
④ Stack:基于 Vector 实现的栈,支持 LIFO(后进先出)操作。除了这些常见的实现,还有其他一些实现可以根据具体需要选择使用,例如 CopyOnWriteArrayList、ImmutableList 等。
-
ArrayList 与 LinkedList 区别?
答:
ArrayList 和 LinkedList 是 Java 中常用的两种集合框架。它们的最主要的区别在于它们实现的数据结构不同。ArrayList 是基于数组实现的动态数组,它允许随机访问元素,因此可以通过索引快速访问集合中的任何元素。当需要频繁地访问、遍历元素时,ArrayList 的性能很好。但是,当需要在集合的中间或起始位置插入或删除元素时,需要对数组进行移动,因此这样的操作会比较耗时。
LinkedList 是基于链表实现的双向链表,它允许快速地在任何位置插入或删除元素,因为只需要改变相应节点的指针即可。但是,由于链表中每个节点都需要存储指向前后节点的指针,因此需要更多的内存空间来存储相同数量的元素。此外,由于无法随机访问元素,所以当需要访问或遍历元素时,LinkedList 的性能会比 ArrayList 差。
因此,当需要频繁地插入或删除元素时,可以选择 LinkedList,而当需要频繁地访问元素时,可以选择 ArrayList。
-
ArrayList 与 Vector 区别呢?为什么要用 ArrayList 取代 Vector 呢?
答:
ArrayList 和 Vector 都是 Java 中的集合类,它们的主要区别在于线程安全和性能方面。Vector 是线程安全的,它的所有方法都是同步的,因此在多线程环境下使用是安全的。但是,同步会带来一定的性能开销,所以在单线程环境下使用 Vector 可能会比较慢。
而 ArrayList 不是线程安全的,它的方法都不是同步的,因此在多线程环境下使用需要额外考虑线程安全的问题。但是,由于不需要同步,所以在单线程环境下使用 ArrayList 比 Vector 快。
因此,如果在多线程环境下需要使用集合类,则应使用 Vector;如果在单线程环境下使用集合类,则应使用 ArrayList。
另外,由于现在计算机的硬件性能越来越高,而且 Java 的并发编程库也越来越完善,所以在很多情况下,使用线程安全的 Vector 反而会成为性能瓶颈。因此,一般建议在单线程环境下使用 ArrayList,同时在多线程环境下使用 Java 的并发编程库中的线程安全集合类,如 ConcurrentHashMap、ConcurrentLinkedQueue 等。
-
Java.util.ArrayList 常用的方法有哪些?
答:
Java.util.ArrayList 是一个常用的动态数组类,提供了许多有用的方法来操作和管理数组元素。以下是一些常见的方法:
① add(Object obj):向列表中添加一个元素。
② add(int index, Object obj):在指定索引处添加一个元素。
③ remove(Object obj):从列表中删除指定元素。
④ remove(int index):从列表中删除指定索引处的元素。
⑤ get(int index):返回列表中指定索引处的元素。
⑥ set(int index, Object obj):将列表中指定索引处的元素替换为指定元素。
⑦ size():返回列表中元素的个数。
⑧ clear():从列表中删除所有元素。
⑨ isEmpty():如果列表为空,则返回 true,否则返回 false。
⑩ contains(Object obj):如果列表包含指定元素,则返回 true,否则返回 false。这些方法可以让您方便地操作和管理 Java.util.ArrayList 中的元素。
-
Arraylist 是有序还是无序?为什么?
答:
ArrayList 是有序的。它是一个基于数组的动态数据结构,可以根据索引访问其中的元素。插入和删除元素时,它会自动调整内部数组的大小和元素的位置,以保持元素的顺序。在 ArrayList 中,元素的顺序是按照它们添加到列表中的顺序排列的。因此,第一个添加到 ArrayList 的元素将始终是第一个元素,第二个添加的元素将始终是第二个元素,以此类推。
相比之下,HashSet 和 HashMap 是无序的,因为它们使用哈希表来存储元素,而哈希表中的元素没有特定的顺序。
-
Set 集合有哪些实现类,分别有什么特点?
答:
Java 中,Set 集合有以下实现类:
① HashSet:基于哈希表实现,不保证元素的顺序,允许使用 null 元素,具有快速的添加、删除和查找操作。
② LinkedHashSet:基于哈希表和双向链表实现,可以维护元素的插入顺序,允许使用 null 元素,具有快速的添加、删除和查找操作。
③ TreeSet:基于红黑树实现,可以按照元素的自然顺序或指定的 Comparator 进行排序,不允许使用 null 元素,具有快速的添加、删除和查找操作,但是比 HashSet 和 LinkedHashSet 慢。这些实现类都实现了 Set 接口,因此具有相同的基本功能,包括添加、删除、查找元素等。不同的实现类适用于不同的场景,可以根据需求选择合适的实现类。例如,如果需要快速的添加、删除和查找操作,可以选择 HashSet 或 LinkedHashSet;如果需要按照元素的顺序进行排序,则可以选择 TreeSet。
-
List 集合和 Set 集合的区别?
答:
在 Java 中,List 和 Set 都是集合接口,它们都可以用来存储一组对象。但是,它们有以下区别:
① 重复元素:List 允许重复元素,而 Set 不允许重复元素。如果你尝试向一个 Set 中添加已经存在的元素,它将不会被添加到 Set 中。
② 排序:List 是有序的,而 Set 是无序的。在 List 中,元素按照它们被添加的顺序排序。而 Set 中没有这种顺序,元素的顺序是不确定的。
③ 访问元素:List 可以通过索引访问元素,而 Set 不能。在 List 中,你可以通过索引来访问特定位置的元素。而在 Set 中,你需要遍历整个集合来查找特定的元素。
④ 实现类:List 有许多实现类,如 ArrayList、LinkedList 等,而 Set 只有几个主要的实现类,如 HashSet、TreeSet 等。这些实现类具有不同的性能和行为特性,你需要根据你的需求来选择合适的实现类。总之,如果你需要一个有序的集合并且允许重复元素,那么使用 List 是更好的选择;如果你需要一个不允许重复元素的无序集合,那么使用 Set 是更好的选择。
-
Set 里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用 == 还是 equals()? 它们有何区别?
答:
在 Java 中,Set 的元素是不能重复的,是通过比较对象的 equals()方法来判断元素是否重复的,而不是通过 == 运算符。== 运算符比较的是两个对象的引用是否相同,即它们是否指向同一个对象。而 equals()方法比较的是两个对象的内容是否相同,即它们的属性值是否相等。
例如,假设有一个 Person 类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23public class Person
{
private String name;
private int age;
// 构造方法和getter/setter方法省略
...
public boolean equals(Object o)
{
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}
public int hashCode()
{
return Objects.hash(name, age);
}
}在上面的代码中,equals()方法比较的是 Person 对象的属性值是否相等,而 hashCode()方法则返回一个基于属性值计算出来的哈希码,用于在 Set 中快速查找元素。
当你向一个 Set 中添加 Person 对象时,Set 会首先调用该对象的 hashCode()方法获取哈希码,然后根据哈希码找到相应的桶(bucket),再在桶中查找是否有与该对象相等的元素。如果没有找到相等的元素,该对象就会被添加到 Set 中。
如果两个 Person 对象的属性值完全相同,那么它们的 hashCode()方法返回的哈希码也应该相同,这样才能使它们被放到同一个桶中。而 equals()方法则用于在桶中查找元素时比较两个对象是否相等。
-
TreeSet 两种排序方式在使用的时候怎么起作用?
答:
在 Java 中,TreeSet 是基于红黑树实现的集合类,它可以按照元素自然顺序(natural ordering)或者通过传入的 Comparator 排序来存储元素。默认情况下,TreeSet 使用元素自然顺序进行排序。这意味着,如果要存储的元素实现了 Comparable 接口,即实现了 compareTo() 方法,那么 TreeSet 将使用该方法对元素进行排序。如果要存储的元素没有实现 Comparable 接口,那么在添加元素时会抛出 ClassCastException 异常。
如果要指定 TreeSet 使用传入的 Comparator 进行排序,需要在创建 TreeSet 对象时传入一个实现了 Comparator 接口的比较器对象。Comparator 接口中有一个 compare() 方法,可以用来比较两个元素的大小。在使用 Comparator 排序时,TreeSet 会使用该比较器对象的 compare() 方法来进行排序。
例如,以下代码演示了如何创建一个按照元素长度排序的 TreeSet:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import java.util.*;
public class Example
{
public static void main(String[] args)
{
TreeSet<String> set1 = new TreeSet<>(); // 默认排序方式
set1.add("apple");
set1.add("banana");
set1.add("orange");
System.out.println(set1); // 输出 [apple, banana, orange]
Comparator<String> comparator = new Comparator<String>()
{
public int compare(String s1, String s2)
{
return s1.length() - s2.length();
}
};
TreeSet<String> set2 = new TreeSet<>(comparator); // 指定排序方式
set2.add("apple");
set2.add("banana");
set2.add("orange");
System.out.println(set2); // 输出 [apple, orange, banana]
}
} -
TreeSet 的数据结构?
答:
Java 中的 TreeSet 是一种基于红黑树的数据结构,它实现了 SortedSet 接口,并且能够保证集合中的元素处于有序状态。TreeSet 中的元素按照它们的自然顺序进行排序,或者可以通过提供一个 Comparator 来指定排序规则。TreeSet 的基本操作包括添加、删除和查询元素,这些操作的时间复杂度都是 O(log n),其中 n 是集合中的元素个数。由于 TreeSet 维护了一个有序状态,因此它还提供了一些与有序集合相关的操作,例如获取第一个元素、获取最后一个元素、获取小于或等于给定元素的最大元素、获取大于或等于给定元素的最小元素等等。
需要注意的是,TreeSet 中不允许存储重复的元素,因为它是一个集合而不是一个列表。如果需要存储重复的元素,可以考虑使用 Java 中的其他集合类,例如 ArrayList 或 LinkedList。
-
说一下 Java 的集合 Map 有哪些 Map?
答:
Java 中的集合 Map 是一种键值对存储结构,其中每个元素由一对键和值组成。Java 提供了多种不同类型的 Map,包括:
① HashMap:基于哈希表实现,提供快速的插入、查找和删除操作。它不保证元素的顺序,也不保证在多线程环境下的并发安全性。
② TreeMap:基于红黑树实现,提供有序的插入、查找和删除操作。它按照键的自然顺序或者指定的比较器进行排序。
③ LinkedHashMap:基于哈希表和双向链表实现,保证元素的插入顺序,也可以按照访问顺序进行排序。
④ WeakHashMap:基于哈希表实现,键值对的键是“弱引用”,当键不再被引用时会自动从 Map 中删除。
⑤ IdentityHashMap:基于哈希表实现,比较键时使用对象的“身份标识”而不是“相等性”。
⑥ EnumMap:基于数组实现,键必须是枚举类型,提供了枚举类型的高效存储和访问。
⑦ ConcurrentHashMap:基于分段锁机制实现,支持高并发的插入、查找和删除操作。这些 Map 都实现了 Map 接口,提供了类似于 put、get、remove 等方法,但它们的实现方式和性能特点有所不同,开发者可以根据具体的需求选择合适的 Map 实现。
-
final 怎么用,修饰 Map 可以继续添加数据吗?
答:
在 Java 中,使用 final 关键字修饰的 Map 变量只是保证了该变量的引用不可更改,即不能再将该变量指向另一个 Map 对象。但是,Map 本身是可变的数据结构,即使使用 final 修饰,仍然可以向其中添加、删除、修改键值对。例如:
1
2
3
4
5
6
7final Map<String, Integer> map = new HashMap<>();
map.put("key1", 1);
map.put("key2", 2);
System.out.println(map); // 输出 {key1=1, key2=2}
map.put("key3", 3);
System.out.println(map); // 输出 {key1=1, key2=2, key3=3}在上面的例子中,map 变量被声明为 final,但是我们仍然可以向其中添加新的键值对,而不会引发编译错误或运行时异常。
需要注意的是,如果在初始化 Map 对象时使用了 Collections.unmodifiableMap()方法,那么得到的 Map 对象就是不可变的,任何对其的修改操作都会导致 UnsupportedOperationException 异常。
例如:
1
2final Map<String, Integer> map = Collections.unmodifiableMap(new HashMap<>());
map.put("key1", 1); // 抛出 UnsupportedOperationException 异常 -
Set 和 Map 的比较?
答:
Set 和 Map 是 Java 集合框架中两个不同的接口,它们之间有以下几个区别:
① 目的不同:Set 用于存储不重复的元素,而 Map 用于存储键值对。
② 实现方式不同:Set 使用了 HashSet、TreeSet 等实现方式,而 Map 使用了 HashMap、TreeMap 等实现方式。
③ 存储方式不同:Set 中只存储元素,而 Map 中存储键值对。
④ 访问方式不同:Set 中只能访问元素,而 Map 中可以通过键获取对应的值。
⑤ 迭代方式不同:Set 中使用迭代器遍历元素,而 Map 中使用迭代器遍历键值对或者通过遍历键或值的集合来遍历。总之,Set 和 Map 是 Java 集合框架中两个不同的接口,它们之间的区别在于目的、实现方式、存储方式、访问方式和迭代方式。在使用时需要根据实际需求选择使用哪一个接口。
-
HashMap 说一下,线程安全吗?
答:
HashMap 是 Java 中的一种数据结构,它提供了一种快速的键值对映射关系。HashMap 不是线程安全的,因为它的实现是非同步的,它不能保证在多线程环境下的正确性。在多线程环境下使用 HashMap 会存在并发访问的问题,可能会导致数据的不一致性或者抛出异常。如果需要在多线程环境下使用 HashMap,可以考虑使用 ConcurrentHashMap 或者使用同步控制来保证线程安全。ConcurrentHashMap 是线程安全的 HashMap 实现,使用了更加高效的并发控制算法,能够在多线程环境下保证线程安全和高效性能。而同步控制则可以使用 synchronized 或者 ReentrantLock 等机制来实现。
-
HashMap 和 Hashbable 的区别?
答:
HashMap 和 Hashable 是两个不同的概念。在 Java 中,HashMap 是一种基于哈希表实现的数据结构,用于存储键值对。它允许快速访问、添加和删除元素,其时间复杂度为 O(1)。HashMap 中的键和值都可以为 null。在使用 HashMap 时,需要重写 hashCode()和 equals()方法。
-
Hashtable 是怎么实现的,为什么线程安全?
答:
Hashtable 是一种将键映射到值的数据结构,其实现方式基于哈希表。在哈希表中,每个键都被映射到一个整数索引,该索引指向存储值的桶。在 Hashtable 中,每个键值对都被存储在一个 Entry 对象中,该对象包括键、值和指向下一个 Entry 对象的指针。哈希表中的每个桶都是一个链表,存储具有相同哈希值的 Entry 对象。Hashtable 是线程安全的,因为它的访问方法都是同步的。Hashtable 的每个公共方法都使用 synchronized 关键字进行同步,以确保在多线程环境下数据的正确性和一致性。当一个线程访问 Hashtable 中的一个方法时,它会获取对象的锁定,这将阻止其他线程同时访问 Hashtable。因此,Hashtable 保证了在多线程环境中的线程安全性。然而,由于同步是需要开销的,所以在高并发环境下,使用 ConcurrentHashMap 等其他并发集合可能会比 Hashtable 更高效。
-
HashMap 和 LinkedHashMap 的区别?
答:
HashMap 和 LinkedHashMap 都是 Java 中的 Map 接口的实现类,它们的主要区别在于它们维护键值对的方式不同。HashMap 使用哈希表来存储键值对,它通过将键对象的哈希码映射到内部数组中的位置来快速查找值。由于哈希表的内部结构是基于哈希函数的,所以 HashMap 的查找效率非常高。但是,由于哈希表不维护插入元素的顺序,因此 HashMap 并不保证遍历顺序和插入顺序相同。
相反,LinkedHashMap 维护了一个双向链表来保持插入顺序。它在 HashMap 的基础上添加了一个指向前一个节点和后一个节点的指针来维护插入顺序。因此,当你遍历一个 LinkedHashMap 时,它的遍历顺序就是插入顺序。
在使用 HashMap 和 LinkedHashMap 时,你需要根据自己的需求来选择不同的实现类。如果你需要高效的查找操作,并且不需要保证遍历顺序和插入顺序相同,那么 HashMap 是更好的选择。如果你需要保证遍历顺序和插入顺序相同,那么你应该使用 LinkedHashMap。
-
HashMap 和 TreeMap 的区别?
答:
HashMap 和 TreeMap 都是 Java 中常用的集合类,它们的主要区别在于实现方式和性能表现。HashMap 是基于哈希表实现的,它可以快速地进行插入、查找和删除操作,时间复杂度为 O(1)。但是 HashMap 中的元素是无序的,不支持按照键的顺序进行遍历。
TreeMap 是基于红黑树实现的,它可以自动按照键的顺序进行排序,因此支持按照键的顺序进行遍历。但是 TreeMap 的插入、查找和删除操作的时间复杂度为 O(log n),稍微慢一些。
另外,HashMap 允许 key 和 value 为 null,而 TreeMap 不允许 key 为 null。在使用 HashMap 时需要注意 key 的 hashcode 和 equals 方法的正确实现,否则可能会出现意外的结果;而在使用 TreeMap 时需要注意 key 的比较器的正确实现,否则也可能会出现意外的结果。
因此,如果需要快速地进行插入、查找和删除操作,并且不需要按照键的顺序进行遍历,可以使用 HashMap;如果需要按照键的顺序进行遍历,可以使用 TreeMap。
-
HashMap 里面实际装的是什么?
答:
在 JDK 7 中,HashMap 内部使用 Entry 类来表示键值对,每个 Entry 包含一个 key 和一个 value,并且可以用链表的形式将多个 Entry 连接起来,以处理哈希冲突。但是,在 JDK 8 中,Entry 被替换为了 Node,它与 Entry 类似,但是还包含了一个 hash 值,用于快速定位桶中的元素。通过使用 Node,JDK 8 可以更高效地处理哈希冲突,同时还可以减少在桶中存储的对象数量,从而减少了内存开销。此外,JDK 8 还引入了红黑树来优化 HashMap,当链表长度过长时,会将链表转换为红黑树,以提高性能。
-
HashMap 的 key 存储在哪里?和 value 存储在一起吗?那么 value 存储在哪里?说具体点?
答:
在 Java 中,HashMap 的 key 是存储在一个数组中的,而 value 则是存储在相应的节点(Node)中。具体来说,HashMap 是通过一个数组来实现键值对存储的,该数组中的每个元素都是一个单向链表的头节点,每个链表节点则包含了一个键值对。如果链表中的元素数量过多,链表会被转换为红黑树,以提高查找效率。下面是 HashMap 中的主要组成部分:
① 数组:HashMap 内部存储键值对的数据结构是一个数组,数组中的每个元素都是一个单向链表的头节点。
② 链表:当 HashMap 中的元素数量较少时,每个数组元素对应的链表中会存储一个或多个键值对。
③ Node:当 HashMap 中的元素数量较多时,每个数组元素对应的链表会被转换为红黑树,每个节点都是一个 Node 对象,包含了一个键值对,以及指向下一个节点的指针。
④ 红黑树:当链表中的元素数量过多时,链表会被转换为红黑树,以提高查找效率。因此,HashMap 的 key 存储在数组中,而 value 则存储在节点(Node)中,这些节点可以是链表节点或红黑树节点。每个节点都包含了一个键值对,以及指向下一个节点的指针。
-
自定义类型可以作为 Key 么?
答:
是的,Java 中自定义类型可以作为 Key。在 Java 中,作为 Key 的类型必须实现 equals()和 hashCode()方法,这是因为 Java 中的 Map 和 Set 都是基于哈希表实现的。如果自定义类型没有实现这两个方法,那么在使用 Map 或 Set 时可能会导致意外的行为。
equals()方法用于比较两个对象是否相等,通常需要比较对象的成员变量。hashCode()方法用于计算哈希码,通常需要基于对象的成员变量计算哈希码。
例如,假设我们有一个自定义类型 Person,它有两个成员变量 name 和 age:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28public class Person
{
private String name;
private int age;
public Person(String name, int age)
{
this.name = name;
this.age = age;
}
// getters and setters
public boolean equals(Object o)
{
if (this == o) return true;
if (!(o instanceof Person)) return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}
public int hashCode()
{
return Objects.hash(name, age);
}
}这里我们实现了 equals()和 hashCode()方法,使得 Person 类型可以作为 Map 或 Set 的 Key。在比较两个 Person 对象是否相等时,我们比较它们的 name 和 age 成员变量。在计算哈希码时,我们基于 name 和 age 计算哈希码。这样,我们就可以在 Map 或 Set 中使用 Person 类型作为 Key 了。
-
集合类的工具类是谁?用过工具类哪些方法?
答:
Java 中,集合类的工具类是 java.util.Collections。java.util.Collections 类提供了很多静态方法来操作集合,例如:
- sort(List
list):对给定的列表进行升序排序。 - reverse(List
list):反转给定列表中元素的顺序。 - shuffle(List<?> list):随机打乱给定列表中元素的顺序。
- binarySearch(List<? extends Comparable<? super T>> list, T key):在给定的列表中使用二分查找算法查找指定元素。
- addAll(Collection<? super T> c, T… elements):向给定的集合中添加一个或多个元素。
- frequency(Collection<?> c, Object o):返回给定集合中指定元素的出现次数。
- max(Collection<? extends T> coll):返回给定集合中的最大元素。
- min(Collection<? extends T> coll):返回给定集合中的最小元素。
这些方法是 java.util.Collections 类中的一部分,还有其他方法可供使用。使用这些方法可以方便地对集合进行操作。
- sort(List
-
Collection 和 Collections 的区别?
答:
Collection 和 Collections 是两个不同的概念。Collection 是 Java 中的一个接口,它是 Java 集合框架中的一个基础接口,定义了一些常用的集合操作方法,包括添加、删除、遍历、查询等。它是 List、Set、Queue、Deque、Map 等集合接口的父接口。
Collections 是 Java 中的一个工具类,它提供了一系列静态方法,用于操作集合对象。它包括了对集合的排序、查找、替换、填充、复制等操作。它是对 Java 集合框架的一个补充,可以方便地操作集合对象。
因此,可以看出,Collection 和 Collections 是两个不同的概念。Collection 是一个接口,定义了集合的基本操作;而 Collections 是一个工具类,提供了对集合进行操作的静态方法。
-
ArrayList 如何实现排序?
答:
在 Java 中,可以使用 Collections 类的 sort() 方法对 ArrayList 进行排序。假设要对一个 ArrayList 对象进行排序,可以按照以下步骤进行:
① 导入 java.util.Collections 类。1
import java.util.Collections;
② 调用 Collections 类的 sort() 方法,将要排序的 ArrayList 对象作为参数传递给该方法。例如,假设要对名为 list 的 ArrayList 对象进行排序,可以使用以下代码:
1
Collections.sort(list);
③ 如果要对自定义对象进行排序,则需要在该对象中实现 Comparable 接口,并重写 compareTo() 方法。compareTo() 方法用于定义对象之间的比较规则,以便在排序时进行比较。例如,假设要对一个名为 Person 的自定义类进行排序,可以使用以下代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25import java.util.Collections;
import java.util.ArrayList;
public class Person implements Comparable<Person>
{
private String name;
private int age;
// 构造方法和其他方法
// 实现 compareTo() 方法
public int compareTo(Person other)
{
// 根据年龄进行比较
return this.age - other.age;
}
}
// 在另一个类中使用 sort() 方法进行排序
ArrayList<Person> people = new ArrayList<Person>();
people.add(new Person("Alice", 25));
people.add(new Person("Bob", 30));
people.add(new Person("Charlie", 20));
Collections.sort(people);在这个例子中,Person 类实现了 Comparable 接口,并重写了 compareTo() 方法,根据年龄进行比较。在排序时,使用 Collections.sort() 对 people 列表进行排序。
-
HashMap 是否线程安全,怎样解决 HashMap 的线程不安全?
答:
HashMap 是非线程安全的数据结构,因为它不是同步的。这意味着,如果多个线程同时访 HashMap,并且其中一个线程在对其进行修改,则可能导致 HashMap 的状态不一致,从而导致数据的破坏。为了解决 HashMap 的线程不安全问题,可以采用以下几种方法:
① 使用 ConcurrentHashMap 类:ConcurrentHashMap 是 Java 中一个线程安全的 Map 实现,它使用锁分段技术来保证线程安全,使得多个线程可以同时访问不同的分段,从而提高并发性能。
② 使用 Collections.synchronizedMap()方法:该方法将 HashMap 包装成一个线程安全的 Map,使用了同步块来保证线程安全,但是性能相对较差,因为所有的操作都需要获得同步锁。
③ 使用 Lock 接口:可以使用 Java 中的 Lock 接口来实现线程安全的 HashMap,例如使用 ReentrantLock。这种方法需要手动加锁和解锁,需要注意加锁和解锁的顺序,否则可能会导致死锁。
总之,如果需要在多线程环境下使用 HashMap,应该使用线程安全的 Map 实现,例如 ConcurrentHashMap,以避免数据的破坏和不一致。
第 13 章 泛型
13.1 泛型的理解
< E > ,泛型参数,使用引用数据类型来赋值。
所谓泛型,就是允许在定义类、接口时通过一个标识表示类中某个属性的类型或者是某个方法的返回值或参数的类型。这个类型参数将在使用时(例如,继承或实现这个接口、创建对象或调用方法时)确定(即传入实际的类型参数,也称为类型实参)。
13.2 泛型在集合、比较器中的使用
Java 泛型可以保证如果程序在编译时没有发出警告,运行时就不会产生 ClassCastException 异常。即,把不安全的因素在编译期间就排除了,而不是运行期;既然通过了编译,那么类型一定是符合要求的,就避免了类型转换。同时,代码更加简洁、健壮。
把一个集合中的内容限制为一个特定的数据类型,这就是泛型背后的核心思想。
13.2.1 集合中使用泛型
Java 泛型可以在集合中用于定义集合中元素的类型。使用泛型可以确保集合中只包含指定类型的元素,避免了类型转换错误和运行时错误。下面是 Java 泛型在 List 和 Map 中的使用示例:
List 中的泛型代码示例:
1 | // 定义一个 List,元素类型为 String |
Map 中的泛型代码示例:
1 | // 定义一个 Map,键类型为 String,值类型为 Integer |
在这些示例中,泛型 < String > 和 < String, Integer > 定义了集合中元素的类型。在 List 中,我们可以将元素添加到集合中并遍历集合中的元素。在 Map 中,我们可以将键值对添加到集合中并遍历键值对。
13.2.2 比较器中使用泛型
Java 泛型可以在比较器中使用,以便于对不同类型的对象进行比较。下面是一个代码示例,演示如何使用 Java 泛型创建一个比较器:
1 | import java.util.Comparator; |
在上面的代码中,我们使用 T extends Comparable< T > 来限定泛型类型 T 必须实现 Comparable 接口,这样我们才能使用 a.compareTo(b) 方法比较两个对象的大小。
我们还可以使用 T 类型的 Comparator 对象来创建一个比较器,代码示例如下:
1 | import java.util.ArrayList; |
在上面的代码中,我们创建了一个 MyComparator 对象,并将其传递给 Collections.sort 方法进行排序。由于 MyComparator 实现了 Comparator< Integer > 接口,因此可以将其用于比较 Integer 类型的对象。最后,我们输出了排序后的结果。
注意,在上面的示例中,我们使用了 Integer 类型作为泛型类型,但实际上,任何实现了 Comparable 接口的类型都可以作为泛型类型。
13.3. 自定义泛型类、泛型接口、泛型方法
泛型(Generics)是 Java 中的一项重要特性,它可以让我们编写更加通用和类型安全的代码。Java 中的泛型可以应用于类、接口、方法等不同的场景中。
13.3.1 自定义泛型类
在 Java 中,我们可以通过在类名后面使用尖括号定义泛型参数,来创建一个泛型类。泛型类可以使用任意类型作为其参数类型,包括基本类型和引用类型。
以下是一个简单的泛型类代码示例:
1 | public class MyGenericClass<T> |
在上面的示例中,我们定义了一个名为 MyGenericClass 的泛型类,它有一个类型参数 T。在构造方法中,我们使用泛型参数 T 来定义一个数据成员 data。在 getData() 方法中,我们使用泛型参数 T 作为返回值类型。
使用泛型类时,我们需要在实例化时指定具体的类型参数。代码示例:
1 | MyGenericClass<Integer> myIntObj = new MyGenericClass<>(123); |
在上面的示例中,我们分别创建了一个 MyGenericClass 类型的对象 myIntObj 和 myStringObj,它们的类型参数分别是 Integer 和 String。
13.3.2 自定义泛型接口
在 Java 中,我们也可以定义泛型接口。定义方式与泛型类类似,只需在接口名后面添加尖括号并指定泛型参数即可。
以下是一个简单的泛型接口代码示例:
1 | public interface MyGenericInterface<T> |
在上面的示例中,我们定义了一个名为 MyGenericInterface 的泛型接口,它有一个类型参数 T。在接口中,我们定义了一个 getValue() 方法,它的返回值类型为泛型参数 T。
实现泛型接口时,需要指定具体的类型参数。代码示例:
1 | public class MyIntegerClass implements MyGenericInterface<Integer> |
在上面的示例中,我们分别实现了 MyGenericInterface 接口,并指定了具体的类型参数。MyIntegerClass 类的 getValue() 方法返回一个 Integer 类型的值,而 MyStringClass 类的 getValue() 方法返回一个 String 类型的值。
13.3.3 自定义泛型方法
除了泛型类和泛型接口外,Java 中还支持定义泛型方法。泛型方法是在方法返回类型前添加尖括号并指定泛型参数的方法。
以下是一个简单的泛型方法代码示例:
1 | public class MyGenericMethod |
在上面的示例中,我们定义了一个名为 getValue 的泛型方法,它有两个参数:一个泛型数组 arr 和一个整型变量 index。在方法返回类型前,我们使用泛型参数 T 来指定返回值类型。在方法体中,我们通过数组下标获取指定位置的元素,并返回它。
使用泛型方法时,我们可以在调用方法时指定具体的类型参数,也可以让编译器自动推断类型参数。代码示例:
1 | Integer[] intArr = {1, 2, 3}; |
在上面的示例中,我们分别调用了 MyGenericMethod.getValue() 方法,并指定了具体的类型参数。我们也可以省略类型参数,让编译器根据方法参数类型推断出类型参数。代码示例:
1 | Integer intVal = MyGenericMethod.getValue(intArr, 1); |
在上面的示例中,我们省略了类型参数,编译器根据方法参数类型自动推断出类型参数。
13.4 泛型在继承上的体现
-
类 SuperA 是类 A 的父类,则 G< SuperA > 与 G< A > 的关系:G< SuperA > 和 G< A >是并列的两个类,没有任何子父类的关系。
-
比如:ArrayList< Object > 、ArrayList< String >没有关系。
-
类 SuperA 是类 A 的父类或接口,SuperA< G > 与 A< G >的关系:SuperA< G > 与 A< G > 有继承或实现的关系。即 A< G >的实例可以赋值给 SuperA< G >类型的引用(或变量)。
-
比如:List< String > 与 ArrayList< String >。
13.5 通配符的使用
- ? 的使用
- 以集合为例:可以读取数据、不能写入数据。(例外:null)
- ? extends A
- 以集合为例:可以读取数据、不能写入数据。(例外:null)
- ? super A
- 以集合为例:可以读取数据、可以写入 A 类型或 A 类型子类的数据。(例外:null)
13.6 企业真题
-
Java 的泛型是什么?有什么好处和优点?JDK 不同版本的泛型有什么区别?
答:
Java 的泛型是一种编程语言特性,它允许在编写代码时指定一种数据类型,这种类型可以在运行时确定。具体来说,泛型可以用来创建类、接口和方法,允许在定义这些结构时使用类型参数。Java 泛型的好处和优点有很多,包括:
① 类型安全性:使用泛型可以在编译时检查类型匹配,避免在运行时出现类型错误导致的异常。
② 代码重用性:使用泛型可以编写通用代码,可以用于处理各种类型的数据,从而提高代码重用性。
③ 代码可读性:使用泛型可以使代码更加清晰和易读,因为它可以显式地指定参数类型,避免了类型转换和强制类型声明的冗余代码。
④ 更好的性能:使用泛型可以消除对象类型转换的开销,从而提高程序的性能。JDK 不同版本的泛型有一些区别,主要是在编译器的类型擦除和泛型语法的支持方面。以下是一些主要的区别:
① Java 5 之前的版本没有泛型,需要使用 Object 类型来实现类似的功能。
② Java 5 中引入了泛型,但是它的实现方式是通过类型擦除来实现的,这意味着在编译期间会将泛型类型擦除为原始类型,从而在运行时无法获得泛型类型信息。
③ Java 7 中引入了菱形语法,允许在实例化泛型类型时省略泛型类型的实际参数。
④ Java 8 中引入了类型推断,允许编译器根据上下文推断泛型类型,从而提高代码的可读性和简洁性。总的来说,泛型是 Java 语言中非常有用的特性,可以提高程序的安全性、可读性和性能,同时也有很多实际应用场景。
-
说说你对泛型的了解?
答:
泛型是一种编程语言特性,它可以让代码具有更高的灵活性和可重用性。泛型可以在类型安全的前提下,让代码适用于多种不同的数据类型,从而避免了代码的重复编写和维护,提高了代码的可维护性和可读性。在 Java 中,泛型可以用来定义类、接口和方法。通过在定义时使用类型参数(例如,T、E 等),可以将类型的具体实现推迟到使用泛型的时候再确定。这样,一个泛型类或方法可以适用于多种不同的数据类型,而不需要为每种数据类型都编写一个独立的类或方法。Java 中的泛型可以实现类型擦除,即在编译时擦除类型信息,使得泛型代码在运行时和非泛型代码一样高效。
泛型是一种非常有用的编程特性,可以提高代码的可重用性和可读性,是面向对象编程中不可或缺的一部分。
第 14 章 数据结构与集合源码
14.1 数据结构
数据结构,就是一种程序设计优化的方法论,研究数据的逻辑结构和物理结构以及它们之间相互关系,并对这种结构定义相应的运算,目的是加快程序的执行速度、减少内存占用的空间。
14.1.1 研究对象一:数据间逻辑关系
数据的逻辑结构指反映数据元素之间的逻辑关系,而与数据的存储无关,是独立于计算机的。
- 集合结构:数据结构中的元素之间除了“同属一个集合” 的相互关系外,别无其他关系。集合元素之间没有逻辑关系。
- 线性结构:数据结构中的元素存在一对一的相互关系。结构中必须存在唯一的首元素和唯一的尾元素。体现为:一维数组、链表、栈、队列。
- 树形结构:数据结构中的元素存在一对多的相互关系。
- 图形结构:数据结构中的元素存在多对多的相互关系。
14.1.2 研究对象二:数据的存储结构
数据的物理结构/存储结构:包括数据元素的表示和关系的表示。数据的存储结构是逻辑结构用计算机语言的实现,它依赖于计算机语言。
-
结构 1:顺序结构
- 顺序结构就是使用一组连续的存储单元依次存储逻辑上相邻的各个元素。
- 优点: 只需要申请存放数据本身的内存空间即可,支持下标访问,也可以实现随机访问。
- 缺点: 必须静态分配连续空间,内存空间的利用率比较低。插入或删除可能需要移动大量元素,效率比较低
-
结构 2:链式结构
- 不使用连续的存储空间存放结构的元素,而是为每一个元素构造一个节点。节点中除了存放数据本身以外,还需要存放指向下一个节点的指针。
- 优点:不采用连续的存储空间导致内存空间利用率比较高,克服顺序存储结构中预知元素个数的缺点。插入或删除元素时,不需要移动大量的元素。
- 缺点:需要额外的空间来表达数据之间的逻辑关系,不支持下标访问和随机访问。
-
结构 3:索引结构
- 除建立存储节点信息外,还建立附加的索引表来记录每个元素节点的地址。索引表由若干索引项组成。索引项的一般形式是:(关键字,地址)。
- 优点:用节点的索引号来确定结点存储地址,检索速度快。
- 缺点: 增加了附加的索引表,会占用较多的存储空间。在增加和删除数据时要修改索引表,因而会花费较多的时间。
-
结构 4:散列结构
- 根据元素的关键字直接计算出该元素的存储地址,又称为 Hash 存储。
- 优点:检索、增加和删除结点的操作都很快。
- 缺点:不支持排序,一般比用线性表存储需要更多的空间,并且记录的关键字不能重复。
14.1.3 研究对象三:运算结构
- 施加在数据上的运算包括运算的定义和实现。运算的定义是针对逻辑结构的,指出运算的功能;运算的实现是针对存储结构的,指出运算的具体操作步骤。
- 分配资源,建立结构,释放资源。
- 插入和删除。
- 获取和遍历。
- 修改和排序。
14.2 数组
在 Java 中,数组是用来存放同一种数据类型的集合,注意只能存放同一种数据类型。
物理结构特点:
- 申请内存:一次申请一大段连续的空间,一旦申请到了,内存就固定了。
- 不能动态扩展(初始化给大了,浪费;给小了,不够用),插入快,删除和查找慢。
- 存储特点:所有数据存储在这个连续的空间中,数组中的每一个元素都是一个具体的数据(或对象),所有数据都紧密排布,不能有间隔。
14.3 链表
- 逻辑结构:线性结构。
- 物理结构:不要求连续的存储空间。
- 存储特点:链表由一系列结点 node(链表中每一个元素称为结点)组成,结点可以在代码执行过程中动态创建。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
- 常见的链表结构有:单链表、双链表、循环单链表。
14.4 栈
-
栈(Stack)又称为堆栈或堆叠,是限制仅在表的一端进行插入和删除运算的线性表。
-
栈按照先进后出(FILO,first in last out)的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶。每次删除(退栈)的总是删除当前栈中最后插入(进栈)的元素,而最先插入的是被放在栈的底部,要到最后才能删除。
-
核心类库中的栈结构有 Stack 和 LinkedList。
- Stack 就是顺序栈,它是 Vector 的子类。
- LinkedList 是链式栈。
-
体现栈结构的操作方法:
- peek()方法:查看栈顶元素,不弹出。
- pop()方法:弹出栈。
- push(E e)方法:压入栈。
-
时间复杂度:
- 索引: O(n)
- 搜索: O(n)
- 插入: O(1)
- 移除: O(1)
14.5 队列
- 队列(Queue)是只允许在一端进行插入,而在另一端进行删除的运算受限的线性表。
- 队列是逻辑结构,其物理结构可以是数组,也可以是链表。
- 队列的修改原则:队列的修改是依先进先出(FIFO)的原则进行的。新来的成员总是加入队尾(即不允许"加塞"),每次离开的成员总是队列头上的(不允许中途离队),即当前"最老的"成员离队。
14.6 树与二叉树
14.6.1 树
- 结点:树中的数据元素都称之为结点。
- 根节点:最上面的结点称之为根,一颗树只有一个根且由根发展而来,从另外一个角度来说,每个结点都可以认为是其子树的根。
- 父节点:结点的上层结点。
- 子节点:节点的下层结点。
- 兄弟节点:具有相同父节点的结点称为兄弟节点。
- 结点的度数:每个结点所拥有的子树的个数称之为结点的度。
- 树叶:度数为 0 的结点,也叫作终端结点。
- 非终端节点(或分支节点):树叶以外的节点,或度数不为 0 的节点。
- 树的深度(或高度):树中结点的最大层次数。
- 结点的层数:从根节点到树中某结点所经路径上的分支树称为该结点的层数,根节点的层数规定为 1,其余结点的层数等于其父亲结点的层数 + 1。
- 同代:在同一棵树中具有相同层数的节点。
14.6.2 二叉树的基本概念
二叉树(Binary tree)是树形结构的一个重要类型。二叉树特点是每个结点最多只能有两棵子树,且有左右之分。许多实际问题抽象出来的数据结构往往是二叉树形式,二叉树的存储结构及其算法都较为简单,因此二叉树显得特别重要。
14.6.3 二叉树的遍历
-
前序遍历:中左右(根左右)
- 即先访问根结点,再前序遍历左子树,最后再前序遍历右子 树。前序遍历运算访问二叉树各结点是以根、左、右的顺序进行访问的。
-
中序遍历:左中右(左根右)
- 即先中前序遍历左子树,然后再访问根结点,最后再中序遍 历右子树。中序遍历运算访问二叉树各结点是以左、根、右的顺序进行访问的。
-
后序遍历:左右中(左右根)
- 即先后序遍历左子树,然后再后序遍历右子树,最后访问根 结点。后序遍历运算访问二叉树各结点是以左、右、根的顺序进行访问的。
14.6.4 经典二叉树
-
满二叉树: 除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树。 第 n 层的结点数是 2 的 n - 1 次方,总的结点个数是 2 的 n 次方 - 1。
-
完全二叉树: 叶结点只能出现在最底层的两层,且最底层叶结点均处于次底层叶结点的左侧。
-
二叉排序/查找/搜索树:即为 BST (binary search/sort tree)。满足如下性质:
- 若它的左子树不为空,则左子树上所有结点的值均小于它的根节点的值。
- 若它的右子树上所有结点的值均大于它的根节点的值。
- 它的左、右子树也分别为二叉排序/查找/搜索树。
-
平衡二叉树:(Self-balancing binary search tree,AVL)首先是二叉排序树,此外具有以下性质:
- 它是一棵空树或它的左右两个子树的高度差的
绝对值不超过 1。 - 并且左右两个子树也都是一棵平衡二叉树。
- 不要求非叶节点都有两个子结点。
- 它是一棵空树或它的左右两个子树的高度差的
-
平衡二叉树的目的是为了减少二叉查找树的层次,提高查找速度。平衡二叉树的常用实现有红黑树、AVL、替罪羊树、Treap、伸展树等。
-
红黑树:即 Red-Black Tree。红黑树的每个节点上都有存储位表示节点的颜色,可以是红(Red)或黑(Black)。
-
红黑树是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,它是在 1972 年由 Rudolf Bayer 发明的。红黑树是复杂的,但它的操作有着良好的最坏情况运行时间,并且在实践中是高效的:它可以在 O(log n)时间内做查找,插入和删除, 这里的 n 是树中元素的数目。
-
红黑树的特性:
- 每个节点是红色或者黑色。
- 根节点是黑色。
- 每个叶子节点(NIL)是黑色。(注意:这里叶子节点,是指为空(NIL 或 NULL)的叶子节点)
- 每个红色节点的两个子节点都是黑色的。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
- 从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点。(确保没有一条路径会比其他路径长出 2 倍)
-
当我们插入或删除节点时,可能会破坏已有的红黑树,使得它不满足以上 5 个要求,那么此时就需要进行处理,使得它继续满足以上的 5 个要求:
- recolor :将某个节点变红或变黑。
- rotation :将红黑树某些结点分支进行旋转。(左旋或右旋)
-
红黑树可以通过红色节点和黑色节点尽可能的保证二叉树的平衡。主要是用它来存储有序的数据,它的时间复杂度是 O(logN),效率非常之高。
14.7 List 接口下的实现类的源码剖析
14.7.1 List 接口特点
-
List 集合所有的元素是以一种线性方式进行存储的,例如,存元素的顺序是 11、22、33。那么集合中,元素的存储就是按照 11、22、33 的顺序完成的)。
-
它是一个元素存取有序的集合。即元素的存入顺序和取出顺序有保证。
-
它是一个带有索引的集合,通过索引就可以精确的操作集合中的元素(与数组的索引是一个道理)。
-
集合中可以有重复的元素,通过元素的 equals 方法,来比较是否为重复的元素。
-
注意:
List 集合关心元素是否有序,而不关心是否重复。 -
List 接口的主要实现类
- ArrayList:动态数组。
- Vector:动态数组。
- LinkedList:双向链表。
- Stack:栈。
14.7.2 动态数组 ArrayList 与 Vector
-
Java 的 List 接口的实现类中有两个动态数组的实现:ArrayList 和 Vector。
-
ArrayList 与 Vector 的区别
- 它们的底层物理结构都是数组,我们称为动态数组。
- ArrayList 是新版的动态数组,线程不安全,效率高,Vector 是旧版的动态数组,线程安全,效率低。
- 动态数组的扩容机制不同,ArrayList 默认扩容为原来的 1.5 倍,Vector 默认扩容增加为原来的 2 倍。
- 数组的初始化容量,如果在构建 ArrayList 与 Vector 的集合对象时,没有显式指定初始化容量,那么 Vector 的内部数组的初始容量默认为 10,而 ArrayList 在 JDK 6.0 及之前的版本也是 10,JDK8.0 之后的版本 ArrayList 初始化为长度为 0 的空数组,之后在添加第一个元素时,再创建长度为 10 的数组。
- 原因:
- 用的时候,再创建数组,避免浪费。因为很多方法的返回值是 ArrayList 类型,需要返回一个 ArrayList 的对象,例如:后期从数据库查询对象的方法,返回值很多就是 ArrayList。有可能你要查询的数据不存在,要么返回 null,要么返回一个没有元素的 ArrayList 对象。
14.7.3 ArrayList 部分源码分析
-
JDK1.7 中的源代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146// 属性
private transient Object[]elementData; // 存储底层数组元素
private int size; // 记录数组中存储的元素的个数
// 构造器
public ArrayList()
{
this(10); // 指定初始容量为 10
}
public ArrayList(int initialCapacity)
{
super();
// 检查初始容量的合法性
if(initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: " + initialCapacity);
// 数组初始化为长度为 initialCapacity 的数组
this.elementData = new Object[initialCapacity];
}
// 方法:add()相关方法
public boolean add(E e)
{
ensureCapacityInternal(size + 1); // 查看当前数组是否够多存一个元素
elementData[size++] = e; // 将元素 e 添加到 elementData 数组中
return true;
}
private void ensureCapacityInternal(int minCapacity)
{
modCount++;
// 如果 if 条件满足,则进行数组的扩容
if(minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity)
{
// overflow-conscious code
int oldCapacity = elementData.length; // 当前数组容量
int newCapacity = oldCapacity + (oldCapacity >> 1); // 新数组容量是旧数组容量的1.5倍
if(newCapacity - minCapacity < 0) // 判断旧数组的 1.5 倍是否够
newCapacity = minCapacity;
// 判断旧数组的 1.5 倍是否超过最大数组限制
if(newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 复制一个新数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
// 方法:remove()相关方法
public E remove(int index)
{
rangeCheck(index); //判断 index 是否在有效的范围内
modCount++; //修改次数加 1
// 取出[index]位置的元素,[index]位置的元素就是要被删除的元素,用于最后返回被删除的元素
E oldValue = elementData(index);
int numMoved = size - index - 1; // 确定要移动的次数
// 如果需要移动元素,就用 System.arraycopy 移动元素
if(numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index, numMoved);
//将 elementData[size-1]位置置空,让 GC 回收空间,元素个数减少
elementData[--size] = null;
return oldValue;
}
private void rangeCheck(int index)
{
if(index >= size) //index 不合法的情况
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
E elementData(int index)
{
// 返回指定位置的元素
return(E)elementData[index];
}
// 方法:set()方法相关
public E set(int index, E element)
{
rangeCheck(index); // 检验 index 是否合法
// 取出[index]位置的元素,[index]位置的元素就是要被替换的元素,用于最后返回被替换的元素
E oldValue = elementData(index);
// 用 element 替换[index]位置的元素
elementData[index] = element;
return oldValue;
}
// 方法:get()相关方法
public E get(int index)
{
rangeCheck(index); // 检验 index 是否合法
return elementData(index); // 返回[index]位置的元素
}
// 方法:indexOf()
public int indexOf(Object o)
{
// 分为 o 是否为空两种情况
if(o == null)
{
// 从前往后找
for(int i = 0; i < size; i++)
if(elementData[i] == null)
return i;
}
else
{
for(int i = 0; i < size; i++)
if(o.equals(elementData[i]))
return i;
}
return -1;
}
// 方法:lastIndexOf()
public int lastIndexOf(Object o)
{
// 分为 o 是否为空两种情况
if(o == null)
{
// 从后往前找
for(int i = size - 1; i >= 0; i--)
if(elementData[i] == null)
return i;
}
else
{
for(int i = size - 1; i >= 0; i--)
if(o.equals(elementData[i]))
return i;
}
return -1;
} -
JDK1.8 中的源代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64// 属性
transient Object[] elementData;
private int size;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
// 构造器
public ArrayList()
{
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA; // 初始化为空数组
}
// 方法:add()相关方法
public boolean add(E e)
{
// 查看当前数组是否够多存一个元素
ensureCapacityInternal(size + 1); // Increments modCount!
// 存入新元素到[size]位置,然后 size 自增 1
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity)
{
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private static int calculateCapacity(Object[] elementData, int minCapacity)
{
// 如果当前数组还是空数组
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA)
{
// 那么 minCapacity 取 DEFAULT_CAPACITY 与 minCapacity 的最大值
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
// 查看是否需要扩容
private void ensureExplicitCapacity(int minCapacity)
{
modCount++; // 修改次数加 1
// 如果需要的最小容量比当前数组的长度大,即当前数组不够存,就扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity)
{
// overflow-conscious code
int oldCapacity = elementData.length; // 当前数组容量
int newCapacity = oldCapacity + (oldCapacity >> 1); // 新数组容量是旧数组容量的 1.5 倍
// 看旧数组的 1.5 倍是否够
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 看旧数组的 1.5 倍是否超过最大数组限制
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 复制一个新数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
14.7.4 ArrayList 相关方法图示
-
ArrayList 采用数组作为底层实现
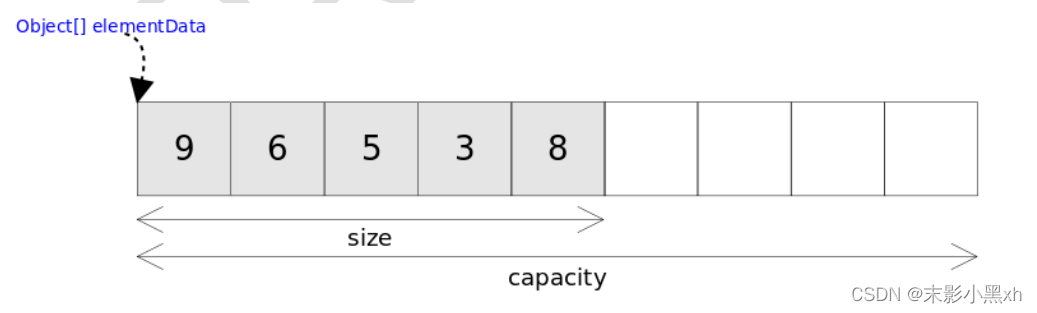
-
ArrayList 自动扩容过程
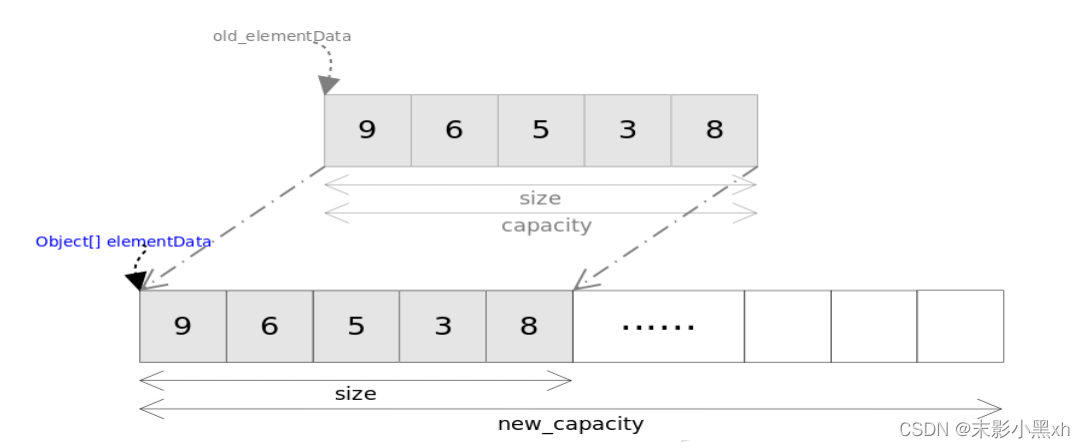
-
ArrayList 的 add(E e)方法
-
ArrayList 的 add(int index,E e)方法
14.7.5 Vector 部分源码分析
-
JDK1.8 中的源代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151// 属性
protected Object[] elementData;
protected int elementCount;
// 构造器
public Vector()
{
this(10); // 指定初始容量 initialCapacity 为 10
}
public Vector(int initialCapacity)
{
this(initialCapacity, 0); // 指定 capacityIncrement 增量为 0
}
public Vector(int initialCapacity, int capacityIncrement)
{
super();
// 判断了形参初始容量 initialCapacity 的合法性
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+ initialCapacity);
// 创建了一个 Object[]类型的数组
this.elementData = new Object[initialCapacity];
// 增量,默认是 0,如果是 0,后面就按照 2 倍增加,如果不是 0,后面就按照你指定的增量进行增量
this.capacityIncrement = capacityIncrement;
}
// 方法:add()相关方法
// synchronized 意味着线程安全的
public synchronized boolean add(E e)
{
modCount++;
// 看是否需要扩容
ensureCapacityHelper(elementCount + 1);
// 把新的元素存入[elementCount],存入后,elementCount 元素的个数增 1
elementData[elementCount++] = e;
return true;
}
private void ensureCapacityHelper(int minCapacity)
{
// 看是否超过了当前数组的容量
if (minCapacity - elementData.length > 0)
grow(minCapacity); // 扩容
}
private void grow(int minCapacity) 、
{
// overflow-conscious code
int oldCapacity = elementData.length; // 获取目前数组的长度
// 如果 capacityIncrement 增量是 0,新容量 = oldCapacity 的 2 倍
// 如果 capacityIncrement 增量是不是 0,新容量 = oldCapacity + capacityIncrement 增量;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
// 如果按照上面计算的新容量还不够,就按照你指定的需要的最小容量来扩容 minCapacity
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果新容量超过了最大数组限制,那么单独处理
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 把旧数组中的数据复制到新数组中,新数组的长度为 newCapacity
elementData = Arrays.copyOf(elementData, newCapacity);
}
//方法:remove()相关方法
public boolean remove(Object o)
{
return removeElement(o);
}
public synchronized boolean removeElement(Object obj)
{
modCount++;
// 查找 obj 在当前 Vector 中的下标
int i = indexOf(obj);
// 如果 i>=0,说明存在,删除[i]位置的元素
if (i >= 0)
{
removeElementAt(i);
return true;
}
return false;
}
// 方法:indexOf()
public int indexOf(Object o)
{
return indexOf(o, 0);
}
public synchronized int indexOf(Object o, int index)
{
if (o == null)
{
// 要查找的元素是 null 值
for (int i = index ; i < elementCount ; i++)
if (elementData[i]==null) // 如果是 null 值,用==null 判断
return i;
}
else
{
//要查找的元素是非 null 值
for (int i = index ; i < elementCount ; i++)
if (o.equals(elementData[i])) // 如果是非 null 值,用 equals 判断
return i;
}
return -1;
}
//方法:removeElementAt()
public synchronized void removeElementAt(int index)
{
modCount++;
// 判断下标的合法性
if (index >= elementCount)
{
throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount);
}
else if (index < 0)
{
throw new ArrayIndexOutOfBoundsException(index);
}
// j 是要移动的元素的个数
int j = elementCount - index - 1;
// 如果需要移动元素,就调用 System.arraycopy 进行移动
if (j > 0)
{
// 把 index+1 位置以及后面的元素往前移动
// index+1 的位置的元素移动到 index 位置,依次类推一共移动 j 个
System.arraycopy(elementData, index + 1, elementData, index, j);
}
// 元素的总个数减少
elementCount--;
// 将 elementData[elementCount]这个位置置空,用来添加新元素,位置的元素等着被 GC 回收
elementData[elementCount] = null;
/* to let gc do its work */
}
14.7.6 链表 LinkedList
Java 中有双链表的实现:LinkedList,它是 List 接口的实现类。
14.7.7 链表与动态数组的区别
- 动态数组底层的物理结构是数组,因此根据索引访问的效率非常高。但是非末尾位置的插入和删除效率不高,因为涉及到移动元素。另外添加操作时涉及到扩容问题,就会增加时空消耗。
- 链表底层的物理结构是链表,因此根据索引访问的效率不高,即查找元素慢。但是插入和删除不需要移动元素,只需要修改前后元素的指向关系即可,所以插入、删除元素快。而且链表的添加不会涉及到扩容问题。
14.7.8 LinkedList 源码分析
-
JDK1.8 中的源代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224// 属性
transient Node<E> first; // 记录第一个结点的位置
transient Node<E> last; // 记录当前链表的尾元素
transient int size = 0; // 记录最后一个结点的位置
// 构造器
public LinkedList()
{
}
// 方法:add()相关方法
public boolean add(E e)
{
linkLast(e); // 默认把新元素链接到链表尾部
return true;
}
void linkLast(E e)
{
final Node<E> l = last; // 用 l 记录原来的最后一个结点
// 创建新结点
final Node<E> newNode = new Node<>(l, e, null);
// 现在的新结点是最后一个结点了
last = newNode;
// 如果 l==null,说明原来的链表是空的
if (l == null)
// 那么新结点同时也是第一个结点
first = newNode;
else
// 否则把新结点链接到原来的最后一个结点的 next 中
l.next = newNode;
// 元素个数增加
size++;
// 修改次数增加
modCount++;
}
// 其中,Node 类定义如下
private static class Node<E>
{
E item; // 元素数据
Node<E> next; // 下一个结点
Node<E> prev; // 前一个结点
Node(Node<E> prev, E element, Node<E> next)
{
this.item = element;
this.next = next;
this.prev = prev;
}
}
// 方法:获取 get()相关方法
public E get(int index)
{
checkElementIndex(index);
return node(index).item;
}
// 方法:插入 add()相关方法
public void add(int index, E element)
{
checkPositionIndex(index); // 检查 index 范围
if (index == size) // 如果 index==size,连接到当前链表的尾部
linkLast(element);
else
linkBefore(element, node(index));
}
Node<E> node(int index)
{
assert isElementIndex(index);
/*
index < (size >> 1)采用二分思想,先将 index 与长度 size 的一半比较,
如果 index<size/2,就只从位置 0往后遍历到位置 index 处,
而如果 index>size/2,就只从位置 size 往前遍历到位置 index 处。
这样可以减少一部分不必要的遍历。
*/
// 如果 index<size/2,就从前往后找目标结点
if (index < (size >> 1))
{
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
}
else
{
// 否则从后往前找目标结点
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
// 把新结点插入到[index]位置的结点 succ 前面
void linkBefore(E e, Node<E> succ)
{
// succ 是[index]位置对应的结点
assert succ != null;
final Node<E> pred = succ.prev; // [index]位置的前一个结点
// 新结点的 prev 是原来[index]位置的前一个结点
// 新结点的 next 是原来[index]位置的结点
final Node<E> newNode = new Node<>(pred, e, succ);
// [index]位置对应的结点的 prev 指向新结点
succ.prev = newNode;
// 如果原来[index]位置对应的结点是第一个结点,那么现在新结点是第一个结点
if (pred == null)
first = newNode;
else
pred.next = newNode; // 原来[index]位置的前一个结点的 next 指向新结点
size++;
modCount++;
}
// 方法:remove()相关方法
public boolean remove(Object o)
{
// 分 o 是否为空两种情况
if (o == null)
{
// 找到 o 对应的结点 x
for (Node<E> x = first; x != null; x = x.next)
{
if (x.item == null)
{
unlink(x); // 删除 x 结点
return true;
}
}
}
else
{
// 找到 o 对应的结点 x
for (Node<E> x = first; x != null; x = x.next)
{
if (o.equals(x.item))
{
unlink(x); // 删除 x 结点
return true;
}
}
}
return false;
}
E unlink(Node<E> x)
{
// x 是要被删除的结点
assert x != null;
final E element = x.item; // 被删除结点的数据
final Node<E> next = x.next; // 被删除结点的下一个结点
final Node<E> prev = x.prev; // 被删除结点的上一个结点
// 如果被删除结点的前面没有结点,说明被删除结点是第一个结点
if (prev == null)
{
// 那么被删除结点的下一个结点变为第一个结点
first = next;
}
else
{
// 被删除结点不是第一个结点
// 被删除结点的上一个结点的 next 指向被删除结点的下一个结点
prev.next = next;
// 断开被删除结点与上一个结点的链接
x.prev = null; // 使得 GC 回收
}
// 如果被删除结点的后面没有结点,说明被删除结点是最后一个结点
if (next == null)
{
// 那么被删除结点的上一个结点变为最后一个结点
last = prev;
}
else
{
// 被删除结点不是最后一个结点
// 被删除结点的下一个结点的 prev 执行被删除结点的上一个结点
next.prev = prev;
// 断开被删除结点与下一个结点的连接
x.next = null; // 使得 GC 回收
}
// 把被删除结点的数据也置空,使得 GC 回收
x.item = null;
// 元素个数减少
size--;
// 修改次数增加
modCount++;
// 返回被删除结点的数据
return element;
}
public E remove(int index)
{
// index 是要删除元素的索引位置
checkElementIndex(index);
return unlink(node(index));
}
14.7.9 LinkedList 相关方法图示
-
只有 1 个元素的 LinkedList
-
包含 4 个元素的 LinkedList
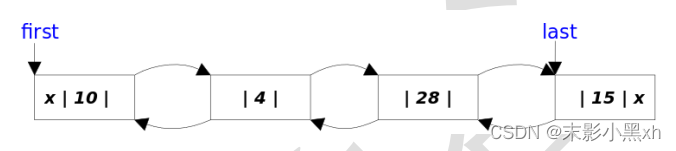
-
add(E e)方法

-
add(int index,E e)方法
-
remove(Object obj)方法
-
remove(int index)方法
14.8 Map 接口下的实现类的源码剖析
14.8.1 哈希表的物理结构
-
HashMap 和 Hashtable 底层都是哈希表(也称散列表),其中维护了一个长度为 2 的幂次方的 Entry 类型的数组 table,数组的每一个索引位置被称为一个桶(bucket),你添加的映射关系(key,value)最终都被封装为一个 Map.Entry 类型的对象,放到某个 table[index]桶中。
-
使用数组的目的是查询和添加的效率高,可以根据索引直接定位到某个 table[index]。
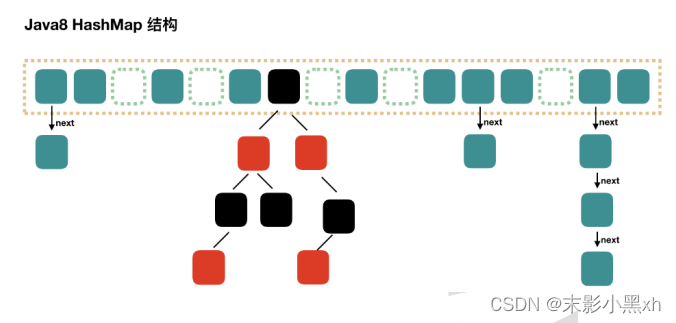
14.8.2 HashMap 中数据添加过程
-
JDK7 中过程分析:
-
在底层创建了长度为 16 的 Entry[] table 的数组。
1
2HashMap map = new HashMap();
map.put(key1,value1);-
分析过程如下:
① 将 (key1,value1) 添加到当前 hashmap 的对象中。首先会调用 key1 所在类的 hashCode() 方法,计算 key1 的哈希值 1,此哈希值 1 再经过某种运算(hash()),得到哈希值 2。此哈希值 2 再经过某种运算(indexFor()),确定在底层 table 数组中的索引位置 i。-
如果数组索引为 i 上的数据为空,则 (key1,value1) 直接添加成功,位置 1。
-
如果数组索引为 i 上的数据不为空,有 (key2,value2),则需要进一步判断:
- 判断 key1 的哈希值 2 与 key2 的哈希值是否相同:
- 如果哈希值不同,则 (key1,value1) 直接添加成功,位置 2。
- 如果哈希值相同,则需要继续调用 key1 所在类的 equals() 方法,将 key2 放入 equals() 形参进行判断:
- equals 方法返回 false:则 (key1,value1) 直接添加成功,位置 3。
- equals 方法返回 true:默认情况下,value1 会覆盖 value2。
- 位置 1:直接将 (key1,value1) 以 Entry 对象的方式存放到 table 数组索引 i 的位置。
- 位置 2、位置 3:(key1,value1) 与现有的元素以链表的方式存储在 table 数组索引 i 的位置,新添加的元素指向旧添加的元素。
② 在不断的添加的情况下,满足如下条件的情况下,会进行扩容:
1
if ((size >= threshold) && (null != table[bucketIndex])) :
默认情况下,当要添加的元素个数超过 12(即:数组的长度 * loadFactor 得到的结果)时,就要考虑扩容。
- 判断 key1 的哈希值 2 与 key2 的哈希值是否相同:
-
补充:JDK7 源码中定义的:
1
static class Entry<K,V> implements Map.Entry<K,V>
-
-
-
获取 Map 集合中 key1 对应的 value 值的操作。
1
map.get(key1);
① 计算 key1 的 hash 值,用这个方法 hash(key1)。
② 找 index = table.length-1 & hash。
③ 如果 table[index] 不为空,那么就挨个比较哪个 Entry 的 key 与它相同,就返回它的 value。 -
从 Map 集合中删除 key1 及其对应的 value 值。
1
map.remove(key1);
① 计算 key1 的 hash 值,用这个方法 hash(key1)。
② 找 index = table.length-1 & hash。
③ 如果 table[index] 不为空,那么就挨个比较哪个 Entry 的 key 与它相同,就删除它,把它前面的 Entry 的 next 的值修改为被删除 Entry 的 next。
-
-
JDK8 中过程分析:
-
下面说明是 JDK8 相较于 JDK7 的不同之处:
① 使用 HashMap()的构造器创建对象时,并没有在底层初始化长度为 16 的 table 数组。
② jdk8 中添加的 key,value 封装到了 HashMap.Node 类的对象中。而非 jdk7 中的 HashMap.Entry。
③ jdk8 中新增的元素所在的索引位置如果有其他元素。在经过一系列判断后,如果能添加,则是旧的元素指向新的元素。而非 jdk7 中的新的元素指向旧的元素。“七上八下”
④ jdk7 时底层的数据结构是:数组+单向链表。 而 jdk8 时,底层的数据结构是:数组+单向链表+红黑树。 -
红黑树出现的时机:当某个索引位置 i 上的链表的长度达到 8,且数组的长度超过 64 时,此索引位置上的元素要从单向链表改为红黑树。如果索引 i 位置是红黑树的结构,当不断删除元素的情况下,当前索引 i 位置上的元素的个数低于 6 时,要从红黑树改为单向链表。
-
14.8.3 HashMap 源码剖析
-
JDK1.7 中的源代码:
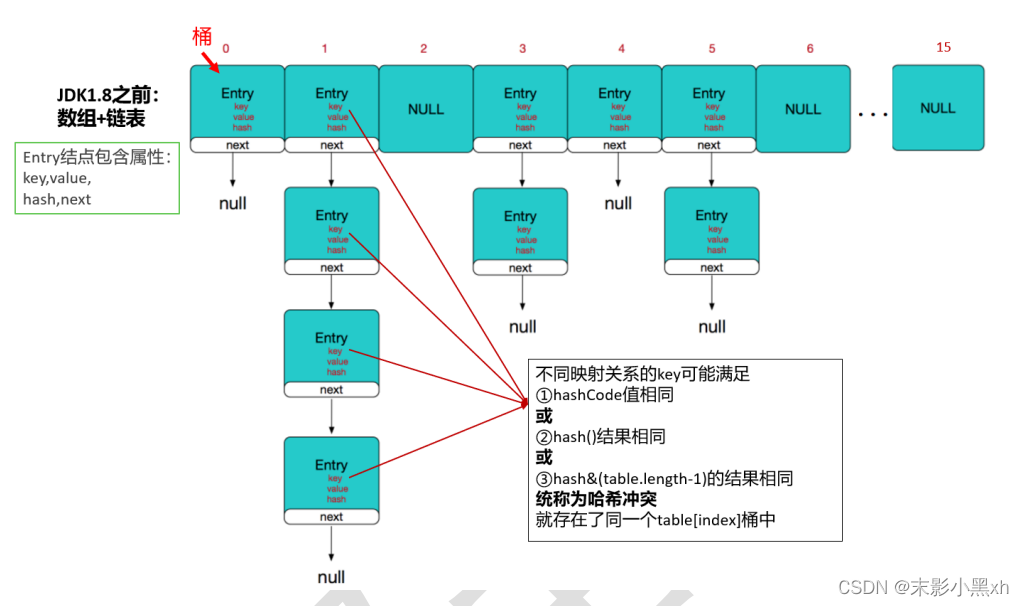
-
Entry:
key-value 被封装为 HashMap.Entry 类型,而这个类型实现了 Map.Entry 接口。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25public class HashMap<K,V>
{
transient Entry<K,V>[] table;
static class Entry<K,V> implements Map.Entry<K,V>
{
final K key;
V value;
Entry<K,V> next;
int hash;
/**
* Creates new entry.
*/
Entry(int h, K k, V v, Entry<K,V> n)
{
value = v;
next = n;
key = k;
hash = h;
}
// ......
}
} -
属性:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// table 数组的默认初始化长度
static final int DEFAULT_INITIAL_CAPACITY = 16;
// 哈希表
transient Entry<K,V>[] table;
// 哈希表中 key-value 的个数
transient int size;
// 临界值、阈值(扩容的临界值)
int threshold;
// 加载因子
final float loadFactor;
// 默认加载因子
static final float DEFAULT_LOAD_FACTOR = 0.75f; -
构造器:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37public HashMap()
{
// DEFAULT_INITIAL_CAPACITY:默认初始容量 16
// DEFAULT_LOAD_FACTOR:默认加载因子 0.75
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
public HashMap(int initialCapacity, float loadFactor)
{
// 校验 initialCapacity 合法性
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity:" + initialCapacity);
// 校验 initialCapacity 合法性
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 校验 loadFactor 合法性
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
// 计算得到 table 数组的长度(保证 capacity 是 2 的整次幂)
int capacity = 1;
while (capacity < initialCapacity)
capacity <<= 1;
// 加载因子,初始化为 0.75
this.loadFactor = loadFactor;
// threshold 初始为默认容量
threshold = (int)Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
// 初始化 table 数组
table = new Entry[capacity];
useAltHashing = sun.misc.VM.isBooted() && (capacity >= Holder.ALTERNATIVE_HASHING_THRESHOLD);
init();
} -
put()方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121public V put(K key, V value)
{
// 如果 key 是 null,单独处理,存储到 table[0]中,如果有另一个 key 为 null,value 覆盖
if (key == null)
return putForNullKey(value);
// 对 key 的 hashCode 进行干扰,算出一个 hash 值
/*
* hashCode 值 xxxxxxxxxx table.length-1 000001111
*
* hashCode 值 xxxxxxxxxx 无符号右移几位和原来的 hashCode 值做^运算, 使得 hashCode
* 高位二进制值参与计算, 也发挥作用,降低 index 冲突的概率。
*/
int hash = hash(key);
// 计算新的映射关系应该存到 table[i]位置, i = hash & table.length-1,可以保证 i
// 在[0,table.length-1]范围内
int i = indexFor(hash, table.length);
// 检查 table[i]下面有没有 key 与我新的映射关系的 key 重复,如果重复替换 value
for (Entry<K, V> e = table[i]; e != null; e = e.next)
{
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
{
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 添加新的映射关系
addEntry(hash, key, value, i);
return null;
}
// 如果 key 是 null,直接存入[0]的位置
private V putForNullKey(V value)
{
// 判断是否有重复的 key,如果有重复的,就替换 value
for (Entry<K, V> e = table[0]; e != null; e = e.next)
{
if (e.key == null)
{
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 把新的映射关系存入[0]的位置,而且 key 的 hash 值用 0 表示
addEntry(0, null, value, 0);
return null;
}
final int hash(Object k)
{
int h = 0;
if (useAltHashing)
{
if (k instanceof String)
{
return sun.misc.Hashing.stringHash32((String) k);
}
h = hashSeed;
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length)
{
return h & (length - 1);
}
void addEntry(int hash, K key, V value, int bucketIndex)
{
// 判断是否需要库容
// 扩容:(1)size 达到阈值(2)table[i]正好非空
if ((size >= threshold) && (null != table[bucketIndex]))
{
// table 扩容为原来的 2 倍,并且扩容后,会重新调整所有 key-value 的存储位置
resize(2 * table.length);
// 新的 key-value 的 hash 和 index 也会重新计算
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
// 存入 table 中
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex)
{
Entry<K, V> e = table[bucketIndex];
// 原来 table[i]下面的映射关系作为新的映射关系 next
table[bucketIndex] = new Entry<>(hash, key, value, e);
// 个数增加
size++;
}
-
-
JDK1.8 中的源代码:
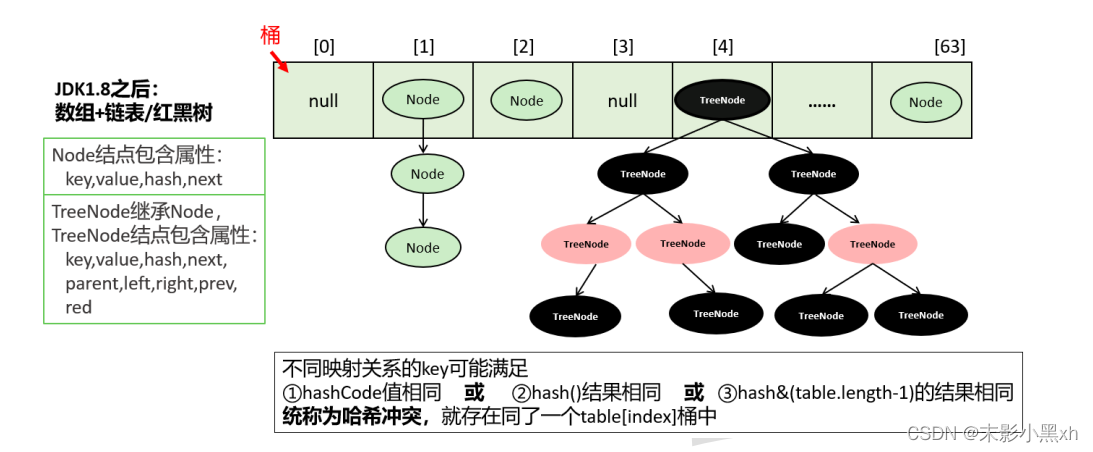
-
Node:
key-value 被封装为 HashMap.Node 类型或 HashMap.TreeNode 类型,它俩都直接或间接的实现了 Map.Entry 接口。
存储到 table 数组的可能是 Node 结点对象,也可能是 TreeNode 结点对象,它们也是 Map.Entry 接口的实现类。即 table[index]下的映射关系可能串起来一个链表或一棵红黑树。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38public class HashMap<K,V>
{
transient Node<K,V>[] table;
// Node 类
static class Node<K,V> implements Map.Entry<K,V>
{
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next)
{
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
// 其它结构:......
}
// TreeNode 类
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V>
{
TreeNode<K,V> parent;
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev;
boolean red; // 是红结点还是黑结点
TreeNode(int hash, K key, V val, Node<K,V> next)
{
super(hash, key, val, next);
}
}
//......
} -
属性:
1
2
3
4
5
6
7
8
9
10
11
12static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认的初始容量16
static final int MAXIMUM_CAPACITY = 1 << 30; // 最大容量 1 << 30
static final float DEFAULT_LOAD_FACTOR = 0.75f; // 默认加载因子
static final int TREEIFY_THRESHOLD = 8; // 默认树化阈值 8,当链表的长度达到这个值后,要考虑树化
static final int UNTREEIFY_THRESHOLD = 6; // 默认反树化阈值 6,当树中结点的个数达到此阈值后要考虑变为链表
// 当单个的链表的结点个数达到 8,并且 table 的长度达到 64,才会树化。
// 当单个的链表的结点个数达到 8,但是 table 的长度未达到 64,会先扩容
static final int MIN_TREEIFY_CAPACITY = 64; // 最小树化容量 64
transient Node<K,V>[] table; // 数组
transient int size; // 记录有效映射关系的对数,也是 Entry 对象的个数
int threshold; // 阈值,当 size 达到阈值时,考虑扩容
final float loadFactor; // 加载因子,影响扩容的频率 -
构造器:
1
2
3
4public HashMap()
{
this.loadFactor = DEFAULT_LOAD_FACTOR; // all other fields defaulted (其他字段都是默认值)
} -
put()方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290public V put(K key, V value)
{
return putVal(hash(key), key, value, false, true);
}
static final int hash(Object key)
{
int h;
// 如果 key 是 null,hash 是 0
// 如果 key 非 null,用 key 的 hashCode 值 与 key 的 hashCode 值高 16 进行异或
// 即就是用 key 的 hashCode 值高 16 位与低 16 位进行了异或的干扰运算
/*
index = hash & table.length-1
如果用 key 的原始的 hashCode 值 与 table.length-1 进行按位与,那么基本上高 16 没机会用上。
这样就会增加冲突的概率,为了降低冲突的概率,把高 16 位加入到 hash 信息中。
*/
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict)
{
Node<K,V>[] tab; // 数组
Node<K,V> p; // 一个结点
int n, i; // n 是数组的长度 i 是下标
// tab 和 table 等价
// 如果 table 是空的
if ((tab = table) == null || (n = tab.length) == 0)
{
n = (tab = resize()).length;
/*
tab = resize();
n = tab.length;*/
/*
如果 table 是空的,resize()完成了
①创建了一个长度为 16 的数组
②threshold = 12
n = 16
*/
}
// i = (n - 1) & hash ,下标 = 数组长度-1 & hash
// p = tab[i] 第 1 个结点
// if(p == null) 条件满足的话说明 table[i]还没有元素
if ((p = tab[i = (n - 1) & hash]) == null)
{
// 把新的映射关系直接放入 table[i]
tab[i] = newNode(hash, key, value, null);
// newNode()方法就创建了一个 Node 类型的新结点,新结点的 next 是 null
}
else
{
Node<K,V> e; K k;
// p 是 table[i]中第一个结点
// if(table[i]的第一个结点与新的映射关系的 key 重复)
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p; // 用 e 记录这个 table[i]的第一个结点
else if (p instanceof TreeNode)
{
//如果 table[i]第一个结点是一个树结点
//单独处理树结点
//如果树结点中,有 key 重复的,就返回那个重复的结点用 e 接收,即 e!=null
//如果树结点中,没有 key 重复的,就把新结点放到树中,并且返回 null,即 e=null
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
}
else
{
// table[i]的第一个结点不是树结点,也与新的映射关系的 key 不重复
// binCount 记录了 table[i]下面的结点的个数
for (int binCount = 0; ; ++binCount)
{
// 如果 p 的下一个结点是空的,说明当前的 p 是最后一个结点
if ((e = p.next) == null)
{
// 把新的结点连接到 table[i]的最后
p.next = newNode(hash, key, value, null);
// 如果 binCount>=8-1,达到 7 个时
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1s
// 要么扩容,要么树化
treeifyBin(tab, hash);
break;
}
// 如果 key 重复了,就跳出 for 循环,此时 e 结点记录的就是那个 key 重复的结点
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e; // 下一次循环,e=p.next,就类似于 e=e.next,往链表下移动
}
}
// 如果这个 e 不是 null,说明有 key 重复,就考虑替换原来的 value
if (e != null)
{
// existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e); // 什么也没干
return oldValue;
}
}
++modCount;
// 元素个数增加
// size 达到阈值
if (++size > threshold)
resize(); // 一旦扩容,重新调整所有映射关系的位置
afterNodeInsertion(evict); // 什么也没干
return null;
}
final Node<K,V>[] resize()
{
// oldTab 原来的 table
Node<K,V>[] oldTab = table;
// oldCap:原来数组的长度
int oldCap = (oldTab == null) ? 0 : oldTab.length;
// oldThr:原来的阈值
int oldThr = threshold;//最开始 threshold 是 0
// newCap,新容量
// newThr:新阈值
int newCap, newThr = 0;
if (oldCap > 0) // 说明原来不是空数组
{
if (oldCap >= MAXIMUM_CAPACITY) // 是否达到数组最大限制
{
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
// newCap = 旧的容量*2 ,新容量<最大数组容量限制
// 新容量:32,64,...
// oldCap >= 初始容量 16
// 新阈值重新算 = 24,48 ....
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else // zero initial threshold signifies using defaults
{
newCap = DEFAULT_INITIAL_CAPACITY; // 新容量是默认初始化容量 16
// 新阈值= 默认的加载因子 * 默认的初始化容量 = 0.75*16 = 12
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0)
{
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr; // 阈值赋值为新阈值 12,24.。。。
// 创建了一个新数组,长度为 newCap,16,32,64.。。
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) // 原来不是空数组
{
// 把原来的 table 中映射关系,倒腾到新的 table 中
for (int j = 0; j < oldCap; ++j)
{
Node<K,V> e;
if ((e = oldTab[j]) != null) // e 是 table 下面的结点
{
oldTab[j] = null; // 把旧的 table[j]位置清空
if (e.next == null) // 如果是最后一个结点
newTab[e.hash & (newCap - 1)] = e; // 重新计算 e 的在新 table 中的存储位置,然后放入
else if (e instanceof TreeNode) // 如果 e 是树结点
// 把原来的树拆解,放到新的 table
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else // preserve order
{
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
// 把原来 table[i]下面的整个链表,重新挪到了新的 table 中
do
{
next = e.next;
if ((e.hash & oldCap) == 0)
{
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else
{
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
}
while ((e = next) != null);
if (loTail != null)
{
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null)
{
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next)
{
// 创建一个新结点
return new Node<>(hash, key, value, next);
}
final void treeifyBin(Node<K,V>[] tab, int hash)
{
int n, index;
Node<K,V> e;
// MIN_TREEIFY_CAPACITY:最小树化容量 64
// 如果 table 是空的,或者 table 的长度没有达到 64
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize(); // 先扩容
else if ((e = tab[index = (n - 1) & hash]) != null)
{
// 用 e 记录 table[index]的结点的地址
TreeNode<K,V> hd = null, tl = null;
/*
do...while,把 table[index]链表的 Node 结点变为 TreeNode 类型的结点
*/
do
{
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p; // hd 记录根结点
else
{
p.prev = tl;
tl.next = p;
}
tl = p;
}
while ((e = e.next) != null);
// 如果 table[index]下面不是空
if ((tab[index] = hd) != null)
hd.treeify(tab); // 将 table[index]下面的链表进行树化
}
} -
HashMap 的 put()执行过程:
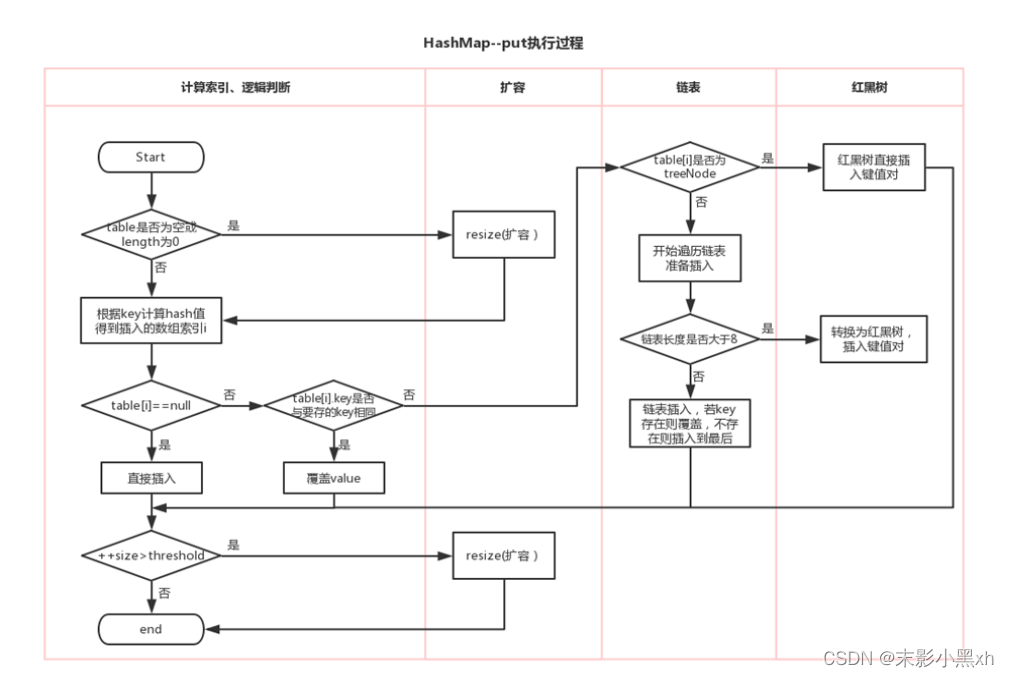
-
14.8.4 LinkedHashMap 源码剖析
-
JDK1.7 中的源代码:

-
内部定义的 Entry 如下:
1
2
3
4
5
6
7
8
9static class Entry<K,V> extends HashMap.Node<K,V>
{
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next)
{
super(hash, key, value, next);
}
} -
LinkedHashMap 重写了 HashMap 中的 newNode()方法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Node<K,V> newNode(int hash, K key, V value, Node<K,V> e)
{
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next)
{
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p);
return p;
}
-
14.9 Set 接口下的实现类的源码剖析
14.9.1 Set 集合与 Map 集合的关系
Set 的内部实现其实是一个 Map,Set 中的元素,存储在 HashMap 的 key 中。即 HashSet 的内部实现是一个 HashMap,TreeSet 的内部实现是一个 TreeMap,LinkedHashSet 的内部实现是一个 LinkedHashMap。
14.9.2 HashSet 源码剖析
-
HashSet 源代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34// 构造器
public HashSet()
{
map = new HashMap<>();
}
public HashSet(int initialCapacity, float loadFactor)
{
map = new HashMap<>(initialCapacity, loadFactor);
}
public HashSet(int initialCapacity)
{
map = new HashMap<>(initialCapacity);
}
// 这个构造器是给子类 LinkedHashSet 调用的
HashSet(int initialCapacity, float loadFactor, boolean dummy)
{
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
// add()方法:
public boolean add(E e)
{
return map.put(e, PRESENT)==null;
}
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
// iterator()方法:
public Iterator<E> iterator()
{
return map.keySet().iterator();
}
14.9.3 LinkedHashSet 源码剖析
- LinkedHashSet 源代码:
1
2
3
4
5
6
7
8
9
10
11
12
13//构造器
public LinkedHashSet()
{
super(16, .75f, true);
}
public LinkedHashSet(int initialCapacity)
{
super(initialCapacity, .75f, true); // 调用 HashSet 的某个构造器
}
public LinkedHashSet(int initialCapacity, float loadFactor)
{
super(initialCapacity, loadFactor, true); // 调用 HashSet 的某个构造器
}
14.9.4 TreeSet 源码剖析
-
TreeSet 源代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public TreeSet()
{
this(new TreeMap<E,Object>());
}
TreeSet(NavigableMap<E,Object> m)
{
this.m = m;
}
private transient NavigableMap<E,Object> m;
// add()方法:
public boolean add(E e)
{
return m.put(e, PRESENT)==null;
}
private static final Object PRESENT = new Object();
14.10 HashMap 的相关问题
14.10.1 哈希算法的理解?
hash 算法是一种可以从任何数据中提取出其“指纹”的数据摘要算法,它将任意大小的数据映射到一个固定大小的序列上,这个序列被称为 hash code、数据摘要或者指纹。比较出名的 hash 算法有 MD5、SHA。hash 是具有唯一性且不可逆的,唯一性是指相同的“对象”产生的 hash code 永远是一样的。
14.10.2 Entry 中的 hash 属性为什么不直接使用 key 的 hashCode() 返回值?
-
不管是 JDK1.7 还是 JDK1.8 中,都不是直接用 key 的 hashCode 值直接与 table.length-1 计算求下标的,而是先对 key 的 hashCode 值进行了一个运算,JDK1.7 和 JDK1.8 关于 hash()的实现代码不一样,但是不管怎么样都是为了提高 hash code 值与 (table.length-1)的按位与完的结果,尽量的均匀分布。

-
JDK1.7 中的源代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14final int hash(Object k)
{
int h = hashSeed;
if (0 != h && k instanceof String)
{
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
} -
JDK1.8 中的源代码:
1
2
3
4
5
6static final int hash(Object key)
{
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
} -
虽然算法不同,但是思路都是将 hashCode 值的高位二进制与低位二进制值进行了异或,然高位二进制参与到 index 的计算中。
- 为什么要 hashCode 值的二进制的高位参与到 index 计算呢?
- 因为一个 HashMap 的 table 数组一般不会特别大,至少在不断扩容之前,那么 table.length-1 的大部分高位都是 0,直接用 hashCode 和 table.length-1 进行& 运算的话,就会导致总是只有最低的几位是有效的,那么就算你的 hashCode() 实现的再好也难以避免发生碰撞,这时让高位参与进来的意义就体现出来了。它对 hashcode 的低位添加了随机性并且混合了高位的部分特征,显著减少了碰撞冲突的发生。
- 为什么要 hashCode 值的二进制的高位参与到 index 计算呢?
14.10.3 HashMap 是如何决定某个 key-value 存在哪个桶的?
-
因为 hash 值是一个整数,而数组的长度也是一个整数,有两种思路:
① hash 值 % table.length 会得到一个 [0,table.length - 1] 范围的值,正好是下标范围,但是用%运算效率没有位运算符&高。
②hash 值 & (table.length - 1),任何数 & (table.length - 1)的结果也一定在[0, table.length - 1]范围。 -
JDK1.7 中的源代码:
1
2
3
4
5
6
7static int indexFor(int h, int length)
{
// assert Integer.bitCount(length) == 1 : "length must be a non-z
ero power of 2";
return h & (length-1); // 此处 h 就是 hash
} -
JDK1.8 中的源代码:
1
2
3
4
5
6
7
8
9
10
11
12final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict)
{
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) // i = (n - 1) & hash
tab[i] = newNode(hash, key, value, null);
//......
}
14.10.4 为什么要保持 table 数组一直是 2 的 n 次幂?
因为如果数组的长度为 2 的 n 次幂,那么 table.length-1 的二进制就是一个高位全是 0,低位全是 1 的数字,这样才能保证每一个下标位置都有机会被用到。
14.10.5 解决[index]冲突问题?
-
虽然从设计 hashCode()到上面 HashMap 的 hash()函数,都尽量减少冲突,但是仍然存在两个不同的对象返回的 hashCode 值相同,或者 hashCode 值就算不同,通过 hash()函数计算后,得到的 index 也会存在大量的相同,因此 key 分布完全均匀的情况是不存在的。那么发生碰撞冲突时怎么办?
-
JDK1.8 之间使用:数组+链表的结构。
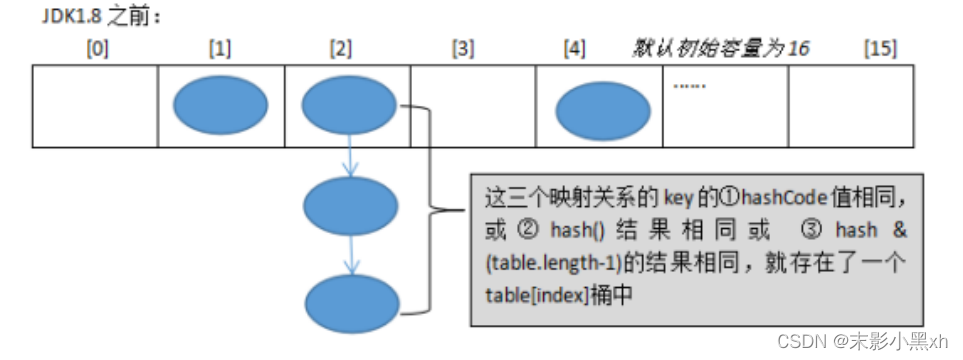
-
JDK1.8 之后使用:数组+链表/红黑树的结构。
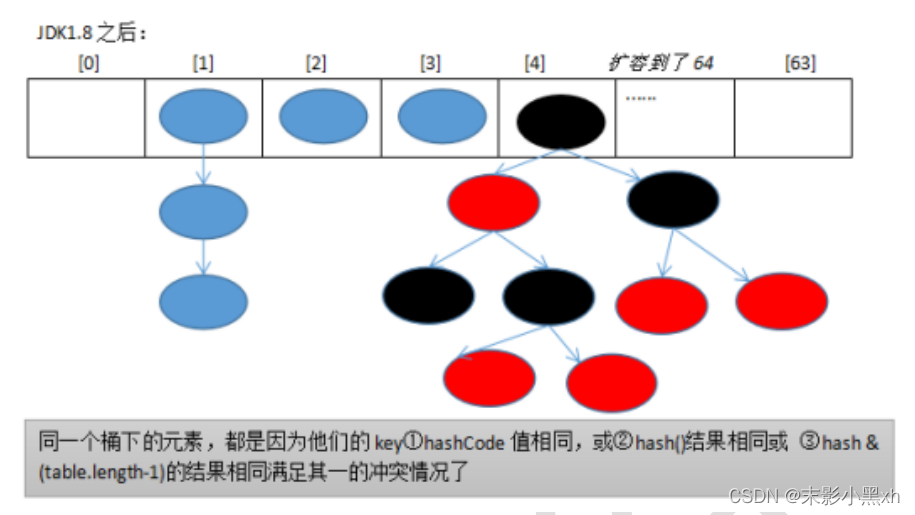
-
即 hash 相同或 hash&(table.lengt-1)的值相同,那么就存入同一个“桶”table[index]中,使用链表或红黑树连接起来。
14.10.6 为什么 JDK1.8 会出现红黑树和链表共存?
因为当冲突比较严重时,table[index]下面的链表就会很长,那么会导致查找效率大大降低,而如果此时选用二叉树可以大大提高查询效率。但是二叉树的结构又过于复杂,占用内存也较多,如果结点个数比较少的时候,那么选择链表反而更简单。所以会出现红黑树和链表共存。
14.10.7 加载因子的值大小有什么关系?
- 如果太大,threshold 就会很大,那么如果冲突比较严重的话,就会导致 table[index]下面的结点个数很多,影响效率。
- 如果太小,threshold 就会很小,那么数组扩容的频率就会提高,数组的使用率也会降低,那么会造成空间的浪费。
14.10.8 什么时候树化?什么时候反树化?
1 | static final int TREEIFY_THRESHOLD = 8; // 树化阈值 |
- 当某 table[index]下的链表的结点个数达到 8,并且 table.length>=64,那么如果新 Entry 对象还添加到该 table[index]中,那么就会将 table[index]的链表进行树化。
- 当某 table[index]下的红黑树结点个数少于 6 个,此时,
- 当继续删除 table[index]下的树结点,最后这个根结点的左右结点有 null,或根结点的左结点的左结点为 null,会反树化。
- 当重新添加新的映射关系到 map 中,导致了 map 重新扩容了,这个时候如果 table[index]下面还是小于等于 6 的个数,那么会反树化。
14.10.9 key-value 中的 key 是否可以修改?
- key-value 存储到 HashMap 中会存储 key 的 hash 值,这样就不用在每次查找时重新计算每一个 Entry 或 Node(TreeNode)的 hash 值了,因此如果已经 put 到 Map 中的 key-value,再修改 key 的属性,而这个属性又参与 hashcode 值的计算,那么会导致匹配不上。
- 这个规则也同样适用于 LinkedHashMap、HashSet、LinkedHashSet、Hashtable 等所有散列存储结构的集合。
14.10.10 JDK1.7 中 HashMap 的循环链表是怎么回事?如何解决?
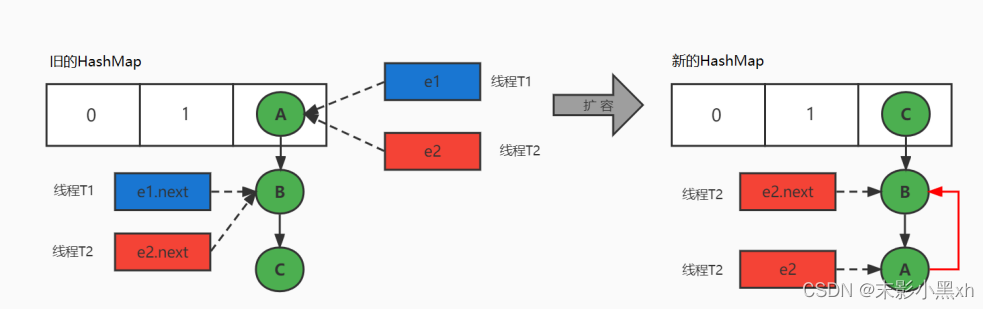
-
避免 HashMap 发生死循环的常用解决方案:
- 多线程环境下,使用线程安全的 ConcurrentHashMap 替代 HashMap,推荐。
- 多线程环境下,使用 synchronized 或 Lock 加锁,但会影响性能,不推荐。
- 多线程环境下,使用线程安全的 Hashtable 替代,性能低,不推荐。
-
HashMap 死循环只会发生在 JDK1.7 版本中,主要原因:头插法+链表+多线程并发+扩容。
-
在 JDK1.8 中,HashMap 改用尾插法,解决了链表死循环的问题。
14.11 企业真题
-
链表和数组有什么区别?
答:
链表和数组是两种不同的数据结构,它们的区别如下:
① 存储方式:数组是一块连续的内存空间,而链表是通过指针将一系列节点连接起来的。
② 插入和删除操作:在数组中,如果要插入或删除一个元素,需要将其它元素向前或向后移动以保持连续性;而在链表中,只需要修改指针即可。
③ 访问元素的效率:在数组中,可以通过下标直接访问元素,因此访问的效率比较高;而在链表中,需要从头结点开始遍历才能访问到某个节点,因此访问的效率比较低。
④ 内存的分配和释放:数组在创建时需要一次性分配连续的内存空间,而链表则可以动态地分配内存空间,只需要在需要时申请新的节点即可。总的来说,链表适合处理需要频繁插入、删除操作的情况,而数组适合处理需要快速访问元素的情况。
-
栈是如何运行的?
答:
栈是一种后进先出(LIFO)的数据结构,它的运行方式是通过将数据压入栈顶或从栈顶弹出数据来实现。当数据被压入栈顶时,它会被放置在栈顶位置,并成为当前栈顶元素;当数据从栈顶弹出时,它会被移除,并将栈顶指针指向下一个元素。栈的基本操作包括压入(push)、弹出(pop)、获取栈顶元素(top)、判断栈是否为空(isEmpty)等。在程序中,栈通常用来存储临时数据、函数调用参数和返回地址等信息。由于栈的大小是有限制的,当栈满时,会抛出栈溢出(StackOverflow)异常。 -
ArrayList 的默认大小是多少,以及扩容机制?
答:
Java 中,ArrayList 的默认大小是 10,即在创建 ArrayList 对象时,它的内部数组默认的初始大小为 10。如果在添加元素时,发现内部数组已满,则会触发扩容机制,将内部数组的大小翻倍,即扩容为原来的两倍。如果此时需要添加的元素个数超过了新的数组大小,则会再次触发扩容,以此类推。因此,ArrayList 的扩容机制是动态的,可以根据实际需要进行自适应扩容。 -
ArrayList 的底层是怎么实现的?
答:
Java 中的 ArrayList 底层是通过数组实现的。它是一个动态数组,可以自动扩容。当数组的容量不足时,会自动创建一个新的数组,将原数组中的元素复制到新数组中,然后再将新元素添加到新数组中。ArrayList 的实现主要包含以下几个关键点:
① 数组:ArrayList 底层是一个 Object 类型的数组,用于存储元素。
② size:ArrayList 中元素的个数。
③ capacity:ArrayList 数组的容量,即数组的长度。
④ add()方法:添加元素时,首先判断数组是否已满,如果已满,则创建一个新数组,并将原数组中的元素复制到新数组中,然后再将新元素添加到新数组中。
⑤ remove()方法:删除元素时,将要删除的元素后面的所有元素向前移动一位,然后将最后一个元素设为 null。
⑥ indexOf()方法:查找元素时,遍历数组,如果找到了目标元素,则返回其下标,否则返回-1。
⑦ get()和 set()方法:获取和设置元素时,通过下标直接访问数组中的元素。总之,ArrayList 底层是一个数组,通过动态扩容和数组操作实现了添加、删除、查找和获取元素等功能。
-
在 ArrayList 中 remove 后面几个元素该怎么做?
答:
在 ArrayList 中删除元素时,删除后面的元素可以直接使用 ArrayList 类中提供的 remove 方法,该方法会自动将被删除元素后面的元素向前移动一个位置,填补删除元素的空缺。例如:1
2
3
4
5
6
7
8ArrayList<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
list.add(3);
list.add(4);
list.add(5);
list.remove(2); // 删除索引为2的元素,即3
System.out.println(list); // 输出[1, 2, 4, 5]在这个例子中,删除索引为 2 的元素后,元素 4 和 5 会向前移动一个位置,填补删除元素的空缺。
-
ArrayList 在 JDK1.7 和 JDK1.8 的区别?
答:
在 JDK1.7 中,ArrayList 是基于数组实现的,它在初始化时就会创建一个默认大小的数组,并在添加元素时动态扩容。这种实现方式被称为“饿汉式”,因为在创建对象时就已经预先分配了内存空间。而在 JDK1.8 中,ArrayList 的实现方式发生了改变。它不再在初始化时创建数组,而是在第一次添加元素时才会创建一个默认大小的数组。这种实现方式被称为“懒汉式”,因为它在需要的时候才会分配内存空间。
这种改变带来了一些好处,例如减少了内存占用和初始化时间,但也带来了一些潜在的问题,例如在高并发环境下可能会出现线程安全问题。因此,在多线程环境下,最好使用线程安全的 ArrayList 实现类,例如 Vector 或 CopyOnWriteArrayList。
-
数组和 ArrayList 的区别?
答:
数组和 ArrayList 都可以用来存储一组数据,但是它们有以下区别:
① 数组长度固定,而 ArrayList 可以动态增长或缩小。
② 数组可以存储基本数据类型和对象,而 ArrayList 只能存储对象。
③ 数组可以直接访问任意元素,而 ArrayList 需要通过索引访问元素。
④ 数组的效率比 ArrayList 高,因为它不需要额外的空间来存储元素的索引。
⑤ ArrayList 提供了一些方便的方法来操作元素,如 add、remove、get、set 等,而数组需要手动实现这些方法。总的来说,ArrayList 是对数组的常见操作的封装,提供了更加方便和灵活的操作方式。但是在性能方面,数组仍然具有优势。
-
什么是线程安全的 List?
答:
在 Java 中,线程安全的 List 是指多个线程可以安全地同时访问该 List,而不会导致数据不一致或其他错误。其中,Vector 是线程安全的 List,因为它的方法都是同步的,多个线程同时访问不会导致数据不一致。而 ArrayList 是线程不安全的 List,如果多个线程同时访问,可能会导致数据不一致或其他错误。为了解决 ArrayList 的线程安全问题,可以使用同步机制进行处理,比如使用 Collections.synchronizedList 方法将其转换为线程安全的 List。另外,Java 还提供了一些更高效的线程安全的集合类,比如 JUC 包中的 ConcurrentHashMap。 -
说说 HahMap 底层实现?
答:
HashMap 底层实现主要是基于哈希表(Hash Table)和链表(LinkedList)的组合实现。具体来说,HashMap 中的元素存储在一个数组中,每个数组元素称为桶(Bucket),每个桶存储的是一个链表的头节点。当需要添加一个元素时,首先根据该元素的 hashCode()方法计算出该元素在数组中的位置,如果该位置已经有元素存在,则需要遍历该位置上的链表,找到最后一个节点,将新元素添加到该链表的尾部;如果该位置上没有元素存在,则直接将新元素添加到该位置上。
当需要查找一个元素时,首先根据该元素的 hashCode()方法计算出该元素在数组中的位置,然后遍历该位置上的链表,查找是否存在该元素。如果存在,则返回该元素;如果不存在,则返回 null。
当需要删除一个元素时,首先根据该元素的 hashCode()方法计算出该元素在数组中的位置,然后遍历该位置上的链表,查找是否存在该元素。如果存在,则将该元素从链表中删除;如果不存在,则不做任何操作。
需要注意的是,当链表中的元素数量过多时,会影响 HashMap 的性能,因为需要遍历更长的链表才能找到目标元素。因此,当链表中的元素数量超过一定阈值时,会将该链表转化为红黑树(Tree),以提高查找效率。
-
HashMap 初始值 16,临界值 12 是怎么算的?
答:
HashMap 的初始容量为 16,这是因为 HashMap 的底层实现是基于数组的,而 16 是一个比较合适的数值,可以保证在大多数情况下,存储的元素可以均匀的分布在数组中,从而达到较好的性能。临界值 12 是根据 HashMap 的负载因子(loadFactor)计算得出的。负载因子是 HashMap 中的一个参数,表示当数组中元素的数量达到总容量的百分之多少时,就需要将数组扩容。HashMap 的默认负载因子为 0.75,也就是说当元素数量达到总容量的 75%时,就需要将数组扩容。
因此,当 HashMap 的容量为 16 时,它的临界值为 16 * 0.75 = 12。当元素数量达到 12 时,就需要将数组扩容,以保证 HashMap 的性能。
-
HashMap 长度为什么是 2 的幂次方?
答:
HashMap 的长度为 2 的幂次方是为了方便计算元素的索引值,即将元素的哈希值与 HashMap 的长度进行取模运算,得到的结果就是元素在 HashMap 中的索引位置。如果 HashMap 的长度不是 2 的幂次方,那么在进行取模运算时就需要进行复杂的除法运算,降低了效率。而如果 HashMap 的长度是 2 的幂次方,那么取模运算可以转化为位运算,即对 HashMap 的长度进行按位与操作,这样可以大大提高计算效率。 -
HashMap 怎么计算哈希值和索引?扩容机制?怎么解决 hash 冲突?
答:
① HashMap 计算哈希值和索引:
HashMap 的哈希值是通过 key 的 hashCode()方法计算得出的,然后通过哈希函数计算出在数组中的索引位置。哈希函数的计算方法是将哈希值与数组长度进行取模运算,得到的余数就是 key 在数组中的索引位置。② HashMap 扩容机制:
当 HashMap 中元素的数量超过了负载因子乘以数组长度时,就会发生扩容操作。扩容操作会重新计算每个元素的哈希值和索引位置,并将元素重新放到新的数组中。扩容时,数组的长度会翻倍,同时原有的元素也会被重新分配到新的索引位置上。这个过程需要重新计算哈希值和索引位置,因此会比较耗时。
③ HashMap 解决 hash 冲突的方法:
当不同的 key 计算出的哈希值相同时,就会发生哈希冲突。HashMap 使用链表法解决哈希冲突,即在发生哈希冲突时,将新元素插入到链表的末尾。如果链表的长度超过了阈值(默认为 8),就会将链表转换为红黑树,以提高查询效率。当红黑树的节点数小于等于 6 时,会将红黑树转换回链表。
-
HashMap 底层是数组 + 链表,有数组很快了,为什么加链表?
答:
HashMap 加链表是为了解决哈希冲突问题。当不同的键值对经过哈希函数计算后,得到的哈希值相同,即发生了哈希冲突。如果直接将键值对存储在同一个数组位置上,会导致数据覆盖,因此需要在同一个数组位置上使用链表来存储多个键值对。当发生哈希冲突时,HashMap 会将新的键值对添加到链表的末尾,而不是覆盖原有的键值对。这样,当需要访问某个键值对时,HashMap 只需要遍历链表即可,不需要遍历整个数组,提高了访问效率。 -
HashMap 为什么长度达到一定的长度要转化为红黑树?
答:
在 Java 中,HashMap 是一种基于哈希表实现的数据结构。当 HashMap 中的元素数量达到一定的数量时,哈希表的性能会受到影响,因为哈希表的冲突会变得更加频繁,查找、插入、删除等操作的时间复杂度也会变高。为了解决这个问题,Java 中的 HashMap 引入了红黑树,当哈希表中的某个桶中的元素数量达到了一个阈值(默认为 8),且该桶中元素的数量大于等于 64 时,就会将该桶中的元素转化为红黑树。
红黑树的插入、查找、删除等操作的时间复杂度都是 O(logn),比单向链表的 O(n)效率高得多,因此使用红黑树可以提高 HashMap 的性能。
值得注意的是,当哈希表中的元素数量减少时,红黑树会被转化为普通的链表,这是因为链表在元素数量较少时的性能更优。
-
HashMap 什么时候扩充为红黑树,什么时候又返回到链表?
答:
在 Java 8 中,当 HashMap 的某个桶中元素数量超过 TREEIFY_THRESHOLD(默认为 8)时,该桶中的元素将被转换为红黑树,以提高查找效率。当桶中元素数量小于 UNTREEIFY_THRESHOLD(默认为 6)时,红黑树将被转换回链表,以减少空间占用。 -
在 JDK1.8 中,HashMap 的数据结构与 1.7 相比有什么变化,这些变化的好处在哪里?
答:
在 JDK1.8 中,HashMap 的数据结构发生了一些变化,具体如下:
① 初始化方式:在 JDK1.8 中,当我们创建 HashMap 实例时,底层并没有初始化 table 数组。当首次添加(key,value)时,进行判断,如果发现 table 尚未初始化,则对数组进行初始化。
② 内部类:在 JDK1.8 中,HashMap 底层定义了 Node 内部类,替换了 JDK1.7 中的 Entry 内部类。这意味着我们创建的数组是 Node[]。
③ 插入方式:在 JDK1.8 中,如果当前的(key,value)经过一系列判断之后,可以添加到当前的数组角标 i 中。如果此时角标 i 位置上有元素,旧的元素会指向新的(key,value)元素(尾插法),而在 JDK1.7 中是将新的(key,value)指向已有的旧的元素(头插法)。
④ 数据结构:在 JDK1.7 中,HashMap 使用的是数组+单向链表的数据结构。而在 JDK1.8 中,除了数组和单向链表,还使用了红黑树。当数组索引 i 位置上的元素的个数达到 8,并且数组的长度达到 64 时,会将此索引 i 位置上的多个元素改为使用红黑树的结构进行存储。使用红黑树的时间复杂度为 O(logn),比单向链表的时间复杂度 O(n)更优,因此可以提高 HashMap 的性能。当使用红黑树的索引 i 位置上的元素的个数低于 6 时,就会将红黑树结构退化为单向链表。这些变化让 HashMap 在 JDK1.8 中更加高效、可靠,提高了其性能和扩展性。
-
HashMap 的 get()方法的原理?
答:
Java 中,HashMap 的 get()方法的原理如下:
① 首先,HashMap 会根据传入的 key 计算出其对应的 hash 值。
② 然后,HashMap 会根据 hash 值找到对应的桶(bucket)。
③ 在桶中,HashMap 会遍历所有的键值对,找到与传入的 key 相等的键值对。
④ 如果找到了对应的键值对,HashMap 就会返回该键值对的 value 值。
⑤ 如果找不到对应的键值对,HashMap 就会返回 null。需要注意的是,当 HashMap 中的键值对数量很大时,遍历桶中的键值对可能会比较耗时,因此在实际使用中,应尽量保证 HashMap 中的键值对数量不要过大,以提高 get()方法的性能。
-
hashcode()和 equals()的区别?
答:
hashcode()和 equals()都是 Object 类中定义的方法,用于判断对象是否相等。但是它们的作用不同:
① hashcode()方法用于获取对象的哈希码,返回一个 int 类型的值。哈希码是根据对象的内部信息计算出来的一个数值,可以用于快速查找和比较对象。如果两个对象的 hashcode()值相等,不一定表示它们相等,但如果两个对象不相等,它们的 hashcode()值一定不相等。
② equals()方法用于比较两个对象是否相等,返回一个 boolean 类型的值。默认情况下,equals()方法比较的是对象的引用地址,即两个对象的引用地址相同才认为它们相等。但是我们可以重写 equals()方法,根据对象的内部信息来判断两个对象是否相等。如果两个对象相等,它们的 hashcode()值一定相等;如果两个对象的 hashcode()值相等,它们不一定相等,需要再调用 equals()方法进行比较。因此,hashcode()和 equals()方法是互相关联的,如果重写 equals()方法,也需要重写 hashcode()方法,保证两个方法的一致性。
-
hashCode() 与 equals() 生成算法、方法怎么重写?
答:
在 Java 中,hashCode()和 equals()方法都是用来比较对象的,其中 hashCode()方法用来获取对象的哈希码,equals()方法用来比较两个对象是否相等。重写 hashCode()方法需要注意以下几点:
① hashCode()方法的返回值应该是一个整数,通常使用对象的属性进行计算,保证相同的对象返回相同的 hashCode()值。
② hashCode()方法的计算不能依赖于对象的内存地址,因为在不同的 JVM 中,同一对象的内存地址可能不同。
③ hashCode()方法的计算应该尽量简单,避免过于复杂的计算,影响性能。重写 equals()方法需要注意以下几点:
① equals()方法应该比较对象的属性,而不是比较对象的内存地址。
② equals()方法应该满足自反性、对称性、传递性和一致性。
③ equals()方法应该检查参数是否为 null,并且检查参数类型是否相同。以下是一个示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43public class Person
{
private String name;
private int age;
// 构造函数、getter、setter
public int hashCode()
{
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result + ((name == null) ? 0 : name.hashCode());
return result;
}
public boolean equals(Object obj)
{
if (this == obj)
return true;
if (obj == null)
return false;
if (getClass() != obj.getClass())
return false;
Person other = (Person) obj;
if (age != other.age)
return false;
if (name == null)
{
if (other.name != null)
return false;
}
else if (!name.equals(other.name))
return false;
return true;
}
}在这个示例中,hashCode()方法使用了对象的 name 和 age 属性进行计算,保证相同的对象返回相同的 hashCode()值。equals()方法比较了对象的 name 和 age 属性,满足了自反性、对称性、传递性和一致性。
-
说一下 equals 和 == 的区别,然后问 equals 相等 hash 值一定相等吗?hash 值相等 equals 一定相等吗?
答:
equals 方法是用来比较两个对象的内容是否相等,而 == 操作符是用来比较两个对象的引用是否相等。在 Java 中,equals 相等的两个对象的 hash 值不一定相等,因为 hash 值是根据对象的内容计算得出的,而不是根据对象的引用。而 hash 值相等的两个对象的 equals 不一定相等,因为不同的对象可能具有相同的 hash 值,这种情况称为哈希冲突。
因此,在使用哈希表等数据结构时,需要同时实现 equals 和 hashCode 方法,并保证它们的一致性,即如果两个对象的 equals 相等,则它们的 hashCode 也相等。这样可以确保在哈希表中查找对象时能够正确地匹配对象。
-
HashSet 存放数据的方式?
答:
Java 中的 HashSet 使用哈希表(Hash Table)来存储数据。具体地说,HashSet 内部是一个 HashMap 对象,其中的键(key)就是存放的数据,值(value)则是一个固定的 Object 对象。当向 HashSet 中添加元素时,实际上是向 HashMap 中添加键值对,键为存放的数据,值为一个固定的 Object 对象。在查询元素时,HashSet 会根据哈希值(Hash Code)来快速定位元素,从而实现高效的查找。 -
Set 是如何实现元素的唯一性?
答:
Java 中的 Set 是通过 hashCode()和 equals()方法来实现元素的唯一性的。当向 Set 中添加一个元素时,首先会调用该元素的 hashCode()方法,获取该元素的哈希值。Set 会将该元素的哈希值与其他元素的哈希值进行比较,如果存在相同的哈希值,则继续调用 equals()方法进行比较。如果 equals()方法返回 true,则说明该元素已经存在于 Set 中,不会被添加;否则将该元素添加到 Set 中。
因此,为了保证元素的唯一性,需要重写该元素的 hashCode()和 equals()方法,使它们能够正确地计算元素的哈希值和比较元素的相等性。
-
用哪两种方式来实现集合的排序?
答:
Java 中可以使用以下两种方式来实现集合的排序:
① 实现 Comparable 接口在集合元素类中实现 Comparable 接口,并重写 compareTo 方法,实现元素的比较规则。然后使用 Collections.sort 方法进行排序。
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37public class Person implements Comparable<Person>
{
private String name;
private int age;
public Person(String name, int age)
{
this.name = name;
this.age = age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public int compareTo(Person o)
{
return Integer.compare(this.age, o.age);
}
}
public static void main(String[] args)
{
List<Person> list = new ArrayList<>();
list.add(new Person("Tom", 20));
list.add(new Person("Jerry", 18));
list.add(new Person("Alice", 22));
Collections.sort(list);
System.out.println(list);
}输出结果:
1
[Person{name='Jerry', age=18}, Person{name='Tom', age=20}, Person{name='Alice', age=22}]
② 实现 Comparator 接口
创建一个实现 Comparator 接口的比较器类,并重写 compare 方法,实现元素的比较规则。然后使用 Collections.sort 方法并传入比较器对象进行排序。
示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18public class PersonComparator implements Comparator<Person>
{
public int compare(Person o1, Person o2)
{
return Integer.compare(o1.getAge(), o2.getAge());
}
}
public static void main(String[] args)
{
List<Person> list = new ArrayList<>();
list.add(new Person("Tom", 20));
list.add(new Person("Jerry", 18));
list.add(new Person("Alice", 22));
Collections.sort(list, new PersonComparator());
System.out.println(list);
}输出结果:
1
[Person{name='Jerry', age=18}, Person{name='Tom', age=20}, Person{name='Alice', age=22}]
以上两种方式都可以实现集合的排序,但实现 Comparable 接口的方式更加方便,因为不需要创建额外的比较器类。但是,如果需要实现多种比较规则,或者对已有的类进行排序,就需要使用实现 Comparator 接口的方式。
第 15 章 File 类与 IO 流
15.1 File 类
15.1.1 File 类的概述
File 类及本章下的各种流,都定义在 java.io 包下。
一个 File 对象代表硬盘或网络中可能存在的一个文件或者文件目录,与平台无关。
File 能新建、删除、重命名文件和目录,但 File 不能访问文件内容本身。如果需要访问文件内容本身,则需要使用输入、输出流。
- File 对象可以作为参数传递给流的构造器。
想要在 Java 程序中表示一个真实存在的文件或目录,那么必须有一个 File 对象,但是 Java 程序中的一个 File 对象,可能没有一个真实存在的文件或目录。
15.1.2 File 类的构造器
-
public File(String pathname) :以 pathname 为路径创建 File 对象,可以是绝对路径或者相对路径,如果 pathname 是相对路径,则默认的当前路径在系统属性 user.dir 中存储。
-
public File(String parent, String child) :以 parent 为父路径,child 为子路径创建 File 对象。
-
public File(File parent, String child) :根据一个父 File 对象和子文件路径创建 File 对象。
-
关于路径:
- 绝对路径:从盘符开始的路径,这是一个完整的路径。
- 相对路径:相对于项目目录的路径,这是一个便捷的路径,开发中经常使用。
- IDEA 中,main 中的文件的相对路径,是相对于"当前工程"。
- IDEA 中,单元测试方法中的文件的相对路径,是相对于"当前 module"。
15.1.3 File 类的常用方法
获取文件和目录基本信息:
- public String getName() :获取名称。
- public String getPath() :获取路径。
- public String getAbsolutePath():获取绝对路径。
- public File getAbsoluteFile():获取绝对路径表示的文件。
- public String getParent():获取上层文件目录路径。若无,返回 null。
- public long length() :获取文件长度(即:字节数)。不能获取目录的长度。
- public long lastModified() :获取最后一次的修改时间,毫秒值。
列出目录的下一级:
- public String[] list() :返回一个 String 数组,表示该 File 目录中的所有子文件或目录。
- public File[] listFiles() :返回一个 File 数组,表示该 File 目录中的所有的子文件或目
录。
File 类的重命名功能:
- public boolean renameTo(File dest):把文件重命名为指定的文件路径。
判断功能的方法:
- public boolean exists() :此 File 表示的文件或目录是否实际存在。
- public boolean isDirectory() :此 File 表示的是否为目录。
- public boolean isFile() :此 File 表示的是否为文件。
- public boolean canRead() :判断是否可读。
- public boolean canWrite() :判断是否可写。
- public boolean isHidden() :判断是否隐藏。
创建、删除功能:
- public boolean createNewFile() :创建文件。若文件存在,则不创建,返回 false。
- public boolean mkdir() :创建文件目录。如果此文件目录存在,就不创建了。如果此文件目录的上层目录不存在,也不创建。
- public boolean mkdirs() :创建文件目录。如果上层文件目录不存在,一并创建。
- public boolean delete() :删除文件或者文件夹 删除注意事项:
① Java 中的删除不走回收站。
② 要删除一个文件目录,请注意该文件目录内不能包含文件或者文件目录。
15.2 IO 流
15.2.1 IO 流的概述
Java 程序中,对于数据的输入、输出操作以“流(stream)” 的方式进行,可以看做是一种数据的流动。
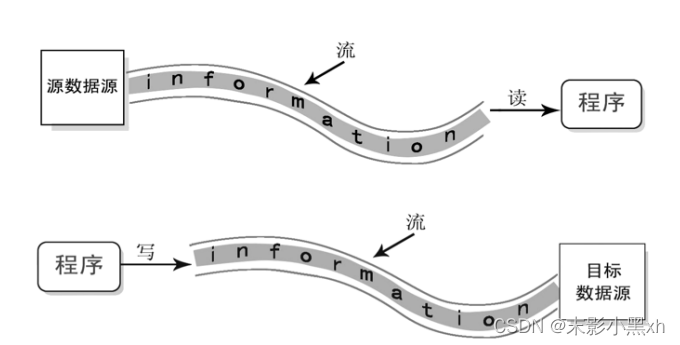
I/O 流中的 I/O 是 Input/Output 的缩写, I/O 技术是非常实用的技术,用于处理设备之间的数据传输。如读/写文件,网络通讯等。
- 输入 input:读取外部数据(磁盘、光盘等存储设备的数据)到程序(内存)中。
- 输出 output:将程序(内存)数据输出到磁盘、光盘等存储设备中。
15.2.2 IO 流的分类
- 按数据的流向不同分为:输入流和输出流。
- 输入流 :把数据从其他设备上读取到内存中的流。以 InputStream、Reader 结尾。
- 输出流 :把数据从内存 中写出到其他设备上的流。以 OutputStream、Writer 结尾。
- 按操作数据单位的不同分为:字节流(8bit)和字符流(16bit)。
- 字节流 :以字节为单位,读写数据的流。以 InputStream、OutputStream 结尾。
- 字符流 :以字符为单位,读写数据的流。以 Reader、Writer 结尾。
- 根据 IO 流的角色不同分为:节点流和处理流。
- 节点流:直接从数据源或目的地读写数据。
- 处理流:不直接连接到数据源或目的地,而是“连接”在已存在的流(节点流或处理流)之上,通过对数据的处理为程序提供更为强大的读写功能。
15.2.3 IO 流的 API
IO 的 4 个抽象基类:InputStream 、 OutputStream 、 Reader 、 Writer。
常用的节点流:
- 文件流: FileInputStream、FileOutputStrean、FileReader、FileWriter
- 字节/字符数组流: ByteArrayInputStream、ByteArrayOutputStream、
CharArrayReader、CharArrayWriter - 对数组进行处理的节点流(对应的不再是文件,而是内存中的一个数组)。
常用处理流:
- 缓冲流:BufferedInputStream、BufferedOutputStream、BufferedReader、
BufferedWriter - 作用:增加缓冲功能,避免频繁读写硬盘,进而提升读写效率。 - 转换流:InputStreamReader、OutputStreamReader
- 作用:实现字节流和字符流之间的转换。
- 对象流:ObjectInputStream、ObjectOutputStream
- 作用:提供直接读写 Java 对象功能。
15.3 节点流之一:FileReader、FileWriter
15.3.1 字符输入流:Reader
- java.io.Reader 抽象类是表示用于读取字符流的所有类的父类,可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
- public int read(): 从输入流读取一个字符。 虽然读取了一个字符,但是会自动提升为 int 类型。返回该字符的 Unicode 编码值。如果已经到达流末尾了,则返回 -1。
- public int read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组 cbuf 中 。每次最多读取 cbuf.length 个字符。返回实际读取的字符个数。如果已经到达流末尾,没有数据可读,则返回 -1。
- public int read(char[] cbuf,int off,int len):从输入流中读取一些字符,并将它们存储到字符数组 cbuf 中,从 cbuf[off]开始的位置存储。每次最多读取 len 个字符。返回实际读取的字符个数。如果已经到达流末尾,没有数据可读,则返回 -1。
- public void close() :关闭此流并释放与此流相关联的任何系统资源。
- 注意:当完成流的操作时,必须调用 close()方法,释放系统资源,否则会造成内存泄漏。
15.3.2 字符输出流:Writer
- java.io.Writer 抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。它定义了字节输出流的基本共性功能方法。
- public void write(int c) :写出单个字符。
- public void write(char[] cbuf):写出字符数组。
- public void write(char[] cbuf, int off, int len):写出字符数组的某一部分。off:数组的开始索引;len:写出的字符个数。
- public void write(String str):写出字符串。
- public void write(String str, int off, int len) :写出字符串的某一部分。off:字符串的开始索引;len:写出的字符个数。
- public void flush():刷新该流的缓冲。
- public void close() :关闭此流。
- 注意:当完成流的操作时,必须调用 close()方法,释放系统资源,否则会造成内存泄漏。
15.3.3 文件字符输入流:FileReader
- java.io.FileReader 类用于读取字符文件,构造时使用系统默认的字符编码和默认字节缓冲区。
- FileReader(File file): 创建一个新的 FileReader ,给定要读取的 File 对象。
- FileReader(String fileName): 创建一个新的 FileReader ,给定要读取的文件的名称。
15.3.4 文件字符输出流:FileWriter
- java.io.FileWriter 类用于写出字符到文件,构造时使用系统默认的字符编码和默认字节缓冲区。
- FileWriter(File file): 创建一个新的 FileWriter,给定要读取的 File 对象。
- FileWriter(String fileName): 创建一个新的 FileWriter,给定要读取的文件的名称。
- FileWriter(File file,boolean append): 创建一个新的 FileWriter,指明是否在现有文件末尾追加内容。
15.3.5 关于 flush(刷新)
- 因为内置缓冲区的原因,如果 FileWriter 不关闭输出流,无法写出字符到文件中。但是关闭的流对象,是无法继续写出数据的。如果我们既想写出数据,又想继续使用流,就需要 flush() 方法了。
- flush() :刷新缓冲区,流对象可以继续使用。
- close():先刷新缓冲区,然后通知系统释放资源。流对象不可以再被使用了。
- 注意:即便是 flush()方法写出了数据,操作的最后还是要调用 close 方法,释放系统资源。
15.4 节点流之二:FileInputStream、FileOutputStream
15.4.1 字节输入流:InputStream
- java.io.InputStream 抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
- public int read(): 从输入流读取一个字节。返回读取的字节值。虽然读取了一个字节,但是会自动提升为 int 类型。如果已经到达流末尾,没有数据可读,则返回 -1。
- public int read(byte[] b): 从输入流中读取一些字节数,并将它们存储到字节数组 b 中 。每次最多读取 b.length 个字节。返回实际读取的字节个数。如果已经到达流末尾,没有数据可读,则返回 -1。
- public int read(byte[] b,int off,int len):从输入流中读取一些字节数,并将它们存储到字节数组 b 中,从 b[off]开始存储,每次最多读取 len 个字节。返回实际读取的字节个数。如果已经到达流末尾,没有数据可读,则返回 -1。
- public void close() :关闭此输入流并释放与此流相关联的任何系统资源。
- 注意:close()方法,当完成流的操作时,必须调用此方法,释放系统资源。
15.4.2 字节输出流:OutputStream
- java.io.OutputStream 抽象类是表示字节输出流的所有类的超类,将指定的字节信息写出到目的地。它定义了字节输出流的基本共性功能方法。
- public void write(int b) :将指定的字节输出流。虽然参数为 int 类型四个字节,但是只会保留一个字节的信息写出。
- public void write(byte[] b):将 b.length 字节从指定的字节数组写入此输出流。
- public void write(byte[] b, int off, int len) :从指定的字节数组写入 len 字节,从偏移量 off 开始输出到此输出流。
- public void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。
- public void close() :关闭此输出流并释放与此流相关联的任何系统资源。
- 注意:close()方法,当完成流的操作时,必须调用此方法,释放系统资源。
15.4.3 文件字节输入流:FileInputStream
- java.io.FileInputStream 类是文件输入流,从文件中读取字节。
- FileInputStream(File file): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File 对象 file 命名。
- FileInputStream(String name): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name 命名。
15.4.4 文件字节输出流: FileOutputStream
- java.io.FileOutputStream 类是文件输出流,用于将数据写出到文件。
- public FileOutputStream(File file):创建文件输出流,写出由指定的 File 对象表示的文件。
- public FileOutputStream(String name): 创建文件输出流,指定的名称为写出文件。
- public FileOutputStream(File file, boolean append): 创建文件输出流,指明是否在现有文件末尾追加内容。
15.5 读写数据的过程
-
步骤 1:创建 File 类的对象,作为读取或写出数据的端点。
-
步骤 2:创建相关的流的对象。
-
步骤 3:读取、写出数据的过程。
-
步骤 4:关闭流资源。
-
读取数据的代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31import java.io.*;
public class ReadFileExample
{
public static void main(String[] args)
{
try {
// 步骤1:创建File类的对象
File file = new File("example.txt");
// 步骤2:创建相关的流的对象
FileReader reader = new FileReader(file);
BufferedReader bufferedReader = new BufferedReader(reader);
// 步骤3:读取数据的过程
String line;
while ((line = bufferedReader.readLine()) != null)
{
System.out.println(line);
}
// 步骤4:关闭流资源
bufferedReader.close();
reader.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
} -
写出数据的代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27import java.io.*;
public class WriteFileExample
{
public static void main(String[] args)
{
try {
// 步骤1:创建File类的对象
File file = new File("example.txt");
// 步骤2:创建相关的流的对象
FileWriter writer = new FileWriter(file);
BufferedWriter bufferedWriter = new BufferedWriter(writer);
// 步骤3:写出数据的过程
bufferedWriter.write("Hello, world!");
// 步骤4:关闭流资源
bufferedWriter.close();
writer.close();
}
catch (IOException e)
{
e.printStackTrace();
}
}
}
15.6 处理流之一:缓冲流
为了提高数据读写的速度,Java API 提供了带缓冲功能的流类:缓冲流。
缓冲流要“套接”在相应的节点流之上,根据数据操作单位可以把缓冲流分为:
- 字节缓冲流:BufferedInputStream,BufferedOutputStream
- 字符缓冲流:BufferedReader,BufferedWriter
缓冲流的基本原理:在创建流对象时,内部会创建一个缓冲区数组(缺省使用 8192
个字节(8Kb)的缓冲区),通过缓冲区读写,减少系统 IO 次数,从而提高读写的效
率。
构造器:
- public BufferedInputStream(InputStream in) :创建一个 新的字节型的缓冲输入流。
- public BufferedOutputStream(OutputStream out): 创建一个新的字节型的缓冲输出流。
字符缓冲流特有方法:
- BufferedReader:public String readLine(): 读一行文字。
- BufferedWriter:public void newLine(): 写一行行分隔符,由系统属性定义符号。
15.7 处理流之二:转换流
15.7.1 InputStreamReader 与 OutputStreamWriter
-
InputStreamReader
-
转换流 java.io.InputStreamReader,是 Reader 的子类,是从字节流到字符流的桥梁。它读取字节,并使用指定的字符集将其解码为字符。它的字符集可以由名称指定,也可以接受平台的默认字符集。
-
构造器:
- InputStreamReader(InputStream in): 创建一个使用默认字符集的字符流。
- InputStreamReader(InputStream in, String charsetName): 创建一个指定字符集的字符流。
-
-
OutputStreamWriter
-
转换流 java.io.OutputStreamWriter ,是 Writer 的子类,是从字符流到字节流的桥梁。使用指定的字符集将字符编码为字节。它的字符集可以由名称指定,也可以接受平台的默认字符集。
-
构造器:
- OutputStreamWriter(OutputStream in): 创建一个使用默认字符集的字符流。
- OutputStreamWriter(OutputStream in,String charsetName): 创建一个指定字符集的字符流。
-
15.7.2 字符编码和字符集
-
编码与解码 :
计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。 -
字符编码(Character Encoding) : 就是一套自然语言的字符与二进制数之间的对应规则。
-
编码表:生活中文字和计算机中二进制的对应规则。
-
乱码的情况:按照 A 规则存储,同样按照 A 规则解析,那么就能显示正确的文本符号。反之,按照 A 规则存储,再按照 B 规则解析,就会导致乱码现象。
-
编码:字符——>字节
-
解码:字节——>字符
-
字符集 Charset:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
-
计算机要准确的存储和识别各种字符集符号,需要进行字符编码,一套字符集必然至少有一套字符编码。常见字符集有 ASCII 字符集、GBK 字符集、Unicode 字符集等。
15.8 处理流之三:对象流
15.8.1 对象流:ObjectOutputStream、ObjectInputStream
- ObjectOutputStream:将 Java 基本数据类型和对象写入字节输出流中。通过在流中使用文件可以实现 Java 各种基本数据类型的数据以及对象的持久存储。
- ObjectInputStream:ObjectInputStream 对以前使用 ObjectOutputStream 写出的基本数据类型的数据和对象进行读入操作,保存在内存中。
- 说明:对象流的强大之处就是可以把 Java 中的对象写入到数据源中,也能把对象从数据源中还原回来。
15.8.2 对象流 API
-
ObjectOutputStream 中的构造器:
- public ObjectOutputStream(OutputStream out): 创建一个指定的 ObjectOutputStream。
-
ObjectOutputStream 中的方法:
- public void writeBoolean(boolean val):写出一个 boolean 值。
- public void writeByte(int val):写出一个 8 位字节。
- public void writeShort(int val):写出一个 16 位的 short 值。
- public void writeChar(int val):写出一个 16 位的 char 值。
- public void writeInt(int val):写出一个 32 位的 int 值。
- public void writeLong(long val):写出一个 64 位的 long 值。
- public void writeFloat(float val):写出一个 32 位的 float 值。
- public void writeDouble(double val):写出一个 64 位的 double 值
- public void writeUTF(String str):将表示长度信息的两个字节写入输出流,后跟字符串 s 中每个字符的 UTF-8 修改版表示形式。根据字符的值,将字符串 s 中每个字符转换成一个字节、两个字节或三个字节的字节组。注意,将 String 作为基本数据写入流中与将它作为 Object 写入流中明显不同。 如果 s 为 null,则抛出 NullPointerException。
- public void writeObject(Object obj):写出一个 obj 对象。
- public void close() :关闭此输出流并释放与此流相关联的任何系统资源。
-
ObjectInputStream 中的构造器:
- public ObjectInputStream(InputStream in): 创建一个指定的 ObjectInputStream。
-
ObjectInputStream 中的方法:
- public boolean readBoolean():读取一个 boolean 值。
- public byte readByte():读取一个 8 位的字节。
- public short readShort():读取一个 16 位的 short 值。
- public char readChar():读取一个 16 位的 char 值。
- public int readInt():读取一个 32 位的 int 值。
- public long readLong():读取一个 64 位的 long 值。
- public float readFloat():读取一个 32 位的 float 值。
- public double readDouble():读取一个 64 位的 double 值。
- public String readUTF():读取 UTF-8 修改版格式的 String。
- public void readObject(Object obj):读入一个 obj 对象。
- public void close() :关闭此输入流并释放与此流相关联的任何系统资源。
15.8.3 认识对象序列化机制
-
何为对象序列化机制?
- 对象序列化机制允许把内存中的 Java 对象转换成平台无关的二进制流,从而允许把这种二进制流持久地保存在磁盘上,或通过网络将这种二进制流传输到另一个网络节点。当其它程序获取了这种二进制流,就可以恢复成原来的 Java 对象。
-
序列化过程:用一个字节序列可以表示一个对象,该字节序列包含该对象的类型和对象中存储的属性等信息。字节序列写出到文件之后,相当于文件中持久保存了一个对象的信息。
-
反序列化过程:该字节序列还可以从文件中读取回来,重构对象,对它进行反序列化。对象的数据、对象的类型和对象中存储的数据信息,都可以用来在内存中创建对象。
-
序列化机制的重要性
- 序列化是 RMI(Remote Method Invoke、远程方法调用)过程的参数和返回值都必须实现的机制,而 RMI 是 JavaEE 的基础。因此序列化机制是 JavaEE 平台的基础。
- 序列化的好处,在于可将任何实现了 Serializable 接口的对象转化为字节数据,使其在保存和传输时可被还原。
-
实现原理
- 序列化:用 ObjectOutputStream 类保存基本类型数据或对象的机制。方法为:
- public final void writeObject (Object obj) : 将指定的对象写出。
- 反序列化:用 ObjectInputStream 类读取基本类型数据或对象的机制。方法为:
- public final Object readObject () : 读取一个对象。
- 序列化:用 ObjectOutputStream 类保存基本类型数据或对象的机制。方法为:
-
如何实现序列化机制
-
如果需要让某个对象支持序列化机制,则必须让对象所属的类及其属性是可序列化的,为了让某个类是可序列化的,该类必须实现 java.io.Serializable 接口。Serializable 是一个标记接口,不实现此接口的类将不会使任何状态序
列化或反序列化,会抛出 NotSerializableException。 -
如果对象的某个属性也是引用数据类型,那么如果该属性也要序列化的话,也要实现 Serializable 接口。
-
该类的所有属性必须是可序列化的。如果有一个属性不需要可序列化的,则该属性必须注明是瞬态的,使用 transient 关键字修饰。
-
静态(static)变量的值不会序列化。因为静态变量的值不属于某个对象。
-
代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51import java.io.*;
public class Person implements Serializable
{
private static final long serialVersionUID = 1L;
private String name;
private int age;
public Person(String name, int age)
{
this.name = name;
this.age = age;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public static void main(String[] args)
{
Person person = new Person("Tom", 18);
try {
// 将对象序列化为字节流
FileOutputStream fos = new FileOutputStream("person.ser");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(person);
oos.close();
fos.close();
// 将字节流反序列化为对象
FileInputStream fis = new FileInputStream("person.ser");
ObjectInputStream ois = new ObjectInputStream(fis);
Person p = (Person) ois.readObject();
ois.close();
fis.close();
System.out.println(p.getName() + " " + p.getAge());
}
catch (IOException | ClassNotFoundException e)
{
e.printStackTrace();
}
}
}
-
15.8.4 反序列化失败问题
-
问题 1:
- 对于 JVM 可以反序列化对象,它必须是能够找到 class 文件的类。如果找不到该类的 class 文件,则抛出一个 ClassNotFoundException 异常。
-
问题 2:
-
当 JVM 反序列化对象时,能找到 class 文件,但是 class 文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个 InvalidClassException 异常。发生这个异常的原因如下:
- 该类的序列版本号与从流中读取的类描述符的版本号不匹配。
- 该类包含未知数据类型。
-
解决办法:
-
Serializable 接口给需要序列化的类,提供了一个序列版本号:serialVersionUID 。凡是实现 Serializable 接口的类都应该有一个表示序列化
版本标识符的静态变量:1
static final long serialVersionUID = 234242343243L; // 值随意指定即可
-
serialVersionUID 用来表明类的不同版本间的兼容性。简单来说,Java 的序列化机制是通过在运行时判断类的 serialVersionUID 来验证版本一致性的。在进行反序列化时,JVM 会把传来的字节流中的 serialVersionUID 与本地相应实体类的 serialVersionUID 进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常(InvalidCastException)。
-
如果类没有显示定义这个静态常量,它的值是 Java 运行时环境根据类的内部细节自动生成的。若类的实例变量做了修改,serialVersionUID 可能发生变化。因此,建议显式声明。
-
如果声明了 serialVersionUID,即使在序列化完成之后修改了类导致类重新编译,则原来的数据也能正常反序列化,只是新增的字段值是默认值而已。
-
-
15.9 其它流
15.9.1 数据流:DataInputStream 、DataOutputStream
-
如果需要将内存中定义的变量(包括基本数据类型或引用数据类型)保存在文件中,那怎么办呢?
-
Java 提供了数据流和对象流来处理这些类型的数据:
- 数据流:DataOutputStream、DataInputStream
- DataOutputStream:允许应用程序将基本数据类型、String 类型的变量写入输出流中。
- DataInputStream:允许应用程序以与机器无关的方式从底层输入流中读取基本数据类型、String 类型的变量。
- 数据流:DataOutputStream、DataInputStream
-
数据流的弊端:只支持 Java 基本数据类型和字符串的读写,而不支持其它 Java 对象的类型。而 ObjectOutputStream 和 ObjectInputStream 既支持 Java 基本数据类型的数据读写,又支持 Java 对象的读写。
15.9.2 标准的输入流、标准的输出流:System.in 、System.out
- System.in 和 System.out 分别代表了系统标准的输入和输出设备。
- 默认输入设备是:键盘,输出设备是:显示器。
- System.in 的类型是 InputStream。
- System.out 的类型是 PrintStream,其是 OutputStream 的子类 FilterOutputStream 的子类。
- 重定向:通过 System 类的 setIn,setOut 方法对默认设备进行改变。
- public static void setIn(InputStream in)
- public static void setOut(PrintStream out)
15.9.3 打印流:PrintStream、PrintWriter
- 实现将基本数据类型的数据格式转化为字符串输出。
- 打印流:PrintStream 和 PrintWriter。
- 提供了一系列重载的 print()和 println()方法,用于多种数据类型的输出。
- PrintStream 和 PrintWriter 的输出不会抛出 IOException 异常。
- PrintStream 和 PrintWriter 有自动 flush 功能。
- PrintStream 打印的所有字符都使用平台的默认字符编码转换为字节。在需要写入字符而不是写入字节的情况下,应该使用 PrintWriter 类。
- System.out 返回的是 PrintStream 的实例
- 构造器:
- PrintStream(File file) :创建具有指定文件且不带自动行刷新的新打印流。
- PrintStream(File file, String csn):创建具有指定文件名称和字符集且不带自动行刷新的新打印流。
- PrintStream(OutputStream out) :创建新的打印流。
- PrintStream(OutputStream out, boolean autoFlush):创建新的打印流。autoFlush 如果为 true,则每当写入 byte 数组、调用其中一个 println 方法或写入换行符或字节 (‘\n’) 时都会刷新输出缓冲区。
- PrintStream(OutputStream out, boolean autoFlush, String encoding) :创建新的打印流。
- PrintStream(String fileName):创建具有指定文件名称且不带自动行刷新的新打印流。
- PrintStream(String fileName, String csn) :创建具有指定文件名称和字符集且不带自动行刷新的新打印流。
15.9.4 Scanner 类
-
构造方法:
- Scanner(File source) :构造一个新的 Scanner,它生成的值是从指定文件扫描的。
- Scanner(File source, String charsetName) :构造一个新的 Scanner,它生成的值是从指定文件扫描的。
- Scanner(InputStream source) :构造一个新的 Scanner,它生成的值是从指定的输入流扫描的。
- Scanner(InputStream source, String charsetName) :构造一个新的 Scanner,它生成的值是从指定的输入流扫描的。
-
常用方法:
- boolean hasNextXxx(): 如果通过使用 nextXxx()方法,此扫描器输入信息中的下一个标记可以解释为默认基数中的一个 Xxx 值,则返回 true。
- Xxx nextXxx(): 将输入信息的下一个标记扫描为一个 Xxx
15.10 企业真题
-
谈谈 Java IO 里面的常用类,字节流,字符流?
答:
Java IO 里面的常用类包括:- InputStream/OutputStream:字节流的基本类,用于读写字节数据。
- Reader/Writer:字符流的基本类,用于读写字符数据。
- FileInputStream/FileOutputStream:用于读写文件的字节流类。
- FileReader/FileWriter:用于读写文件的字符流类。
- ByteArrayInputStream/ByteArrayOutputStream:用于读写字节数组的流类。
- CharArrayReader/CharArrayWriter:用于读写字符数组的流类。
- BufferedInputStream/BufferedOutputStream:用于带缓冲的读写字节数据的流类。
- BufferedReader/BufferedWriter:用于带缓冲的读写字符数据的流类。
- DataInputStream/DataOutputStream:用于读写基本数据类型的字节流类。
- InputStreamReader/OutputStreamWriter:用于将字节流转换成字符流的类。
- ObjectInputStream/ObjectOutputStream:用于读写 Java 对象的字节流类。
- PipedInputStream/PipedOutputStream:用于在线程之间传递数据的流类。
- PrintStream/PrintWriter:用于将数据打印到输出流的类。
总的来说,Java IO 提供了丰富的流类来满足各种读写需求,其中字节流和字符流是最基本的两种类型,字节流适用于读写二进制数据,而字符流适用于读写文本数据。在实际应用中需要根据具体的需求选择合适的流类。
-
Java 中有几种类型的流?JDK 为每种类型的流提供一些抽象类以供继承,请说出他们分别是哪些类?
答:
Java 中有四种类型的流:字节流、字符流、字节缓冲流和字符缓冲流。JDK 为每种类型的流提供一些抽象类以供继承,如下所示:
① 字节流:
InputStream:所有字节输入流的父类。
OutputStream:所有字节输出流的父类。
② 字符流:
Reader:所有字符输入流的父类。
Writer:所有字符输出流的父类。
③ 字节缓冲流:
BufferedInputStream:字节缓冲输入流。
BufferedOutputStream:字节缓冲输出流。
④ 字符缓冲流:
BufferedReader:字符缓冲输入流。
BufferedWriter:字符缓冲输出流。 -
流一般需不需要关闭?如果关闭的话用什么方法?处理流是怎么关闭的?
答:
在 Java 中,流一般需要关闭以释放资源和避免内存泄漏。关闭流可以使用 close()方法进行处理。例如,对于文件输入流,可以使用以下代码关闭流:1
2
3FileInputStream fis = new FileInputStream("example.txt");
//处理流
fis.close();对于网络连接,可以使用以下代码关闭流:
1
2
3
4
5Socket socket = new Socket("127.0.0.1", 8080);
OutputStream os = socket.getOutputStream();
//处理流
os.close();
socket.close();在 Java 7 及以上版本中,可以使用 try-with-resources 语句来自动关闭流,示例如下:
1
2
3
4try (FileInputStream fis = new FileInputStream("example.txt"))
{
//处理流
} -
OutputStream 里面的 write()是什么意思?
答:
OutputStream 中的 write()是将数据写入输出流的方法。它的作用是将指定的字节数组写入输出流中。在 Java 中,OutputStream 是一个抽象类,它提供了几个不同的 write()方法的实现,可以将字节数组、单个字节、字符串、整数等类型的数据写入输出流中。当数据被写入输出流后,它们就可以被传输到其他地方,例如网络连接、文件、内存等。 -
BufferedReader 属于哪种流?他主要是用来做什么的?
答:
BufferedReader 属于字符流,主要用于读取文本数据。它可以将字符从输入流中读取到缓冲区中,从而提高读取效率,同时也提供了一些方便的读取方法。常见的应用场景包括读取文本文件、读取网络数据等。 -
什么是缓冲区?有什么作用?
答:
缓冲区是一种临时存储数据的区域,用于提高数据的读写效率。在 Java 中,缓冲区主要用于输入输出流的操作中,如 BufferedReader 和 BufferedWriter 等。缓冲区的作用是将数据暂时保存在内存中,等到缓冲区满了或者需要进行数据读取时,再一次性将数据写入到文件或者从文件中读取到缓冲区中。这样可以减少与硬盘的交互次数,提高数据读写效率,同时也减轻了硬盘的负担,延长了硬盘的使用寿命。
另外,缓冲区还可以提供一些额外的功能,如数据的压缩、加密、解密等操作,使得数据的处理更加灵活和高效。
-
字节流和字符流是什么?怎么转换?
答:
字节流和字符流是 Java 中用于处理输入输出的两种不同的流类型。字节流以字节为单位进行读写,适用于处理二进制文件和网络数据流等;字符流以字符为单位进行读写,适用于处理文本文件和文本数据流等。在 Java 中,字节流主要由 InputStream 和 OutputStream 两个抽象类及其实现类构成,而字符流主要由 Reader 和 Writer 两个抽象类及其实现类构成。常用的字节流实现类有 FileInputStream、FileOutputStream、BufferedInputStream 等,常用的字符流实现类有 FileReader、FileWriter、BufferedReader 等。
转换字节流和字符流可以使用 InputStreamReader 和 OutputStreamWriter 类。InputStreamReader 将字节流转换为字符流,OutputStreamWriter 将字符流转换为字节流。例如,可以使用以下代码将字节流转换为字符流:
1
2InputStream inputStream = new FileInputStream("file.txt");
Reader reader = new InputStreamReader(inputStream, "UTF-8");其中,"file.txt"是要读取的文件名,"UTF-8"是字符集编码。可以使用以下代码将字符流转换为字节流:
1
2OutputStream outputStream = new FileOutputStream("file.txt");
Writer writer = new OutputStreamWriter(outputStream, "UTF-8"); -
什么是 Java 序列化,如何实现?
答:
Java 序列化是将 Java 对象转换为字节序列的过程,以便在网络上传输或将其保存到磁盘上。序列化的过程中,Java 会将对象的状态保存为一组字节,并将其写入到输出流中,以便在需要时可以重新构造出原始对象。要实现 Java 序列化,需要以下步骤:
① 让 Java 类实现 Serializable 接口。这个接口是一个标记接口,没有任何方法,只是用来表示该类可以被序列化。
② 创建一个 ObjectOutputStream 实例,并将其连接到一个输出流中。这个输出流可以是文件输出流、网络输出流等。
③ 调用 ObjectOutputStream 的 writeObject()方法,将需要序列化的 Java 对象写入输出流中。
④ 关闭输出流。反序列化则是将字节序列转换为 Java 对象的过程。要实现反序列化,需要以下步骤:
① 创建一个 ObjectInputStream 实例,并将其连接到一个输入流中。这个输入流可以是文件输入流、网络输入流等。
② 调用 ObjectInputStream 的 readObject()方法,从输入流中读取字节序列,并将其转换为 Java 对象。
③ 关闭输入流。需要注意的是,在序列化和反序列化过程中,Java 对象的类名、字段名等信息都会被写入到字节序列中,因此在反序列化时,需要确保读取的字节序列所对应的 Java 类仍然存在,否则会抛出 ClassNotFoundException 异常。
-
Java 有些类中为什么需要实现 Serializable 接口?
答:
Java 中的 Serializable 接口是一个标记接口,用于指示一个类的对象可以被序列化。序列化是指将对象转换为字节流的过程,以便在网络上传输或保存到文件中。实现 Serializable 接口的类可以被 Java 中的序列化机制所处理,从而可以实现对象的持久化和远程调用等功能。因此,如果一个类需要被序列化,就需要实现 Serializable 接口。
第 16 章 网络编程
16.1 网络编程概述
计算机网络:把分布在不同地理区域的计算机与专门的外部设备用通信线路互连成一个规模大、功能强的网络系统,从而使众多的计算机可以方便地互相传递信息、共享硬件、软件、数据信息等资源。
网络编程的目的:直接或间接地通过网络协议与其它计算机实现数据交换,进行通讯。
需要解决的三个问题:
- 问题 1:如何准确地定位网络上一台或多台主机?
- 问题 2:如何定位主机上的特定的应用?
- 问题 3:找到主机后,如何可靠、高效地进行数据传输?
16.2. IP 地址和域名
16.2.1 IP 地址
-
IP 地址:指互联网协议地址(Internet Protocol Address),俗称 IP。IP 地址
用来给网络中的一台计算机设备做唯一的编号。 -
IP 分类:
-
角度一:IPv4、IPv6。
- IPv4:是一个 32 位的二进制数,通常被分为 4 个字节,表示成 a.b.c.d 的形式,以点分十进制表示,例如 192.168.65.100 。其中 a、b、c、d 都是 0~255 之间的十进制整数。
- IPv6:由于互联网的蓬勃发展,IP 地址的需求量愈来愈大,但是网络地址资源有限,使得 IP 的分配越发紧张。为了扩大地址空间,拟通过 IPv6 重新定义地址空间,采用 128 位地址长度,共 16 个字节,写成 8 个无符号整数,每个整数用四个十六进制位表示,数之间用冒号(:)分开。比如:ABCD:EF01:2345:6789:ABCD:EF01:2345:6789,按保守方法估算 IPv6 实际可分配的地址,整个地球的每平方米面积上仍可分配 1000 多个地
址,这样就解决了网络地址资源数量不够的问题。
-
角度二:公网地址、私网地址(或局域网)。
- 192.168.开头的就是私有地址,范围即为 192.168.0.0–192.168.255.255,专门为组织机构内部使用。
-
-
使用 InetAddress 类表示 IP 地址。
- 实例化:getByName(String host) 、getLocalHost()。
- 常用方法:getHostName() 、getHostAddress()。
16.2.2 域名
-
Internet 上的主机有两种方式表示地址:
- 域名(hostName):https://www.baidu.com
- IP 地址(hostAddress):202.108.22.5
-
域名解析:因为 IP 地址数字不便于记忆,因此出现了域名。域名容易记忆,当在连接网络时输入一个主机的域名后,域名服务器(DNS,Domain Name System,域名系统)负责将域名转化成 IP 地址,这样才能和主机建立连接。
16.3 端口号
如果说 IP 地址可以唯一标识网络中的设备,那么端口号就可以唯一标识设备中的进程。
不同的进程分配不同的端口号。
端口号:用两个字节表示的整数,它的取值范围是 0~65535。
- 公认端口:0~1023。被预先定义的服务通信占用,如:HTTP(80),FTP(21),Telnet(23)。
- 注册端口:1024~49151。分配给用户进程或应用程序。如:Tomcat(8080),MySQL(3306),Oracle(1521)。
- 动态/ 私有端口:49152~65535。
16.4 网络通信协议
网络通信协议有两套参考模型。
- OSI 参考模型:模型过于理想化,未能在因特网上进行广泛推广。
- TCP/IP 参考模型(或 TCP/IP 协议):事实上的国际标准。
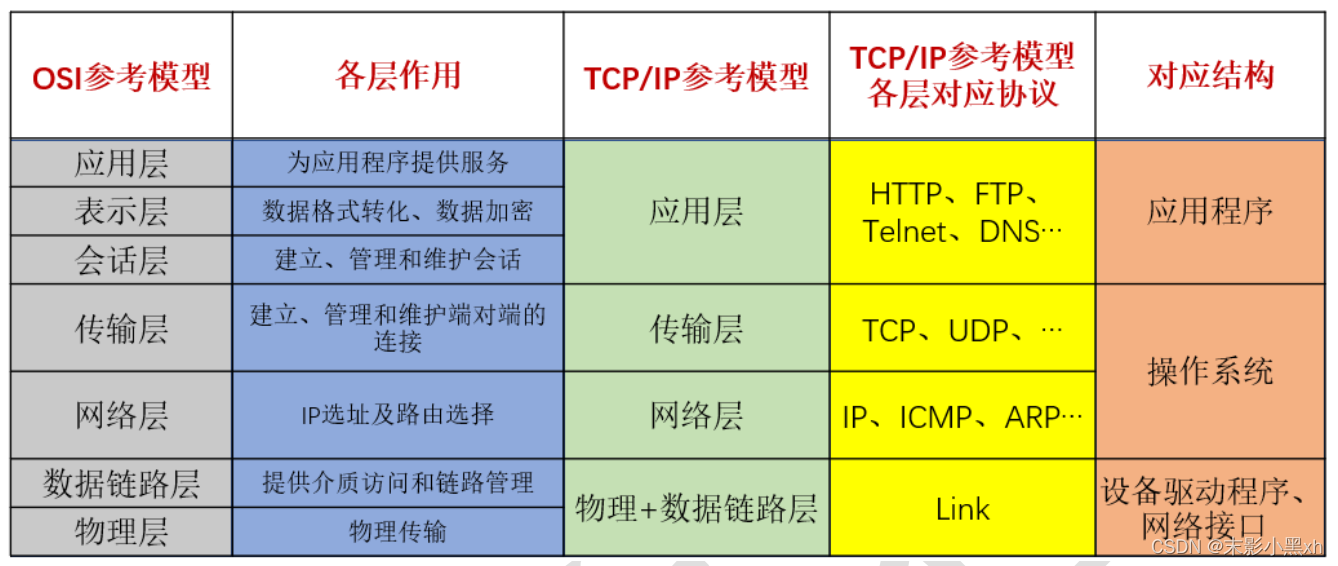
16.4.1 TCP、UDP
在传输层中涉及到两个协议:TCP、UDP。二者的对比。
- TCP:可靠的连接(发送数据前,需要三次握手、四次挥手),进行大数据量的传输,效率低。
- UDP:不可靠的连接(发送前,不需要确认对方是否在)、使用数据报传输(限制在 64kb 以内)、效率高。
16.4.2 TCP 的三次握手
TCP 协议中,在发送数据的准备阶段,客户端与服务器之间的三次交互,以保证连接的可靠。
- 第一次握手,客户端向服务器端发起 TCP 连接的请求。
- 第二次握手,服务器端发送针对客户端 TCP 连接请求的确认。
- 第三次握手,客户端发送确认的确认。
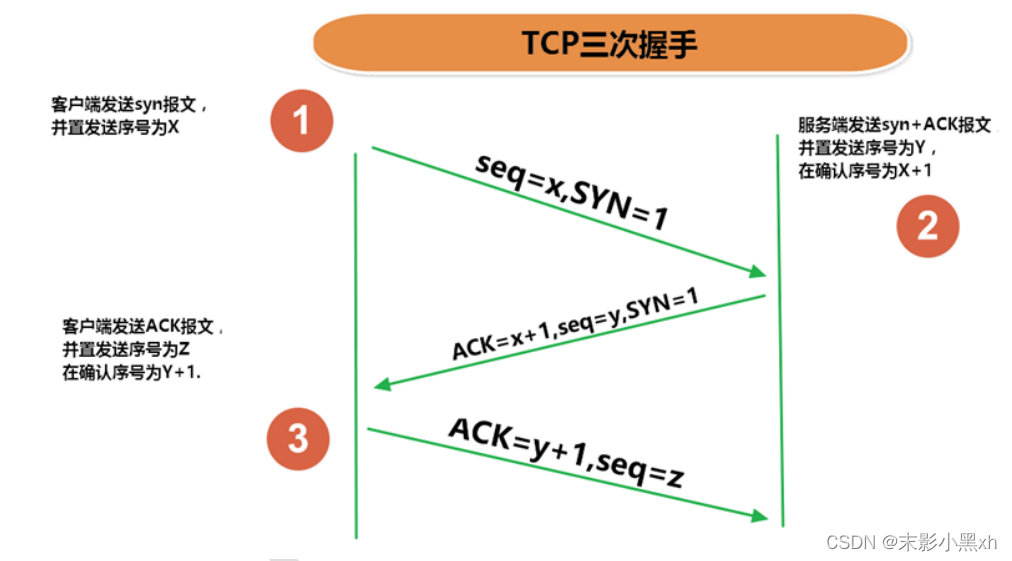
16.4.2 TCP 的四次挥手
TCP 协议中,在发送数据结束后,释放连接时需要经过四次挥手。
- 第一次挥手:客户端向服务器端提出结束连接,让服务器做最后的准备工作。此时,客户端处于半关闭状态,即表示不再向服务器发送数据了,但是还可以接受数据。
- 第二次挥手:服务器接收到客户端释放连接的请求后,会将最后的数据发给客户端。并告知上层的应用进程不再接收数据。
- 第三次挥手:服务器发送完数据后,会给客户端发送一个释放连接的报文。那么客户端接收后就知道可以正式释放连接了。
- 第四次挥手:客户端接收到服务器最后的释放连接报文后,要回复一个彻底断开的报文。这样服务器收到后才会彻底释放连接。这里客户端,发送完最后的报文后,会等待 2MSL,因为有可能服务器没有收到最后的报文,那么服务器迟迟没收到,就会再次给客户端发送释放连接的报文,此时客户端在等待时间范围内接收到,会重新发送最后的报文,并重新计时。如果等待 2MSL 后,没有收到,那么彻底断开。
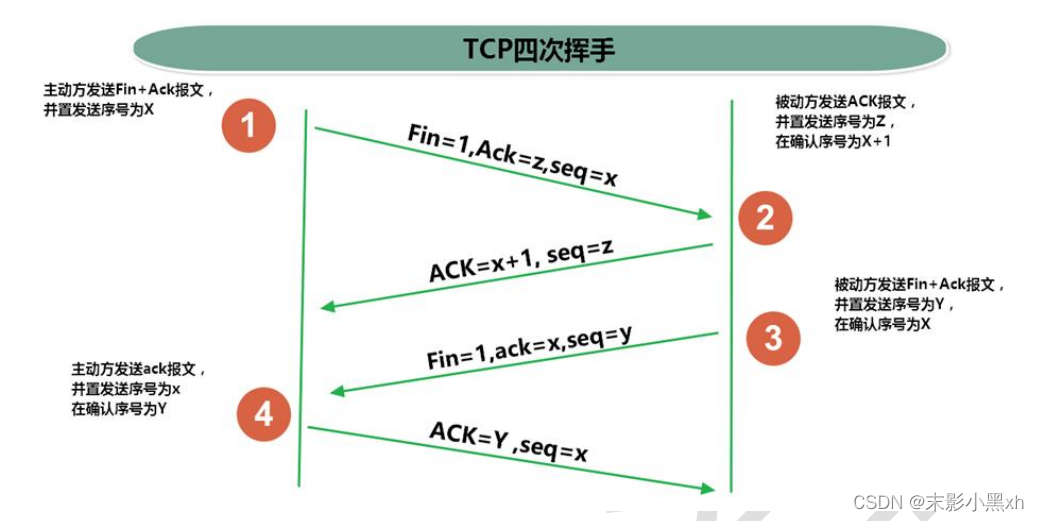
16.5 网络编程 API
16.5.1 InetAddress 类
-
InetAddress 类主要表示 IP 地址,两个子类:Inet4Address、Inet6Address。
-
InetAddress 类没有提供公共的构造器,而是提供 了 如下几个 静态方法来获取 InetAddress 实例。
- public static InetAddress getLocalHost()
- public static InetAddress getByName(String host)
- public static InetAddress getByAddress(byte[] addr)
-
InetAddress 提供了如下几个常用的方法。
- public String getHostAddress() :返回 IP 地址字符串(以文本表现形式)。
- public String getHostName() :获取此 IP 地址的主机名。
- public boolean isReachable(int timeout):测试是否可以达到该地址。
16.5.2 Socket 类
网络上具有唯一标识的 IP 地址和端口号组合在一起构成唯一能识别的标识符套接字 (Socket)。
利用套接字(Socket)开发网络应用程序早已被广泛的采用,以至于成为事实上的标准。网络通信其实就是 Socket 间的通信。
通信的两端都要有 Socket,是两台机器间通信的端点。
Socket 允许程序把网络连接当成一个流,数据在两个 Socket 间通过 IO 传输。
一般主动发起通信的应用程序属客户端,等待通信请求的为服务端。
Socket 分类:
- 流套接字(stream socket):使用 TCP 提供可依赖的字节流服务。
- ServerSocket:此类实现 TCP 服务器套接字。服务器套接字等待请求通过网络传入。
- Socket:此类实现客户端套接字(也可以就叫“套接字”)。套接字是两台机器间通信的端点。
- 数据报套接字(datagram socket):使用 UDP 提供“尽力而为”的数据报服务。
- DatagramSocket:此类表示用来发送和接收 UDP 数据报包的套接字。
16.5.3 DatagramSocket 类
- DatagramSocket 类的常用方法:
- public DatagramSocket(int port)创建数据报套接字并将其绑定到本地主机上的指定端口。套接字将被绑定到通配符地址,IP 地址由内核来选择。
- public DatagramSocket(int port,InetAddress laddr)创建数据报套接字,将其绑定到指定的本地地址。本地端口必须在 0 到 65535 之间(包括两者)。如果 IP 地址为 0.0.0.0,套接字将被绑定到通配符地址,IP 地址由内核选择。
- public void close()关闭此数据报套接字。
- public void send(DatagramPacket p)从此套接字发送数据报包。DatagramPacket 包含的信息指示:将要发送的数据、其长度、远程主机的 IP 地址和远程主机的端口号。
- public void receive(DatagramPacket p)从此套接字接收数据报包。当此方法返回时, DatagramPacket 的缓冲区填充了接收的数据。数据报包也包含发送方的 IP 地址和发送方机器上的端口号。 此方法在接收到数据报前一直阻塞。数据报包对象的 length 字段包含所接收信息的长度。如果信息比包的长度长,该信息将被截短。
- public InetAddress getLocalAddress()获取套接字绑定的本地地址。
- public int getLocalPort()返回此套接字绑定的本地主机上的端口号。
- public InetAddress getInetAddress()返回此套接字连接的地址。如果套接字未连接,则返回 null。
- public int getPort()返回此套接字的端口。如果套接字未连接,则返回 -1。
16.5.4 DatagramPacket 类
- DatagramPacket 类的常用方法:
- public DatagramPacket(byte[] buf,int length)构造 DatagramPacket,用来接收长度为 length 的数据包。 length 参数必须小于等于 buf.length。
- public DatagramPacket(byte[] buf,int length,InetAddress address,int port)构造数据报
包,用来将长度为 length 的包发送到指定主机上的指定端口号。length 参数必须小于等于 buf.length。 - public InetAddress getAddress()返回某台机器的 IP 地址,此数据报将要发往该机器或者是从该机器接收到的。
- public int getPort()返回某台远程主机的端口号,此数据报将要发往该主机或者是从该主机接收到的。
- public byte[] getData()返回数据缓冲区。接收到的或将要发送的数据从缓冲区中的偏移量 offset 处开始,持续 length 长度。
- public int getLength()返回将要发送或接收到的数据的长度。
16.6 TCP 网络编程
16.6.1 通信模型
Java 语言的基于套接字 TCP 编程分为服务端编程和客户端编程,其通信模型如图所示:
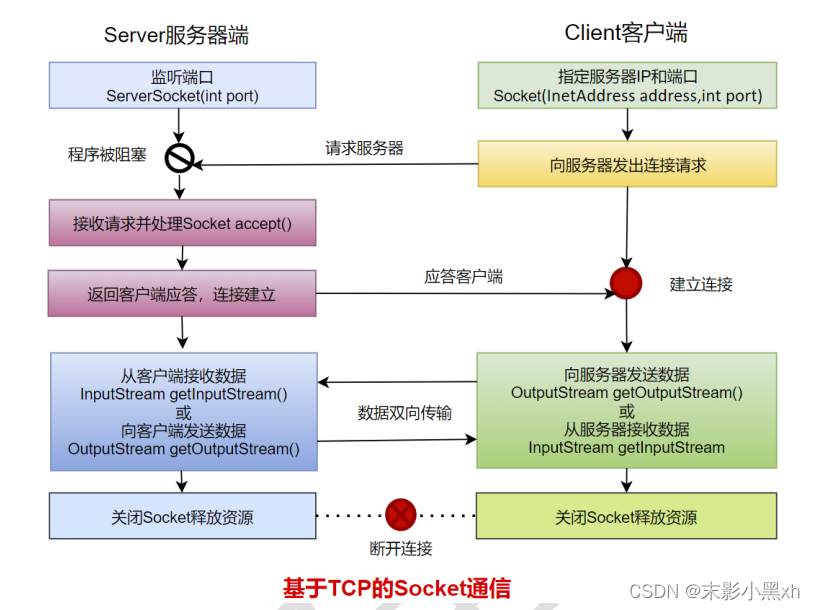
16.6.2 开发步骤
-
客户端程序包含以下四个基本的步骤 :
- 创建 Socket :根据指定服务端的 IP 地址或端口号构造 Socket 类对象。若服务器端响应,则建立客户端到服务器的通信线路。若连接失败,会出现异常。
- 打开连接到 Socket 的输入/ 出流: 使用 getInputStream()方法获得输入流,使用
getOutputStream()方法获得输出流,进行数据传输。 - 按照一定的协议对 Socket 进行读/ 写操作:通过输入流读取服务器放入线路的信息(但不能读取自己放入线路的信息),通过输出流将信息写入线路。
- 关闭 Socket :断开客户端到服务器的连接,释放线路。
-
服务器端程序包含以下四个基本的 步骤:
- 调用 ServerSocket(int port) :创建一个服务器端套接字,并绑定到指定端口上。用于监听客户端的请求。
- 调用 accept() :监听连接请求,如果客户端请求连接,则接受连接,返回通信套接字对象。
- 调用该 Socket 类对象的 getOutputStream() 和 getInputStream () :获取输出流和输入流,开始网络数据的发送和接收。
- 关闭 Socket 对象:客户端访问结束,关闭通信套接字。
16.7 UDP 网络编程
16.7.1 通信模型
UDP 协议是一种面向非连接的协议,面向非连接指的是在正式通信前不必与对方先建立连接,不管对方状态就直接发送,至于对方是否可以接收到这些数据内容,UDP 协议无法控制,因此说,UDP 协议是一种不可靠的协议。无连接的好处就是快,省内存空间和流量,因为维护连接需要创建大量的数据结构。
UDP 会尽最大努力交付数据,但不保证可靠交付,没有 TCP 的确认机制、重传机制,如果因为网络原因没有传送到对端,UDP 也不会给应用层返回错误信息。
UDP 协议是面向数据报文的信息传送服务。UDP 在发送端没有缓冲区,对于应用层交付下来的报文在添加了首部之后就直接交付于 ip 层,不会进行合并,也不会进行拆分,而是一次交付一个完整的报文。比如我们要发送 100 个字节的报文,我们调用一次 send()方法就会发送 100 字节,接收方也需要用 receive() 方法一次性接收 100 字节,不能使用循环每次获取 10 个字节,获取十次这样的做法。
UDP 协议没有拥塞控制,所以当网络出现的拥塞不会导致主机发送数据的速率降低。虽然 UDP 的接收端有缓冲区,但是这个缓冲区只负责接收,并不会保证 UDP 报文的到达顺序是否和发送的顺序一致。因为网络传输的时候,由于网络拥塞的存在是很大的可能导致先发的报文比后发的报文晚到达。如果此时缓冲区满了,后面到达的报文将直接被丢弃。这个对实时应用来说很重要,比如:视频通话、直播等应用。因此 UDP 适用于一次只传送少量数据、对可靠性要求不高的应用环境,数据报大小限制在 64K 以下。
类 DatagramSocket 和 DatagramPacket 实现了基于 UDP 协议网络程序。UDP 数据报通过数据报套接字 DatagramSocket 发送和接收,系统不保证 UDP 数据报一定能够安全送到目的地,也不能确定什么时候可以抵达。DatagramPacket 对象封装了 UDP 数据报,在数据报中包含了发送端的 IP 地址和端口号以及接收端的 IP 地址和端口号。
16.7.2 开发步骤
-
发送端程序包含以下四个基本的步骤:
- 创建 DatagramSocket :默认使用系统随机分配端口号。
- 创建 DatagramPacket:将要发送的数据用字节数组表示,并指定要发送的数据长
度,接收方的 IP 地址和端口号。 - 调用该 DatagramSocket 类对象的 send 方法 :发送数据报 DatagramPacket 对象。
- 关闭 DatagramSocket 对象:发送端程序结束,关闭通信套接字。
-
接收端程序包含以下四个基本的步骤 :
- 创建 DatagramSocket :指定监听的端口号。 -创建 DatagramPacket:指定接收数据用的字节数组,起到临时数据缓冲区的效果,并指定最大可以接收的数据长度。
- 调用 该 DatagramSocket 类对象的 receive 方法 :接收数据报 DatagramPacket 对
象。 - 关闭 DatagramSocket :接收端程序结束,关闭通信套接字。
16.8 URL 编程
Java 后台:将写好的 Java 程序部署在 Tomcat 服务器。启动 Tomcat 服务器。
前台:使用浏览器进行访问。需要使用 url。(HTML+CSS+JavaScript)
URL 的作用:定位互联网上某一资源的地址。
URL 的格式:
1 | http://192.168.21.107:8080/examples/abcd.jpg?name=Tom |
使用 URL 实现数据的下载。
16.9 企业真题
-
TCP 协议和 UDP 协议的区别?
答:
TCP 协议和 UDP 协议是网络传输协议,二者的区别主要有以下几点:
① 连接方式:TCP 协议是面向连接的协议,UDP 协议是无连接的协议。
② 可靠性:TCP 协议提供可靠的传输,保证数据的完整性和正确性,而 UDP 协议不保证数据的可靠性,因此传输速度更快。
③ 传输速度:UDP 协议的传输速度比 TCP 协议快,因为它没有建立连接的过程和数据校验的过程。
④ 数据包大小:TCP 协议传输的数据包大小是有限制的,而 UDP 协议可以传输更大的数据包。
⑤ 流量控制:TCP 协议具有流量控制和拥塞控制的功能,可以调整数据的传输速度,而 UDP 协议则没有这个功能。
⑥ 应用场景:TCP 协议适用于需要可靠传输的场景,如文件传输、电子邮件等;UDP 协议适用于实时传输和数据量较小的场景,如音频、视频等。综上所述,TCP 协议和 UDP 协议各有优缺点,根据不同的应用场景选择合适的协议可以提高网络传输效率和数据传输质量。
-
简单说说 TCP 协议的三次握手与四次挥手机制?
答:
TCP 协议的三次握手是指,在建立 TCP 连接时,客户端和服务器双方需要进行三次通信来确认彼此的身份和确认双方的通信能力。具体流程如下:
① 客户端发送一个 SYN 报文给服务器端,表示客户端请求连接。
② 服务器接收到客户端的 SYN 报文后,向客户端发送一个 SYN+ACK 报文,表示服务器已经收到客户端的请求,并请求确认连接。
③ 客户端接收到服务器端的 SYN+ACK 报文后,向服务器端发送一个 ACK 报文,表示客户端已经确认连接,连接建立成功。TCP 协议的四次挥手是指,在关闭 TCP 连接时,客户端和服务器双方需要进行四次通信来关闭连接。具体流程如下:
① 客户端向服务器端发送一个 FIN 报文,表示客户端要关闭连接。
② 服务器接收到客户端的 FIN 报文后,向客户端发送一个 ACK 报文,表示服务器已经接收到客户端的请求,但是服务器还需要一些时间来处理数据。
③ 服务器处理完数据后,向客户端发送一个 FIN 报文,表示服务器也要关闭连接。
④ 客户端接收到服务器端的 FIN 报文后,向服务器端发送一个 ACK 报文,表示客户端已经接收到服务器端的请求,连接关闭成功。
第 17 章 反射机制
17.1 反射的概述
Reflection(反射)是被视为动态语言的关键,反射机制允许程序在运行期间借助于 Reflection API 取得任何类的内部信息,并能直接操作任意对象的内部属性及方法。
加载完类之后,在堆内存的方法区中就产生了一个 Class 类型的对象(一个类只有一个 Class 对象),这个对象就包含了完整的类的结构信息。我们可以通过这个对象看到类的结构。这个对象就像一面镜子,透过这个镜子看到类的结构,所以,我们形象的称之为:反射。
Java 给我们提供了一套 API,使用这套 API 我们可以在运行时动态的获取指定对象所属的类,创建运行时类的对象,调用指定的结构(属性、方法)等。
反射相关的主要 API:
- java.lang.Class:代表一个类。
- java.lang.reflect.Method:代表类的方法。
- java.lang.reflect.Field:代表类的成员变量。
- java.lang.reflect.Constructor:代表类的构造器。
反射的优点和缺点:
- 优点:
- 提高了 Java 程序的灵活性和扩展性,降低了耦合性,提高自适应能力。
- 允许程序创建和控制任何类的对象,无需提前硬编码目标类。
- 缺点:
- 反射的性能较低。
- 反射机制主要应用在对灵活性和扩展性要求很高的系统框架上。
- 反射会模糊程序内部逻辑,可读性较差。
反射,平时开发中,我们使用并不多。主要是在框架的底层使用。
17.2 Class:反射的源头
Class 的理解:
- 针对于编写好的.java 源文件进行编译(使用 javac.exe),会生成一个或多个.class 字节码文件。接着,我们使用 java.exe 命令对指定的.class 文件进行解释运行。这个解释运行的过程中,我们需要将.class 字节码文件加载(使用类的加载器)到内存中(存放在方法区)。加载到内存中的.class 文件对应的结构即为 Class 的一个实例。
Class 本身也是一个类。
Class 对象只能由系统建立对象。
一个加载的类在 JVM 中只会有一个 Class 实例。
一个 Class 对象对应的是一个加载到 JVM 中的一个.class 文件。
每个类的实例都会记得自己是由哪个 Class 实例所生成。
通过 Class 可以完整地得到一个类中的所有被加载的结构。
Class 类是 Reflection 的根源,针对任何你想动态加载、运行的类,唯有先获得相应的 Class 对象。
获取 Class 的实例的几种方式。
- 类.class
- 对象.getClass()
- Class 调用静态方法 forName(String className)
- 使用 ClassLoader 的方法 loadClass(String className)
Class 可以指向哪些结构?
- 简言之,所有 Java 类型。
① class:外部类,成员(成员内部类,静态内部类),局部内部类,匿名内部类
② interface:接口
③ []:数组
④ enum:枚举
⑤ annotation:注解@interface
⑥ primitive type:基本数据类型
⑦ void
17.3 类的加载过程、类的加载器
-
类的加载过程
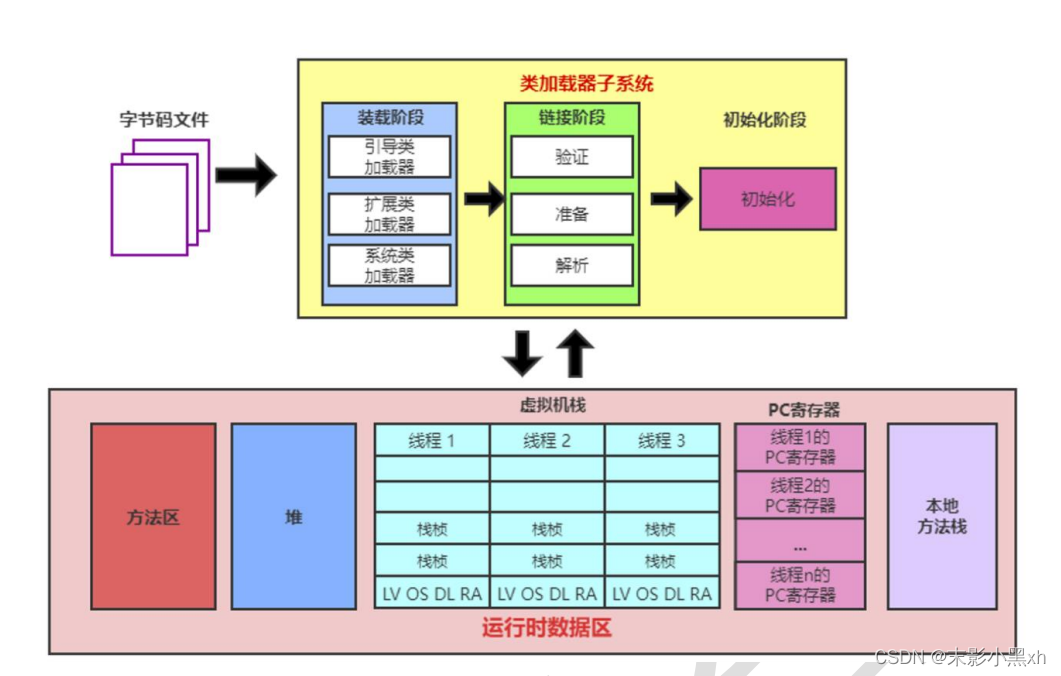
-
过程 1:类的装载(loading)
- 将类的 class 文件读入内存,并为之创建一个 java.lang.Class 对象。此过程由类加载器完成。
-
过程 2:链接(linking)
① 验证(Verify):确保加载的类信息符合 JVM 规范,例如:以 cafebabe 开头,没有安全方面的问题。
② 准备(Prepare):正式为类变量(static)分配内存并设置类变量默认初始值的阶段,这些内存都将在方法区中进行分配。
③ 解析(Resolve):虚拟机常量池内的符号引用(常量名)替换为直接引用(地址)的过程。 -
过程 3:初始化(initialization)
- 执行类构造器
()方法的过程。类构造器 ()方法是由编译期自动收集类中所有类变量的赋值动作和静态代码块中的语句合并产生的。(类构造器是构造类信息的,不是构造该类对象的构造器)。 - 当初始化一个类的时候,如果发现其父类还没有进行初始化,则需要先触发其父类的初始化。
- 虚拟机会保证一个类的
()方法在多线程环境中被正确加锁和同步。
- 执行类构造器
-
-
类的加载器
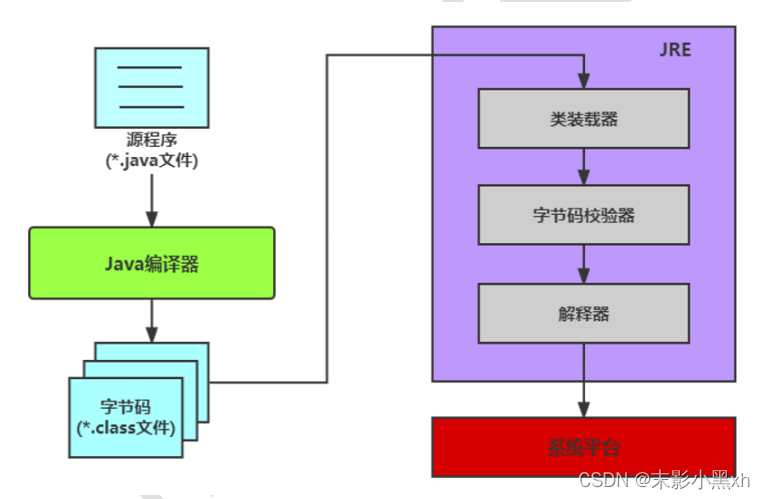
-
作用:负责类的加载,并对应于一个 Class 的实例。
-
分类:
- 启动类加载器(引导类加载器,Bootstrap ClassLoader)
- 使用 C/C++语言编写的,不能通过 Java 代码获取其实例。
- 负责加载 Java 的核心库。(JAVA_HOME/jre/lib/rt.jar 或 sun.boot.class.path 路径下的内容)
- 扩展类加载器(Extension ClassLoader)
- 负责加载从 java.ext.dirs 系统属性所指定的目录中加载类库,或从 JDK 的安装目录的 jre/lib/ext 子目录下加载类库。
- 应用程序类加载器(系统类加载器,AppClassLoader)
- 我们自定义的类,默认使用的类的加载器。
- 用户自定义类的加载器。
- 实现应用的隔离(同一个类在一个应用程序中可以加载多份);数据的加密。
- 启动类加载器(引导类加载器,Bootstrap ClassLoader)
-
17.4 反射的应用 1:创建运行时类的对象
在 Java 中,我们可以通过反射来创建运行时类的对象。具体步骤如下:
① 获取运行时类的 Class 对象,可以使用 Class.forName()方法或者运行时类的.class 属性来获取。
② 使用 Class 对象的 newInstance()方法来创建运行时类的对象。该方法会调用运行时类的无参构造器来创建对象。
③ 如果运行时类没有无参构造器,可以使用 Class 对象的 getConstructor()方法来获取指定参数类型的构造器,然后使用 Constructor 对象的 newInstance()方法来创建运行时类的对象。
代码示例:
1 | public class ReflectDemo |
需要注意的是,使用反射创建对象的效率较低,因为需要通过反射调用构造器来创建对象,而不是直接调用 new 关键字。因此,在实际开发中,应该尽量避免频繁使用反射来创建对象。
17.5 反射的应用 2:获取运行时类所有的结构
在 Java 中,可以使用反射获取运行时类所有的结构,包括类名、父类、接口、构造方法、字段、方法等。以下是一些常用的反射方法:
- 获取类名:
1 | Class<?> clazz = obj.getClass(); |
- 获取父类:
1 | Class<?> superClass = clazz.getSuperclass(); |
- 获取实现的接口:
1 | Class<?>[] interfaces = clazz.getInterfaces(); |
- 获取构造方法:
1 | Constructor<?>[] constructors = clazz.getConstructors(); |
- 获取字段:
1 | Field[] fields = clazz.getFields(); |
- 获取方法:
1 | Method[] methods = clazz.getMethods(); |
通过反射,可以动态地获取运行时类的结构信息,并且可以根据需要进行访问和修改。但是,使用反射也需要谨慎,因为它可能会影响程序的性能和安全性。
17.6 反射的应用 3:调用指定的结构
在 Java 中,可以使用反射调用指定类的方法。首先需要获取该类的 Class 对象,然后通过 Class 对象获取指定方法的 Method 对象,最后通过 Method 对象调用该方法。
代码示例:
1 | public class Person |
以上代码中,首先通过 Class 对象获取构造方法,然后创建一个 Person 对象。然后通过 Class 对象获取 sayHello 方法的 Method 对象,最后通过 Method 对象调用该方法。输出结果为:
1 | Hello, I'm Tom, 20 years old. |
17.7 反射的应用 4:注解的使用
在 Java 语言中,反射是指在运行时动态地获取类的信息并进行操作的能力。注解是一种在程序中添加元数据的方式,它可以在类、方法、字段等元素上添加注释,提供额外的信息。注解的使用可以通过反射来实现。
例如,我们定义了一个注解@MyAnnotation:
1 | public MyAnnotation |
我们可以在程序中使用@MyAnnotation 注解:
1 |
|
在程序运行时,我们可以通过反射获取这个类的注解信息:
1 | Class<MyClass> clazz = MyClass.class; |
通过反射获取注解信息,我们可以根据注解的值来进行不同的操作,例如根据注解值来动态生成代码、修改程序行为等等。
17.8 体会:反射的动态性
-
反射的动态性指的是在程序运行时,可以通过反射机制获取并操作对象的信息,而不需要在编译时就确定对象的类型。这种动态性使得程序具有更大的灵活性和扩展性。
-
例如,我们可以通过反射机制获取一个类的所有方法、属性、构造器等信息,然后动态地创建对象、调用方法、修改属性等。这样就可以在运行时根据需要动态地创建和操作对象,而不需要在编译时就确定对象的类型和行为。
-
反射的动态性也带来了一些挑战和风险,因为在运行时动态创建和操作对象可能会导致一些不可预测的行为和错误。因此,在使用反射机制时需要谨慎考虑其使用场景和限制条件,以确保程序的正确性和稳定性。
-
以下是一个简单的反射示例代码,演示如何通过反射机制获取类的信息并创建对象:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44public class MyClass
{
private int value;
public MyClass(int value)
{
this.value = value;
}
public void setValue(int value)
{
this.value = value;
}
public int getValue()
{
return value;
}
}
public class ReflectionExample
{
public static void main(String[] args) throws Exception
{
// 获取类对象
Class<?> clazz = MyClass.class;
// 获取构造器并创建对象
Constructor<?> constructor = clazz.getConstructor(int.class);
MyClass obj = (MyClass) constructor.newInstance(10);
// 获取方法并调用
Method method = clazz.getMethod("setValue", int.class);
method.invoke(obj, 20);
// 获取属性并修改
Field field = clazz.getDeclaredField("value");
field.setAccessible(true);
field.set(obj, 30);
// 输出结果
System.out.println(obj.getValue()); // 输出30
}
}在上面的示例中,我们首先通过 MyClass.class 获取了该类的类对象 clazz,然后通过 clazz 获取了构造器、方法和属性等信息。接着,我们使用反射机制创建了一个 MyClass 对象 obj,并通过反射调用了 setValue 方法和修改了 value 属性的值。最后,我们输出了 obj 的 value 属性值,结果为 30。
17.9 企业真题
-
对反射了解吗?反射有什么好处?为什么需要反射?
答:
反射是一种程序能够在运行时自我检查和修改自身行为和状态的能力。在 Java 语言中,反射允许程序在运行时获取类的信息,比如类名、方法、属性等,并且可以动态地调用这些方法和属性。反射的好处是它可以使程序更加灵活和可扩展。通过反射,程序可以在运行时动态地加载和使用类,而不需要在编译时就确定类的类型。这使得程序可以根据需要动态地创建对象、调用方法、访问属性等。
反射的另一个好处是它可以帮助程序员编写更加通用和灵活的代码。通过反射,程序员可以编写通用的代码,而不需要针对每个具体的类编写不同的代码。这使得代码更加简洁、易于维护和扩展。
需要反射的主要原因是程序需要在运行时动态地加载和使用类。这通常发生在以下情况下:
① 当程序需要动态地创建对象时,比如根据用户输入的类名创建对象。
② 当程序需要动态地调用方法时,比如根据用户输入的方法名和参数类型调用方法。
③ 当程序需要动态地访问属性时,比如根据用户输入的属性名获取属性值。总之,反射是一种非常有用的技术,可以使程序更加灵活、通用和可扩展。但是,由于反射需要在运行时动态地加载和使用类,所以它可能会影响程序的性能。因此,在使用反射时需要权衡性能和灵活性之间的平衡。
-
反射的使用场合和作用、及其优缺点?
答:
反射是指在运行时动态地获取类的信息并进行操作的能力。它可以在程序运行时动态地获取类或对象的属性、方法、构造函数等信息,并进行操作。反射可以让程序员在不知道类名的情况下,通过字符串来获取类的信息、创建对象、调用方法等。反射在以下场合有很好的应用:
① 框架开发:反射可以在框架开发中使用,例如 Spring 框架中的 IOC 容器就是基于反射实现的。
② 动态代理:反射可以用于动态代理,它可以在运行时动态地创建代理对象,并增加一些额外的功能。
③ 序列化和反序列化:反射可以在序列化和反序列化过程中使用,例如 Java 中的 ObjectInputStream 和 ObjectOutputStream 类就是基于反射实现的。
④ 单元测试:反射可以用于单元测试中,例如 JUnit 框架就是基于反射实现的。反射的优点:
① 反射提供了动态性,可以在运行时获取类的信息,方便进行操作。
② 反射可以实现类似于泛型的功能,可以在编译时不确定类型,在运行时才确定。
③ 反射可以实现一些复杂的功能,例如动态代理、注解处理等。反射的缺点:
① 反射效率较低,反射调用方法和访问属性的效率比直接调用要低。
② 反射容易导致代码不稳定,容易出现一些运行时异常,例如 ClassCastException 等。
③ 反射使用不当会导致安全问题,例如通过反射获取私有属性或方法,破坏了封装性和安全性。 -
实现 Java 反射的类有什么?
答:
实现 Java 反射的类有以下几个:
① Class 类:表示一个类或接口,在运行时可以通过它获取类的信息,如类名、父类、接口、构造方法、成员变量、方法等。
② Constructor 类:表示一个构造方法,在运行时可以通过它创建对象。
③ Method 类:表示一个方法,在运行时可以通过它调用方法。
④ Field 类:表示一个成员变量,在运行时可以通过它获取或设置成员变量的值。
⑤ Modifier 类:表示一个修饰符,在运行时可以通过它获取修饰符的信息,如 public、private、static 等。
⑥ Array 类:表示一个数组,在运行时可以通过它创建数组对象,并获取数组元素的值。 -
反射是怎么实现的?
答:
在 Java 中,反射是通过 Class 类来实现的。每个类在内存中都有一个 Class 对象,该对象包含了类的所有信息,包括类的名称、属性、方法等。通过 Class 类的 newInstance()方法可以动态地创建一个类的实例。通过 Class 类的 getMethod()、getField()、getDeclaredMethod()、getDeclaredField()等方法可以获取类的方法和属性,从而动态地调用方法或修改属性的值。
反射的实现基于 Java 虚拟机的动态加载机制,可以在程序运行时动态地加载和使用类。这种机制使得 Java 程序可以在运行时根据需要加载和使用不同的类,从而实现更加灵活和动态的编程。
-
Class 类的作用?生成 Class 对象的方法有哪些?
答:
Class 类的作用是描述类的结构信息,包括类的属性、方法、构造器等。它是 Java 反射的核心类,通过 Class 类可以获取一个类的信息并操作它的属性和方法。生成 Class 对象的方法主要有三种:
① 调用对象的 getClass()方法:可以通过一个已经存在的对象来获取它所属的类的 Class 对象。
② 使用类的.class 语法:在编译期间就可以确定一个类的 Class 对象,可以直接使用类名.class 来获取。
③ 使用 Class.forName()方法:可以通过类的全限定名来获取 Class 对象,这种方式可以在运行时动态加载类。 -
Class.forName(“全路径”) 会调用哪些方法 ? 会调用构造方法吗?加载的类会放在哪?
答:
Class.forName(“全路径”) 会调用类的静态初始化块(static{})和静态变量的初始化,但不会调用构造方法。加载的类会放在 JVM 的方法区(Method Area)中。 -
类加载流程?
答:
类加载是 Java 虚拟机将类的.class 文件中的二进制数据读入内存中,使其成为方法区内的 Class 对象的过程。类加载的流程包括以下几个步骤:
① 加载:查找并加载类的二进制数据。在此阶段,Java 虚拟机需要完成以下任务:
a. 通过一个类的全限定名获取定义此类的二进制字节流。
b. 将这个字节流所代表的静态存储结构转换为方法区的运行时数据结构。
c. 在内存中生成一个代表这个类的 java.lang.Class 对象,作为方法区这个类的各种数据的访问入口。
② 链接:将类的二进制数据合并到 JVM 的运行状态之中。在此阶段,Java 虚拟机需要完成以下任务:
a. 验证:确保加载的类的正确性。
b. 准备:为类的静态变量分配内存,并设置默认初始值。
c. 解析:将类中的符号引用转换为直接引用。
③ 初始化:为类的静态变量赋予正确的初始值,并执行初始化代码块。在此阶段,Java 虚拟机需要完成以下任务:
a. 执行类构造器()方法的过程。
b. 如果该类还有父类,JVM 会先初始化其父类。以上是类加载的主要流程。需要注意的是,类的加载过程是按需的,即只有在使用时才会进行类的加载。此外,JVM 还提供了一些机制来控制类的加载行为,例如类加载器、双亲委派机制等。
-
说一下创建对象的几种方法?
答:
① 使用 new 关键字创建对象:1
MyClass object = new MyClass();
② 使用 Class 类的 newInstance() 方法创建对象:
1
MyClass object = (MyClass) Class.forName("MyClass").newInstance();
③ 使用 clone() 方法创建对象:
1
MyClass object = (MyClass) oldObject.clone();
④ 使用反序列化创建对象:
1
2ObjectInputStream in = new ObjectInputStream(new FileInputStream("object.ser"));
MyClass object = (MyClass) in.readObject();⑤ 使用工厂方法创建对象:
1
MyClass object = MyClassFactory.createMyClass();
⑥ 使用构造方法引用创建对象:
1
MyClass object = MyClass::new;
-
如何找到对象实际类的?
答:
可以使用 getClass()方法来获取对象实际的类,例如:1
2
3Object obj = new String("Hello");
Class<?> cls = obj.getClass();
System.out.println(cls.getName());输出结果为:java.lang.String
-
Java 反射创建对象效率高还是通过 new 创建对象的效率高?
答:
在创建对象方面,通过 new 创建对象的效率要高于 Java 反射创建对象。这是因为 Java 反射创建对象需要进行额外的操作,在运行时需要进行类的加载、方法的调用等操作,这些都会消耗一定的时间,因此相对于直接通过 new 创建对象,Java 反射创建对象的效率会稍微慢一些。
但是,Java 反射创建对象也具有其独特的优点,比如可以在运行时动态地创建对象、调用方法等,这对于某些特定的场景是非常有用的。因此,在具体实现中需要根据实际情况进行选择。
-
如何利用反射机制来访问一个类的方法?
答:
可以通过以下步骤来利用反射机制访问一个类的方法:
① 获取该类的 Class 对象,可以通过 Class.forName()方法或者类名.class 来获取。
② 获取指定方法的 Method 对象,可以通过 Class 对象的 getMethod()方法或者 getDeclaredMethod()方法来获取。
③ 调用 Method 对象的 invoke()方法来执行该方法,需要传入该方法所属的对象和方法参数。示例代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21// 获取类的Class对象
Class<?> clazz = MyClass.class;
try
{
// 获取指定方法的Method对象
Method method = clazz.getMethod("methodName", int.class, String.class);
// 创建该方法所属的对象
MyClass obj = new MyClass();
// 调用方法
Object result = method.invoke(obj, 123, "abc");
// 输出方法返回值
System.out.println(result);
}
catch (Exception e)
{
e.printStackTrace();
} -
说一下 Java 反射获取私有属性,如何改变值?
答:
Java 反射可以通过 getDeclaredField()方法获取私有属性,并通过 setAccessible(true)方法设置访问权限,最终通过 set()方法修改值。示例代码如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20public class MyClass
{
private int myPrivateField = 10;
}
public class Main
{
public static void main(String[] args) throws Exception
{
MyClass obj = new MyClass();
Field privateField = MyClass.class.getDeclaredField("myPrivateField");
privateField.setAccessible(true);
int newValue = 20;
privateField.set(obj, newValue);
System.out.println(obj.myPrivateField);
}
}上述代码中,我们使用反射获取了 MyClass 类中的私有属性 myPrivateField,并设置了访问权限。然后通过 set()方法将其值修改为 20,并打印出结果。
需要注意的是,在 JDK17 中,内部的私有结构已经不再支持反射调用。这是因为 Java 官方认为这种调用方式可能会导致安全问题。因此,我们需要在编写代码时避免使用这种方法。
第 18 章 JDK8 到 JDK17 新特性
18.1 JDK 新特性的概述
-
几个重要的版本:
- jdk 5.0、jdk 8.0:里程碑式的版本。
- jdk 9.0 开始每 6 个月发布一个新的版本。
- LTS(长期支持版本): jdk8、jdk 11、jdk 17。
-
如何学习新特性?
- 角度 1:新的语法规则
- 自动装箱、自动拆箱、enum、泛型、Lambda 表达式、接口中的默认方法、静态方法、局部变量的类型推断、switch 表达式、文本块等。
- 角度 2:增加、过时、删除 API - Stream、Optional、新的日期时间的 API、HashMap 的底层结构、String 的底层结构
等。 - 角度 3:底层的优化、内存结构(永久代——>元空间)、新的 JS 执行引擎、新的垃圾回收器、GC 参数、JVM 的优化。
- 角度 1:新的语法规则
18.2 JDK8:lambda 表达式
在给函数式接口提供实例时,都可以考虑使用 lambda 表达式。
基本语法的使用:
- Lambda 表达式:在 Java 8 语言中引入的一种新的语法元素和操作符。这个操作符为 “->” , 该操作符被称为 Lambda 操作符或箭头操作符。它将 Lambda 分为两个部分:
- 左侧:指定了 Lambda 表达式需要的参数列表。
- 右侧:指定了 Lambda 体,是抽象方法的实现逻辑,也即 Lambda 表达式要执行的功能。
下面是一个使用 lambda 表达式的简单代码示例:
1 | import java.util.ArrayList; |
在上面的示例中,我们使用了 lambda 表达式来遍历 List、对 List 进行排序以及过滤 List 中的元素。在遍历 List 时,我们使用了 forEach()方法,该方法接受一个 Consumer 接口作为参数,该接口中定义了一个 accept()方法,用于处理每个元素。在排序 List 时,我们使用了 sort()方法,该方法接受一个 Comparator 接口作为参数,该接口中定义了一个 compare()方法,用于比较两个元素的大小关系。在过滤 List 时,我们使用了 stream()方法和 filter()方法,这两个方法都接受一个 Predicate 接口作为参数,该接口中定义了一个 test()方法,用于判断元素是否符合条件。
18.3 函数式接口
只包含一个抽象方法(Single Abstract Method,简称 SAM)的接口,称为函数式接口。当然该接口可以包含其他非抽象方法。
可以通过 Lambda 表达式来创建该接口的对象。(若 Lambda 表达式抛出一个受检异常(即:非运行时异常),那么该异常需要在目标接口的抽象方法上进行声明)。
我们可以在一个接口上使用 @FunctionalInterface 注解,这样做可以检查它是否是一个函数式接口。同时 javadoc 也会包含一条声明,说明这个接口是一个函数式接口。
在 java.util.function 包下定义了 Java 8 的丰富的函数式接口。
-
常见的函数式接口。Comparator、Runnable、java.util.function 下定义的丰富的函数式接口。
- 消费型接口:Consumer
void accept(T t) - 供给型接口:Supplier
T get() - 函数型接口:Function<T,R> R apply(T t)
- 判断型接口:Predicate
boolean test(T t)
- 消费型接口:Consumer
-
消费型接口示例:将字符串转为大写输出。
1
2Consumer<String> consumer = str -> System.out.println(str.toUpperCase());
consumer.accept("hello world"); -
供给型接口示例:生成一个随机数。
1
2Supplier<Integer> supplier = () -> (int) (Math.random() * 100);
int num = supplier.get(); -
函数型接口示例:将字符串转为整型并乘以 2。
1
2Function<String, Integer> function = str -> Integer.parseInt(str) * 2;
int result = function.apply("10"); -
判断型接口示例:判断字符串是否为空。
1
2Predicate<String> predicate = str -> str == null || str.isEmpty();
boolean isEmpty = predicate.test("");
18.4 方法引用、构造器引用、数组引用
方法引用、构造器引用、数组引用:看做是 lambda 表达式的进一步凝练。
方法引用格式:
- 格式:使用方法引用操作符 “::” 将类(或对象) 与 方法名分隔开来。
- 两个:中间不能有空格,而且必须英文状态下半角输入。
如下三种主要使用情况:
- 情况 1:对象 :: 实例方法名
- 情况 2:类 :: 静态方法名
- 情况 3:类 :: 实例方法名
方法引用使用前提:
-
要求 1:Lambda 体只有一句语句,并且是通过调用一个对象的类现有的方法来完成的。
- 例如:System.out 对象,调用 println()方法来完成 Lambda 体
Math 类,调用 random()静态方法来完成 Lambda 体
- 例如:System.out 对象,调用 println()方法来完成 Lambda 体
-
要求 2:
- 针对情况 1:函数式接口中的抽象方法 a 在被重写时使用了某一个对象的方法 b。如果方法 a 的形参列表、返回值类型与方法 b 的形参列表、返回值类型都相同,则我们可以使用方法 b 实现对方法 a 的重写、替换。
- 针对情况 2:函数式接口中的抽象方法 a 在被重写时使用了某一个类的静态方法 b。如果方法 a 的形参列表、返回值类型与方法 b 的形参列表、返回值类型都相同,则我们可以使用方法 b 实现对方法 a 的重写、替换。
- 针对情况 3:函数式接口中的抽象方法 a 在被重写时使用了某一个对象的方法 b。如果方法 a 的返回值类型与方法 b 的返回值类型相同,同时方法 a 的形参列表中有 n 个参数,方法 b 的形参列表有 n-1 个参数,且方法 a 的第 1 个参数作为方法 b 的调用者,且方法 a 的后 n-1 参数与方法 b 的 n-1 参数匹配(类型相同或满足多态场景也可以)
例如:
t->System.out.println(t)
() -> Math.random() 都是无参。
-
方法引用代码示例:
① 静态方法引用1
2
3
4
5
6
7
8
9
10
11
12
13public class Main
{
public static void main(String[] args)
{
List<String> list = Arrays.asList("apple", "banana", "orange");
list.forEach(Main::print); // 静态方法引用
}
public static void print(String str)
{
System.out.println(str);
}
}② 实例方法引用
1
2
3
4
5
6
7
8
9
10
11
12
13
14public class Main
{
public static void main(String[] args)
{
List<String> list = Arrays.asList("apple", "banana", "orange");
Main main = new Main();
list.forEach(main::print); // 实例方法引用
}
public void print(String str)
{
System.out.println(str);
}
}③ 对象方法引用
1
2
3
4
5
6
7
8public class Main
{
public static void main(String[] args)
{
List<String> list = Arrays.asList("apple", "banana", "orange");
list.forEach(String::toUpperCase); // 对象方法引用
}
} -
构造器引用示例:
① 无参构造器引用1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16public class Main
{
public static void main(String[] args)
{
Supplier<Person> supplier = Person::new; // 无参构造器引用
Person person = supplier.get();
}
}
class Person
{
public Person()
{
System.out.println("Create a person.");
}
}② 有参构造器引用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public class Main
{
public static void main(String[] args)
{
BiFunction<String, Integer, Person> function = Person::new; // 有参构造器引用
Person person = function.apply("Tom", 20);
}
}
class Person
{
private String name;
private int age;
public Person(String name, int age)
{
this.name = name;
this.age = age;
System.out.println("Create a person: " + name + ", " + age);
}
} -
数组引用示例:
1
2
3
4
5
6
7
8public class Main
{
public static void main(String[] args)
{
Function<Integer, int[]> function = int[]::new; // 数组引用
int[] array = function.apply(10);
}
}
18.5 JDK8:Stream API
Java8 中有两大最为重要的改变。第一个是 Lambda 表达式;另外一个则是 Stream API。
Stream API ( java.util.stream) 把真正的函数式编程风格引入到 Java 中。这是目前为止对 Java 类库最好的补充,因为 Stream API 可以极大提供 Java 程序员的生产力,让程序员写出高效率、干净、简洁的代码。
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。 使用 Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。也可以使用 Stream API 来并行执行操作。简言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
Stream 和 Collection 集合的区别:Collection 是一种静态的内存数据结构,讲的是数据,而 Stream 是有关计算的,讲的是计算。前者是主要面向内存,存储在内存中,后者主要是面向 CPU,通过 CPU 实现计算。
注意:
① Stream 自己不会存储元素。
② Stream 不会改变源对象。相反,他们会返回一个持有结果的新 Stream。
③ Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。即一旦执行终止操作,就执行中间操作链,并产生结果。
④ Stream 一旦执行了终止操作,就不能再调用其它中间操作或终止操作了。
Stream 的操作三个步骤:
- 创建 Stream 一个数据源(如:集合、数组),获取一个流。
- 中间操作 每次处理都会返回一个持有结果的新 Stream,即中间操作的方法返回值仍然是 Stream 类型的对象。因此中间操作可以是个操作链,可对数据源的数据进行 n 次处理,但是在终结操作前,并不会真正执行。
- 终止操作(终端操作) 终止操作的方法返回值类型就不再是 Stream 了,因此一旦执行终止操作,就结束整个 Stream 操作了。一旦执行终止操作,就执行中间操作链,最终产生结果并结束 Stream。
以下是一个简单的代码示例,展示了如何使用 Java 8 的 Stream API 从列表中过滤和映射数据:
1 | import java.util.Arrays; |
输出:
1 | Filtered names: [John, Sarah, Mark, Mary] |
代码解释:
① 首先,我们创建了一个字符串列表 names,其中包含了一些名字。
② 我们使用 stream()方法将列表转换为一个流。
③ 然后,我们使用 filter()方法过滤出名字长度大于等于 4 的人,并将结果收集到一个新列表中。
④ 接下来,我们使用 map()方法将所有名字转换为小写,并将结果收集到一个新列表中。
⑤ 最后,我们打印出过滤后的名字列表和所有名字的小写列表。
这个示例只是 Stream API 功能的冰山一角,Stream API 还有很多其他有用的方法,例如 distinct()、sorted()、limit()和 reduce()等等。
18.6 JDK8 之后的新特性:语法层面
-
jShell 工具:
- Java 终于拥有了像 Python 和 Scala 之类语言的 REPL 工具(交互式编程环境,read - evaluate - print - loop):jShell。以交互式的方式对语句和表达式进行求值。即写即得、快速运行。
- 利用 jShell 在没有创建类的情况下,在命令行里直接声明变量,计算表达式,执行语句。无需跟人解释”public static void main(String[] args)”这句"废话"。
-
try-catch 结构的变化:
-
在 try 的后面可以增加一个(),在括号中可以声明流对象并初始化。try 中的代码执行完毕,会自动把流对象释放,就不用写 finally 了。
-
语法格式:
1
2
3
4
5
6
7
8
9
10
11
12try(资源对象的声明和初始化)
{
业务逻辑代码,可能会产生异常
}
catch(异常类型 1 e)
{
处理异常代码
}
catch(异常类型 2 e)
{
处理异常代码
}
-
-
局部变量的类型推断:var
-
instanceof 的模式匹配:
-
instanceof 模式匹配通过提供更为简便的语法,来提高生产力。有了该功能,可以减少 Java 程序中显式强制转换的数量,实现更精确、简洁的类型安全的代码。
-
Java 14 之前旧写法:
1
2
3
4
5
6
7
8
9if(obj instanceof String)
{
String str = (String)obj; //需要强转
}
else
{
} -
Java 14 新特性写法:
1
2
3
4
5
6
7
8if(obj instanceof String str)
{
}
else
{
}
-
-
switch 的模式匹配:
-
switch 语句是一种选择结构,通常用于根据一个表达式的值来决定程序的执行流程。在 Java 中,switch 语句可以使用模式匹配来匹配多个值。
-
下面是一个简单的代码示例,展示了如何使用 switch 语句的模式匹配功能:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15public class SwitchExample
{
public static void main(String[] args)
{
int num = 1;
switch (num)
{
// num为switch语句的表达式
case 1 -> System.out.println("One"); // 如果num等于1,则执行此分支
case 2 -> System.out.println("Two"); // 如果num等于2,则执行此分支
case 3 -> System.out.println("Three"); // 如果num等于3,则执行此分支
default -> System.out.println("Other"); // 如果num不匹配任何一个case分支,则执行此分支
}
}
}上面的代码中,我们使用了 Java 14 中的新特性-箭头表达式,可以更简洁的书写代码,效果与 Java 12 中的 switch 表达式相同。
在这个示例中,我们定义了一个整型变量 num,并使用 switch 语句对它进行匹配。在每个 case 分支中,我们使用箭头表达式输出不同的值。如果 num 的值不匹配任何一个 case 分支,程序将执行 default 分支。
-
-
文本块:
-
在 Java 13 及以上版本中,可以使用文本块来更方便地处理多行文本。文本块的格式为三个双引号(“”")开始,三个双引号结束,中间可以插入多行文本。
-
下面是一个详细的代码示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public class TextBlockExample
{
public static void main(String[] args)
{
// 定义一个文本块
String textBlock = """
Hello,
This is a text block.
It can span multiple lines.
""";
// 输出文本块
System.out.println(textBlock);
// 可以在文本块中使用双引号和换行符
String textBlockWithQuoteAndNewLine = """
"Hello," she said.
This is a text block.
It can span multiple lines.
""";
// 输出带有双引号和换行符的文本块
System.out.println(textBlockWithQuoteAndNewLine);
// 可以在文本块中插入表达式
String name = "Tom";
String textBlockWithExpression = """
Hello, %s.
This is a text block.
It can span multiple lines.
""".formatted(name);
// 输出带有表达式的文本块
System.out.println(textBlockWithExpression);
}
}输出结果:
1
2
3
4
5
6
7
8
9
10
11Hello,
This is a text block.
It can span multiple lines.
"Hello," she said.
This is a text block.
It can span multiple lines.
Hello, Tom.
This is a text block.
It can span multiple lines.在文本块中,可以使用反斜杠(\)来转义双引号、换行符等特殊字符。如果要在文本块中插入美元符号($),需要使用两个美元符号来转义。例如:
1
2
3
4
5
6
7String textBlockWithEscape = """
"Hello,\" she said."
This is a text block.
It can span multiple lines.
This is a variable: $$
""";
System.out.println(textBlockWithEscape);输出结果:
1
2
3
4"Hello," she said."
This is a text block.
It can span multiple lines.
This is a variable: $
-
-
新的引用数据类型:record (记录)
-
在 Java 16 中,引入了一种新的引用数据类型:record。record 是一种不可变的类,用于表示数据记录。它提供了一个简单的方法来定义一个类,该类包含一组属性和一些实用方法。
-
以下是一个简单的 record 代码示例:
1
2
3
4public record Person(String name, int age)
{
// 构造器、获取方法和其他方法
}这个 record 定义了一个名为 Person 的类,它有两个属性:name 和 age。它还提供了一个构造函数和两个访问器方法:getName()和 getAge()。这些方法都是自动生成的,因为 record 是不可变的,所以不需要 setter 方法。
-
以下是一个更详细的示例,它展示了如何使用 record 来定义一个学生类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43public record Student(String name, int age, String major, double gpa)
{
// 构造器
public Student
{
if (age < 0 || gpa < 0 || gpa > 4.0)
{
throw new IllegalArgumentException("Invalid age or GPA");
}
}
// 获取方法
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
public String getMajor()
{
return major;
}
public double getGpa()
{
return gpa;
}
// 其他方法
public boolean isHonors()
{
return gpa >= 3.5;
}
public String toString()
{
return name + " (" + age + ") - " + major + ", GPA: " + gpa;
}
}这个 record 定义了一个名为 Student 的类,它有四个属性:name、age、major 和 gpa。它还提供了一个构造函数,该函数检查年龄和 GPA 是否有效。它还提供了访问器方法和其他方法,例如 isHonors()和 toString()。
使用 record 可以使代码更简洁,更易于阅读和维护。它还可以提高代码的性能,因为它是不可变的,所以可以避免同步问题。
-
-
密封类:sealed class
-
密封类(sealed class)是一种特殊的类,它可以被继承,但是只能在定义的文件中被继承,不能在其他文件中被继承。密封类常用于表示有限数量的类型,例如枚举类型。
-
下面是一个 Java 中密封类的详细代码示例和注释:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55// 定义一个密封类Animal
public sealed class Animal permits Dog, Cat, Bird
{
// 定义一个抽象方法makeSound,所有子类都必须实现该方法
public abstract void makeSound();
}
// 定义一个继承自Animal的子类Dog
public final class Dog extends Animal
{
// 实现makeSound方法
public void makeSound()
{
System.out.println("Woof!");
}
}
// 定义一个继承自Animal的子类Cat
public final class Cat extends Animal
{
// 实现makeSound方法
public void makeSound()
{
System.out.println("Meow!");
}
}
// 定义一个继承自Animal的子类Bird
public final class Bird extends Animal
{
// 实现makeSound方法
public void makeSound()
{
System.out.println("Chirp!");
}
}
// 定义一个测试类
public class Test
{
public static void main(String[] args)
{
// 创建一个Dog对象并调用makeSound方法
Animal animal1 = new Dog();
animal1.makeSound(); // 输出Woof!
// 创建一个Cat对象并调用makeSound方法
Animal animal2 = new Cat();
animal2.makeSound(); // 输出Meow!
// 创建一个Bird对象并调用makeSound方法
Animal animal3 = new Bird();
animal3.makeSound(); // 输出Chirp!
}
}在上面的代码中,我们定义了一个密封类 Animal,它有三个子类:Dog、Cat 和 Bird。每个子类都必须实现 Animal 类中定义的抽象方法 makeSound。在测试类中,我们创建了三个 Animal 对象,并分别调用它们的 makeSound 方法,输出了它们各自的声音。
-
18.7. JDK8 之后的新特性:Optional API
Optional 类是 Java 8 中引入的一个新特性,用于解决空指针异常的问题。Optional 类可以包含一个非空的对象,也可以表示一个空对象。它可以用于返回值、方法参数、变量等等,以避免空指针异常的发生。
下面是一个使用 Optional 类的代码示例:
1 | import java.util.Optional; |
在上面的示例代码中,我们创建了一个非空的 Optional 对象和一个空的 Optional 对象。我们使用 isPresent 方法来判断 Optional 对象是否为空,使用 get 方法来获取 Optional 对象中的值。我们使用 orElse 方法来获取 Optional 对象中的值,如果 Optional 对象为空,则返回指定的默认值。我们使用 ifPresent 方法来执行操作,如果 Optional 对象为空,则不执行任何操作。我们使用 map 方法来将 Optional 对象中的值转换成另一个值。
18.8 企业真题
-
谈谈 java8 新特性?
答:
Java 8 引入了很多新特性,其中最重要的包括:
① Lambda 表达式:Lambda 表达式是一种简洁的语法,用于表示可传递的函数式接口。它可以使代码更加简洁、易读、易维护。
② 方法引用:方法引用是一种简洁的语法,用于表示已经存在的方法的引用。它可以使代码更加简洁、易读、易维护。
③ Stream API:Stream API 是一种新的 API,用于处理集合数据。它可以使代码更加简洁、易读、易维护。
④ 接口默认方法:接口默认方法是在接口中定义的具有默认实现的方法。它可以使接口更加灵活、易扩展。
⑤ 函数式接口:函数式接口是只有一个抽象方法的接口。它可以用于 Lambda 表达式和方法引用。
⑥ Optional 类:Optional 类是代表一个可能存在的值或不存在的值的容器类。它可以用于避免空指针异常。
⑦ Date/Time API:Date/Time API 是一个新的 API,用于处理日期和时间。它可以使日期和时间的处理更加简单、易读、易维护。
⑧ Nashorn JavaScript 引擎:Nashorn JavaScript 引擎是一种新的 JavaScript 引擎,用于在 Java 应用程序中执行 JavaScript 代码。它可以使 Java 应用程序更加灵活、易扩展。 -
JDK1.8 在数据结构上发生了哪些变化 ?
答:
JDK1.8 在数据结构上发生了以下变化:
① 元空间替代永久代:在 JDK1.8 中,永久代被元空间替代。元空间是一块本地内存区域,与堆内存分离,用于存储类的元数据信息。这样可以避免永久代的内存溢出问题,并且可以动态地调整元空间大小。
② HashMap 底层结构:在 JDK1.8 中,HashMap 的底层结构发生了变化。在之前的版本中,HashMap 使用数组+链表的方式实现,但是在 JDK1.8 中,当链表长度达到一定阈值(默认为 8)时,会将链表转化为红黑树,提高了查找效率。除此之外,JDK1.8 还引入了一些新的数据结构,如 ConcurrentHashMap 的分段锁机制、Stream API 等,以提高程序的性能和可读性。
-
你说的了解 Java 的新特性 ,你说说 JDK8 改进的地方?
答:
JDK8 改进的地方包括:
① Lambda 表达式:Lambda 表达式是一种简洁的语法,可以实现函数式编程,提高了代码的可读性和简洁性。
② Stream API:Stream API 是一种处理集合数据的新方式,可以实现更加简洁高效的数据处理。
③ 接口的默认方法:接口的默认方法可以在不破坏原有实现的情况下,为接口添加新的方法。
④ 时间日期 API:新的时间日期 API 提供了更加丰富和易用的时间日期处理功能。
⑤ 方法引用:方法引用可以让代码更加简洁,提高可读性。
⑥ 并行流:并行流可以利用多核处理器的优势,提高集合数据的处理效率。
⑦ 重复注解:重复注解可以让同一个注解在同一个元素上出现多次,增加了灵活性。
⑧ Type Annotations:Type Annotations 可以在更加精细的层次上注解类型,提高了代码的可读性和可维护性。 -
JDK1.8 用的是哪个垃圾回收器?
答:
JDK1.8 默认使用的是 Parallel GC(并行垃圾回收器)。随着计算机硬件的不断进步和应用场景的多样化,垃圾回收器也在不断地发展和优化。从 Parallel GC 到 G1GC 再到 ZGC,Java 垃圾回收器的发展方向大致可以归纳为以下几个方面:
① 并行化:Parallel GC 是一种以并行方式进行垃圾回收的垃圾回收器。它通过将内存分割成多个区域,然后在多个线程中同时进行垃圾回收,从而提高了回收效率。在多核 CPU 的环境下,Parallel GC 表现出色,可以有效地利用多核处理器的优势。
② 低延迟:G1GC(G1 垃圾回收器)是一种低延迟垃圾回收器。它采用了基于区域的内存管理方式,可以在不影响应用程序性能的情况下,实现更加精细的内存管理和垃圾回收。G1GC 还具备自适应的垃圾回收策略,可以根据应用程序的实际情况,自动调整垃圾回收的时间和频率。
③ 大内存支持:ZGC(Z 垃圾回收器)是一种专门针对大内存场景的垃圾回收器。它可以在数十 GB、甚至数百 GB 级别的堆内存上进行垃圾回收,而且不会出现明显的停顿。ZGC 采用了柔性化的垃圾回收策略,可以在不同的内存使用情况下,自动调整垃圾回收的时间和方式。总的来说,Java 垃圾回收器的发展方向是趋向于并行化、低延迟和大内存支持。随着计算机硬件的不断升级,垃圾回收器的性能和功能也会不断提高,为 Java 应用程序提供更加优秀的性能和稳定性。
-
Lambda 表达式有了解吗,说说如何使用的?
答:
我了解 Lambda 表达式的概念和用法。Lambda 表达式是 Java 8 引入的一种新特性,用于简化函数式编程的语法。它可以将函数作为参数传递,也可以将函数作为返回值。Lambda 表达式的语法如下:
1
(parameters) -> expression
或者
1
(parameters) -> { statements; }
其中,parameters 是函数的参数列表,expression 是函数的返回值,statements 是函数体。Lambda 表达式可以用在函数式接口中,函数式接口是只有一个抽象方法的接口。Lambda 表达式可以使用 Java 中的函数式接口,例如 Java.util.function 包中的接口,如 Consumer、Function、Predicate 等。
举个例子,下面是一个使用 Lambda 表达式的示例代码:
1
2List<String> names = Arrays.asList("Alice", "Bob", "Charlie");
names.forEach(name -> System.out.println(name));上述代码使用了 forEach 方法和 Lambda 表达式,遍历了一个字符串列表并打印了每个字符串的值。
-
什么是函数式接口?有几种函数式接口?
答:
函数式接口是只包含一个抽象方法的接口。在 Java 8 中引入了函数式接口的概念,以支持 Lambda 表达式和方法引用。函数式接口的一个重要特点是可以通过 Lambda 表达式或方法引用来创建其实例。Java 8 中提供了一些常用的函数式接口,包括:
① Consumer:消费型接口,接受一个参数,无返回值。
② Supplier:供给型接口,不接受任何参数,返回一个值。
③ Function<T, R>:函数型接口,接受一个参数,返回一个值。
④ Predicate:判断型接口,接受一个参数,返回一个布尔值。 除了这些常用的函数式接口之外,Java 8 还提供了一些其他的函数式接口,如 BiFunction、UnaryOperator、BinaryOperator 等。这些函数式接口可以帮助开发人员更方便地使用 Lambda 表达式和方法引用。
-
创建 Stream 的方式?
答:
Java 中创建 Stream 的方式有以下几种:
① 通过集合创建 Stream:可以使用 Collection 接口提供的 stream()方法或 parallelStream()方法来创建 Stream。
② 通过数组创建 Stream:可以使用 Arrays 类提供的 stream()方法来创建 Stream。
③ 通过 Stream.of()方法创建 Stream:可以使用 Stream.of()方法创建包含任意数量元素的 Stream。
④ 通过 Stream.iterate()方法创建 Stream:可以使用 Stream.iterate()方法创建一个包含无限元素的 Stream。
⑤ 通过 Stream.generate()方法创建 Stream:可以使用 Stream.generate()方法创建一个包含无限元素的 Stream。
⑥ 通过 BufferedReader.lines()方法创建 Stream:可以使用 BufferedReader.lines()方法创建一个包含文件中所有行的 Stream。以上是创建 Stream 的几种方式,可以根据具体的需求选择最合适的方式。
-
你讲讲 stream 表达式是咋用的,干啥的?
答:
Stream 表达式是 Java 8 中引入的一种新特性,它提供了一种流式处理数据的方式,可以用来操作集合、数组等数据结构。通过 Stream,我们可以使用类似于 SQL 的语法来对数据进行过滤、排序、映射等操作,大大简化了代码的编写和维护。具体来说,Stream 表达式可以通过以下步骤来使用:
① 获取一个数据源,比如一个集合。
② 对数据源进行过滤、排序、映射等操作,生成一个新的 Stream。
③ 对新生成的 Stream 进行聚合操作,如求和、取最大值等。
④ 最终生成一个结果。Stream 表达式的好处在于它可以大大简化代码的编写和维护,同时也可以提高代码的可读性和可维护性。例如,使用 Stream 表达式可以将一些复杂的操作链式化,从而减少了代码的嵌套层次,使得代码更加简洁易懂。
总之,Stream 表达式是一种强大的工具,可以帮助 Java 后端开发工程师更加高效地处理数据。
-
集合用 Stream 流怎么实现过滤?
答:
可以使用 Stream 的 filter() 方法来实现集合的过滤。例如,假设有一个 List类型的集合,我们可以通过以下代码实现对集合中所有长度大于等于 5 的元素进行过滤: 1
2
3
4
5List<String> list = Arrays.asList("apple", "banana", "orange", "pear", "grape");
List<String> filteredList = list.stream()
.filter(s -> s.length() >= 5)
.collect(Collectors.toList());在上面的代码中,我们首先将 List 转换为 Stream,然后使用 filter() 方法对元素进行过滤,最后使用 collect() 方法将过滤后的元素收集到一个新的 List 中。
-
用 Stream 怎么选出 List 里想要的数据?
答:
使用 Stream 可以通过 filter 方法来筛选出 List 中想要的数据,示例代码如下:1
2
3
4
5List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
List<Integer> filteredNumbers = numbers.stream()
.filter(n -> n % 2 == 0)
.collect(Collectors.toList());
System.out.println(filteredNumbers); // 输出 [2, 4]在上述代码中,我们先定义了一个包含数字的 List,然后使用 stream()方法将其转换为一个 Stream 对象。接着使用 filter()方法对 Stream 中的元素进行筛选,筛选条件为 n % 2 == 0,即只选择偶数。最后使用 collect()方法将筛选出来的元素收集到一个新的 List 中。
-
说说 JDK15、JDK16、JDK17 中的新特性都有什么?
答:
以下是 JDK 15、JDK 16 和 JDK 17 中的一些主要新特性。请注意,这不是一个详尽无遗的列表,而仅仅是重要特性的概述。-
JDK 15(2020 年 9 月发布)
① JEP 339: Edwards-Curve 数字签名算法 (EdDSA):提供了一个新的签名方案,支持高性能且更安全的加密。
② JEP 360: 封装类(Sealed Classes,预览):允许开发者限制某个类或接口的扩展,从而可以更清晰地表示其设计意图。
③ JEP 371: 隐藏类(Hidden Classes):允许在运行时生成类,并确保它们不会与其他类相互干扰,有助于框架的设计与实现。
④ JEP 372: 移除 Applet API:由于 Java Web Start 和相关浏览器插件已被废弃,因此移除了 Applet API。
⑤ JEP 378: 文本块(第二次预览):简化多行字符串字面量的编写,使代码更易读。 -
JDK 16(2021 年 3 月发布)
① JEP 338: 向量 API (Incubator):引入了一个新的向量 API,以提高硬件加速计算的性能。
② JEP 389: 外部内存访问 API (Incubator):提供了一种新的 API,用于访问不受 JVM 直接管理的内存,以提高性能和简化原生内存访问。
③ JEP 390: 警告使用不稳定的值类型:警告开发者使用值类型时可能遇到的潜在问题。
④ JEP 392: 将 JEP 389 的外部内存访问 API 引入 JDK 16,并将其作为一个孵化器模块发布。
⑤ JEP 393: 覆盖记录类的默认方法:允许在记录类中覆盖 equals()、hashCode() 和 toString() 等默认方法。
⑥ JEP 394: 模式匹配实例(第二次预览):引入了模式匹配和 instanceof 运算符的结合,简化了类型检查和类型转换的代码。 -
JDK 17(2021 年 9 月发布)
① JEP 356: 增强伪随机数生成器(PRNG)API:改进了伪随机数生成器,包括性能提升和更简洁的 API。
② JEP 382: 新 macOS 渲染管道:为 macOS 提供了一个新的 Metal 渲染管道,以替代已废弃的 Quartz 渲染管道。
③ JEP 389: 外部内存访问 API(第二次孵化):对在 JDK 16 中引入的外部内存访问 API 进行了改进。
④ JEP 411: 废弃实验性的 AOT 和 JIT 编译器:废弃了实验性的 ahead-of-time 编译器和 just-in-time 编译器。
⑤ JEP 391: macOS/AArch64 端口:为 macOS 上的 ARM64 架构提供了一个原生端口。
⑥ JEP 390: 警告使用不稳定的值类型:警告开发者使用值类型时可能遇到的潜在问题。
⑦ JEP 395: 封装类和接口(正式版):正式引入了 JDK 15 预览版中的封装类和接口特性。
⑧ JEP 398: 移除 Applet API:正式从 JDK 中移除已废弃的 Applet API。
这些新特性在不同程度上改进了 Java 的性能、安全性、易用性和功能。请务必查阅 JDK 发行说明以获取更详细的信息和其他较小的改进。
-